
I’ve previously written code to conduct Aoristic analysis in SPSS. Since this reaches about an N of three crime analysts (if that even), I created an Excel spreadsheet to do the calculations for both the hour of the day and the day of the week in one go.
Note if you simply want within day analysis, Joseph Glover has a nice spreadsheet with VBA functions to accomplish that. But here I provide analysis for both the hour of the day and the day of the week. Here is the spreadsheet and some notes, and I will walk through using the spreadsheet below.
First off, you need your data in Excel to be BeginDateTime and EndDateTime — you cannot have the dates and times in separate fields. If you do have them in separate fields, if they are formatting correctly you can simply add your date field to your hour field. If you have the times in three separate date, hour, and minute fields, you can do a formula like =DATE + HOUR/24 + MINUTE/(60*24) to create the combined datetime field in Excel (excel stores a single date as one integer).
Presumably at this stage you should fix your data if it has errors. Do you have missing begin/end times? Some police databases when there is an exact time treat the end date time as missing — you will want to fix that before using this spreadsheet. I constructed the spreadsheet so it will ignore missing cells, as well as begin datetimes that occur after the end datetime.
So once your begin and end times are correctly set up, you can copy paste your dates into my Aoristic_HourWeekday.xlsx excel spreadsheet to do the aoristic calculations. If following along with my data I posted, go ahead and open up the two excel files in the zip file. In the Arlington_Burgs.xlsx data select the B2 cell.
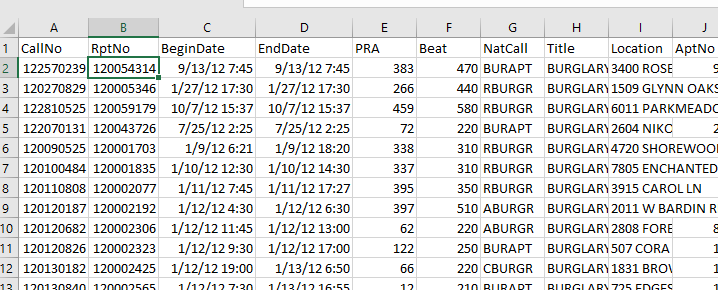
Then scroll down to the bottom of the sheet, hold Shift, and then select the D3269 cell. That should highlight all of the data you need. Right-click, and the select Copy (or simply Ctrl + C).
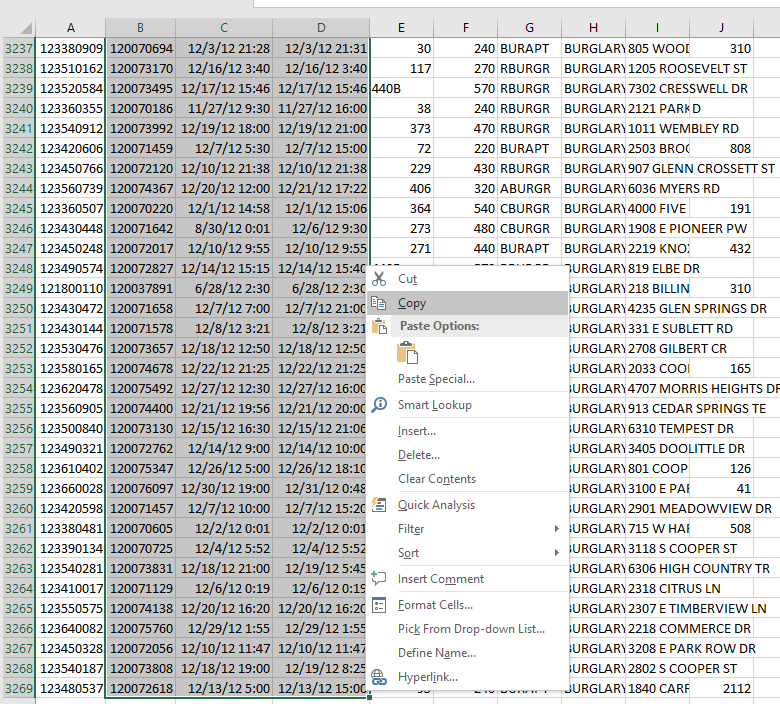
Now migrate over to the Aoristic_HourWeekday.xlsx spreadsheet, and paste the data into the first three columns of the OriginalData sheet.
