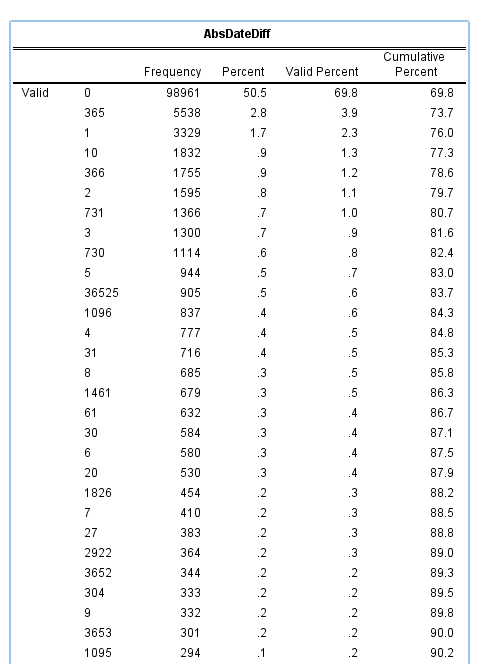
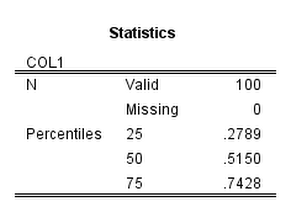
Had a request not so recently about implementing weighted buffer counts. The idea behind a weighted buffer is that instead of say counting the number of crimes that happen within 1,000 meters of a school, you want to give events that are closer to the school more weight.
There are two reasons you might want to do this for crime analysis:
- You want to measure the amount of crime around a location, but you rather have a weighted crime count, where crimes closer to the location have a greater weight than those further away.
- You want to measure attributes nearby a location (so things that predict crime), but give a higher weight to those closer to a location.
The second is actually more common in academic literature — see John Hipp’s Egohoods, or Liz Groff’s work on measuring nearby to bars, or Joel Caplan and using kernel density to estimate the effect of crime generators. Jerry Ratcliffe and colleagues work on the buffer intensity calculator is actually the motivation for the original request. So here are some quick code snippets in R to accomplish either. Here is the complete code and original data to replicate.
Here I use over 250,000 reported Part 1 crimes in DC from 08 through 2015, 173 school locations, and 21,506 street units (street segment midpoints and intersections) I constructed for various analyses in DC (all from open data sources) as examples.
Example 1: Crime Buffer Intensities Around Schools
First, lets define where our data is located and read in the CSV files (don’t judge me setting the directory, I do not use RStudio!)
MyDir <- 'C:\\Users\\axw161530\\Dropbox\\Documents\\BLOG\\buffer_stuff_R\\Code' #Change to location on your machine!
setwd(MyDir)
CrimeData <- read.csv('DC_Crime_08_15.csv')
SchoolLoc <- read.csv('DC_Schools.csv')Now there are several ways to do this, but here is the way I think will be most useful in general for folks in the crime analysis realm. Basically the workflow is this:
- For a given school, calculate the distance between all of the crime points and that school
- Apply whatever function to that distance to get your weight
- Sum up your weights
For the function to the distance there are a bunch of choices (see Jerry’s buffer intensity I linked to previously for some example discussion). I’ve written previously about using the bi-square kernel. So I will illustrate with that.
Here is an example for the first school record in the dataset.
#Example for crimes around school, weighted by Bisquare kernel
BiSq_Fun <- function(dist,b){
ifelse(dist < b, ( 1 - (dist/b)^2 )^2, 0)
}
S1 <- t(SchoolLoc[1,2:3])
Dis <- sqrt( (CrimeData$BLOCKXCOORD - S1[1])^2 + (CrimeData$BLOCKYCOORD - S1[2])^2 )
Wgh <- sum( BiSq_Fun(Dis,b=2000) )Then repeat that for all of the locations that you want the buffer intensities, and stuff it in the original SchoolLoc data frame. (Takes less than 30 seconds on my machine.)
SchoolLoc$BufWeight <- -1 #Initialize field
#Takes about 30 seconds on my machine
for (i in 1:nrow(SchoolLoc)){
S <- t(SchoolLoc[i,2:3])
Dis <- sqrt( (CrimeData$BLOCKXCOORD - S[1])^2 + (CrimeData$BLOCKYCOORD - S[2])^2 )
SchoolLoc[i,'BufWeight'] <- sum( BiSq_Fun(Dis,b=2000) )
}In this example there are 173 schools and 276,621 crimes. It is too big to create all of the pairwise comparisons at once (which will generate nearly 50 million records), but the looping isn’t too cumbersome and slow to worry about building a KDTree.
One thing to note about this technique is that if the buffers are large (or you have locations nearby one another), one crime can contribute to weighted crimes for multiple places.
Example 2: Weighted School Counts for Street Units
To extend this idea to estimating attributes at places just essentially swaps out the crime locations with whatever you want to calculate, ala Liz Groff and her inverse distance weighted bars paper. I will show something alittle different though, in using the weights to create a weighted sum, which is related to John Hipp and Adam Boessen’s idea about Egohoods.
So here for every street unit I’ve created in DC, I want an estimate of the number of students nearby. I not only want to count the number of kids in attendance in schools nearby, but I also want to weight schools that are closer to the street unit by a higher amount.
So here I read in the street unit data. Also I do not have school attendance counts in this dataset, so I just simulate some numbers to illustrate.
StreetUnits <- read.csv('DC_StreetUnits.csv')
StreetUnits$SchoolWeight <- -1 #Initialize school weight field
#Adding in random school attendance
SchoolLoc$StudentNum <- round(runif(nrow(SchoolLoc),100,2000)) Now it is very similar to the previous example, you just do a weighted sum of the attribute, instead of just counting up the weights. Here for illustration purposes I use a different weighting function, inverse distance weighting with a distance cut-off. (I figured this would need a better data management strategy to be timely, but this loop works quite fast as well, again under a minute on my machine.)
#Will use inverse distance weighting with cut-off instead of bi-square
Inv_CutOff <- function(dist,cut){
ifelse(dist < cut, 1/dist, 0)
}
for (i in 1:nrow(StreetUnits)){
SU <- t(StreetUnits[i,2:3])
Dis <- sqrt( (SchoolLoc$XMeters - SU[1])^2 + (SchoolLoc$YMeters - SU[2])^2 )
Weights <- Inv_CutOff(Dis,cut=8000)
StreetUnits[i,'SchoolWeight'] <- sum( Weights*SchoolLoc$StudentNum )
} The same idea could be used for other attributes, like sales volume for restaurants to get a measure of the business of the location (I think more recent work of John Hipp’s uses the number of employees).
Some attributes you may want to do the weighted mean instead of a weighted sum. For example, if you were using estimates of the proportion of residents in poverty, it makes more sense for this measure to be a spatially smoothed mean estimate than a sum. In this case it works exactly the same but you would replace sum( Weights*SchoolLoc$StudentNum ) with sum( Weights*SchoolLoc$StudentNum )/sum(Weights). (You could use the centroid of census block groups in place of the polygon data.)
Some Wrap-Up
Using these buffer weights really just swaps out one arbitrary decision for data analysis (the buffer distance) with another (the distance weighting function). Although the weighting function is more complicated, I think it is probably closer to reality for quite a few applications.
Many of these different types of spatial estimates are all related to another (kernel density estimation, geographically weighted regression, kriging). So there are many different ways that you could go about making similar estimates. Not letting the perfect be the enemy of the good, I think what I show here will work quite well for many crime analysis applications.