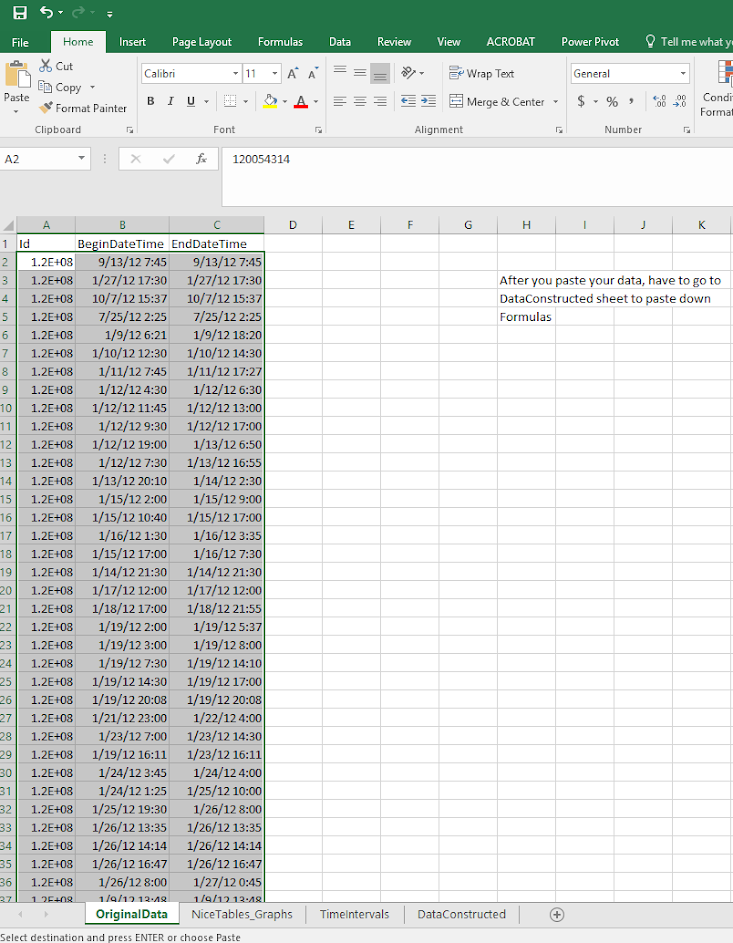
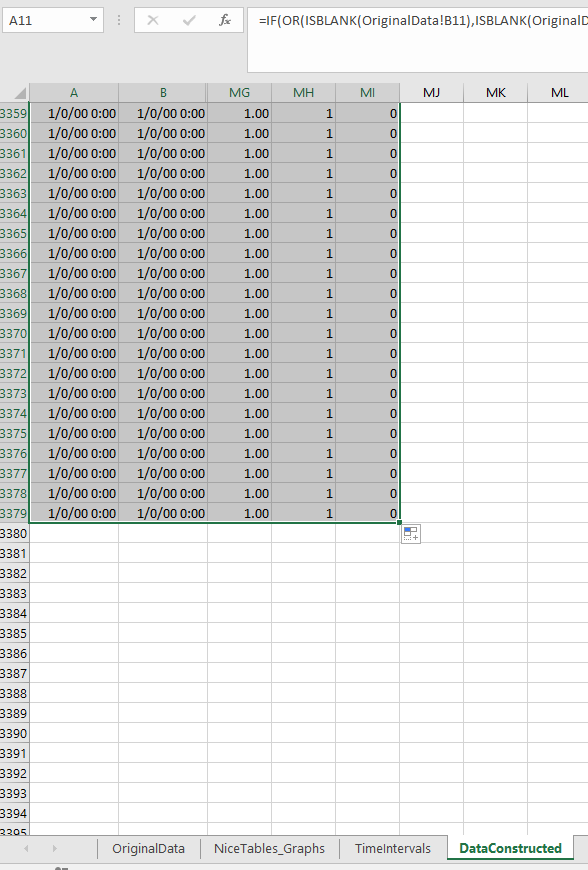
Now go to the DataConstructed sheet. Basically we need to update the formulas to recognize the new rows of data we just copied in. So go ahead and select the A11 to MI11 row. (Note there are a bunch of columns hidden from view).

Now we have a few over 3,000 cases in the Arlington burglary data. Grab the little green square in the lower right hand part of the selected cells, and then drag down the formulas. With your own data, you simply want to do this for as many cases as you have. If you go past your total N it is ok, it just treats the extra rows like missing data. This example with 3,268 cases then takes about a minute to crunch all of the calculations.
If you navigate to the TimeIntervals sheet, this is where the intervals are actually referenced, but I also place several summary statistics you might want to check out. The Total N shows that I have 3,268 good rows of data (which is what I expected). I have 110 missing rows (because I went over), and zero rows that have the begin/end times switched. The total proportion should always equal 1 — if it doesn’t I’ve messed up something — so please let me know!
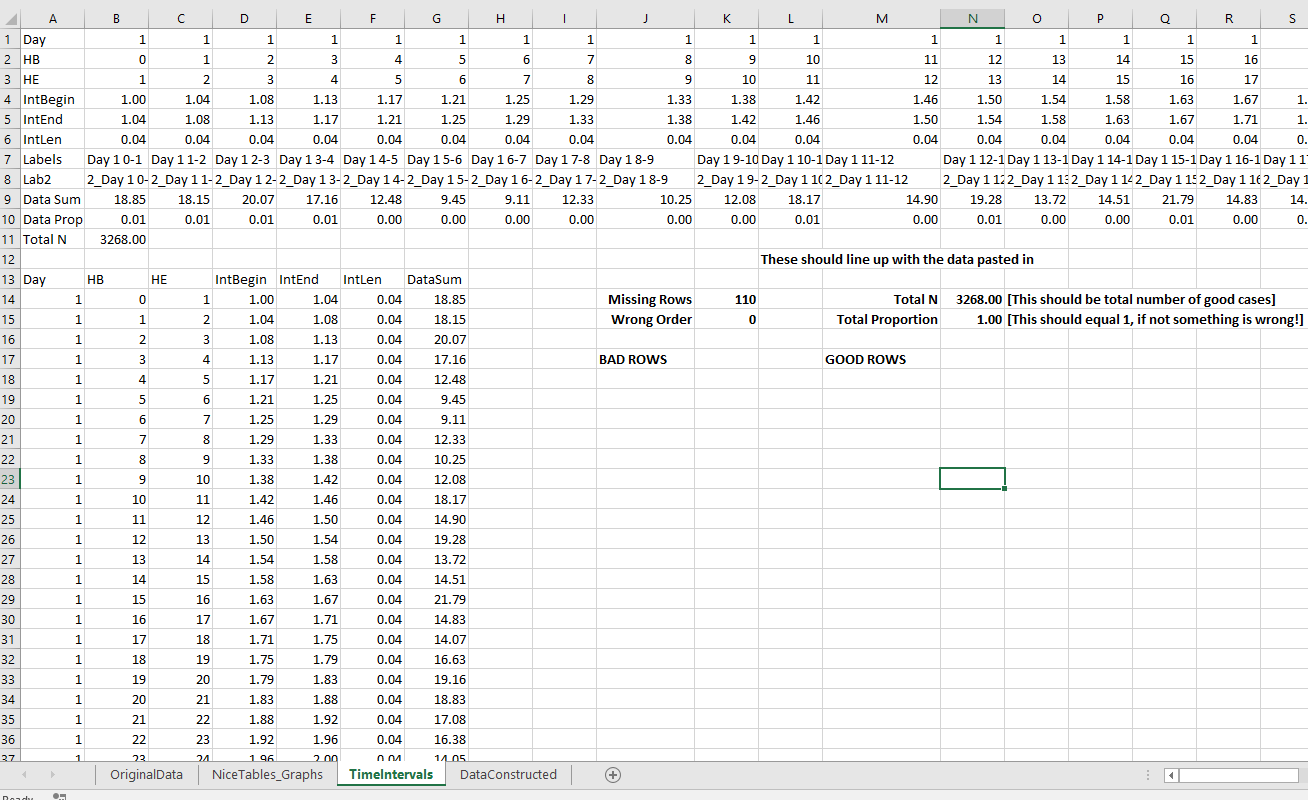
Now the good stuff, if you navigate to the NiceTables_Graphs sheet it does all the summaries that you might want. Considering it takes awhile to do all the calculations (even for a tinier dataset of 3,000 cases), if you want to edit things I would suggest copying and pasting the data values from this sheet into another one, to avoid redoing needless calculations.
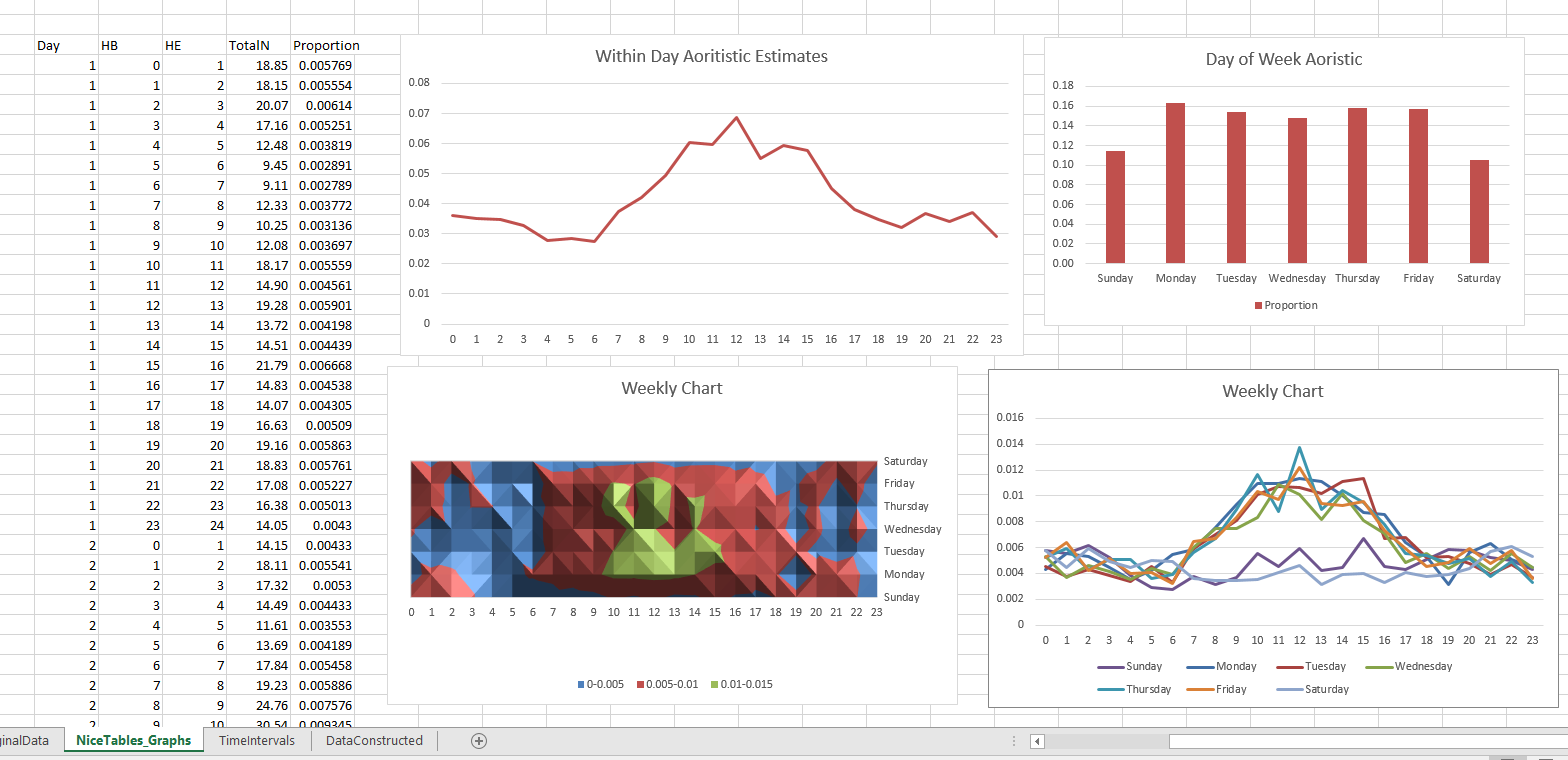
Interpreting the graphs you can see that burglaries in this dataset have a higher proportion of events during the daytime, but only on weekdays. Basically what you would expect.
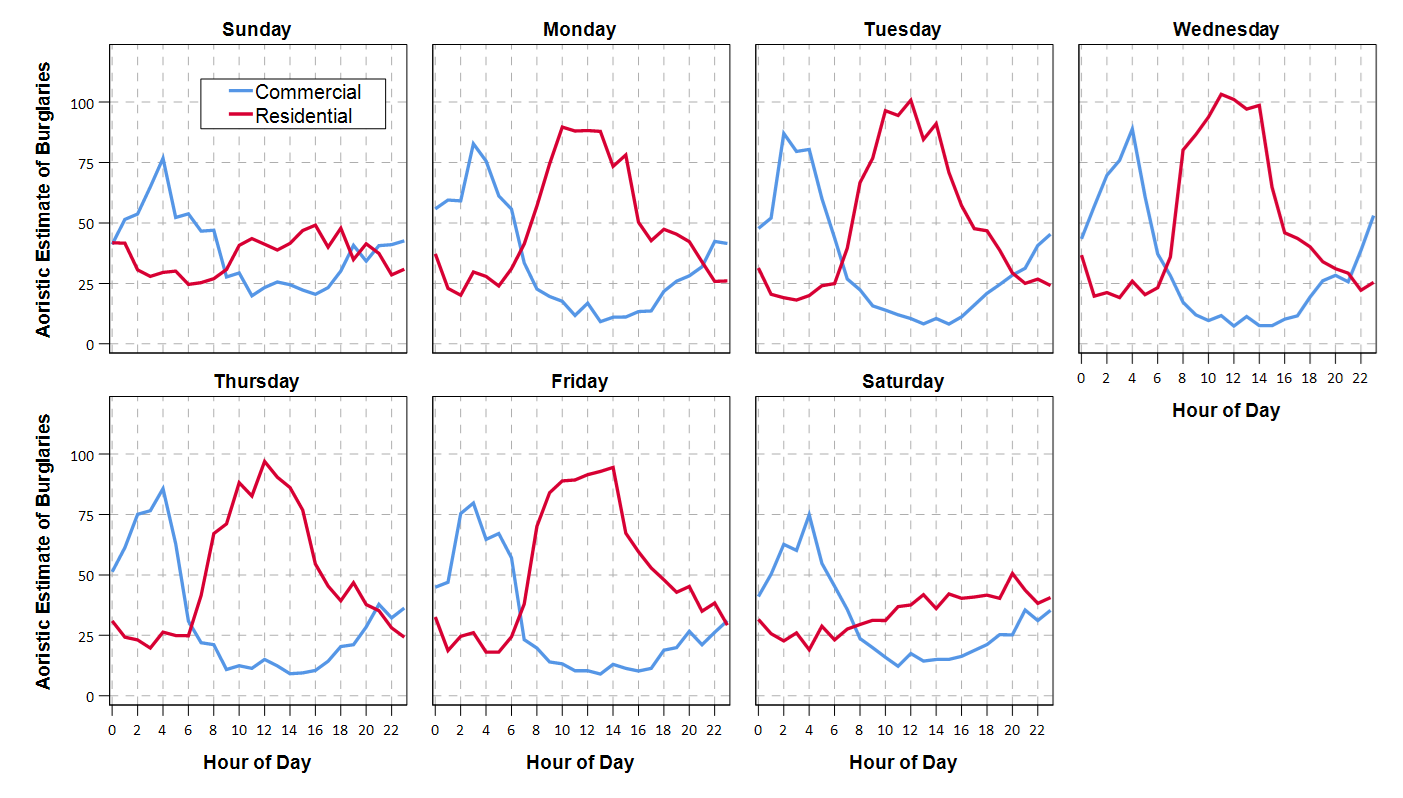
Personally I would always do this analysis in SPSS, as you can make much nicer small multiple graphs than Excel like below. Also my SPSS code can split the data between different subsets. This particular Excel code you would just need to repeat for whatever subset you are interested in. But a better Excel sleuth than me can likely address some of those critiques.
One minor additional note on this is that Jerry’s original recommendation rounded the results. My code does proportional allocation. So if you have an interval like 00:50 TO 01:30, it would assign the [0-1] hour as 10/40, and [1-2] as 30/40 (original Jerry’s would be 50% in each hour bin). Also if you have an interval that is longer than the entire week, I simply assign equal ignorance to each bin, I don’t further wrap it around.


Alexander Jones
/ April 28, 2020I’m graduating with a degree in Crime Analysis in a few weeks. Final project due tomorrow. You are the greatest human being ever. This is such a useful product. I will most certainly be using it again. Thank you so much! This is truly brilliant.
Yves
/ January 17, 2023Hi there
I am an archaeology student from Switzerland and was wondering whether your spreadsheet can be rewritten, so that the timespan of BeginOrig and EndOrig would cover Years instead of Days/Hours or Weeks.
Cheers
apwheele
/ January 17, 2023The spreadsheet approach is maybe not so good if you have many years. Here is a simple python script, it will not be uber efficient, but will still be OK even if you have millions of years and many records.
#################################
import numpy as np
# arrays that have begin and end years
begin = np.array([2005,2010,2016])
end = np.array([2005,2011,2020])
toty = end – begin + 1 # assumes no partial years
# now make arrays to hold the aoristic results
low = begin.min()
hig = end.max()
yr = np.arange(low,hig+1)
res = []
for y in yr:
# See how many are inside years
inside = (y >= begin) & (y <= end)
# weight cases by toty
av = (inside/toty).sum()
res.append(av)
res = np.array(res)
# Show the results, these will sum to the original counts
np.stack([yr,res],axis=1)
#################################
Yves
/ January 18, 2023Thank you so much. Works great!
John Erickson
/ October 5, 2023Andrew,
I use your Excel workbook a lot, and it’s great! I’ve seen in your other posts that you had been playing around with Tableau a bit. Any chance you’ve figured out a way to build these…or similar types of Aoristic charts into Tableau?
Thanks so much!
apwheele
/ October 5, 2023I have not done this explicitly in Tableau. So the way to do this consistent with Tableau’s data model (so you can slice/brush and still get appropriate aggregations), you want to calculate the row weights in the data model.
You can do this either outside (if pulling from database, can create a view), or in Tableau itself via calculated fields. In the excel spreadsheet, check out the `DataConstructed` tab, you will want to replicate the field calculations from C to the end of the spreadsheet. That gives you the columns to be able to do the chart.