Michael Sierra-Arévalo, Justin Nix and Bradley O’Guinn have a recent article about examining officer fatalities following gunshot assaults (Sierra-Arévalo, Nix, & O-Guinn). They do not find that distance to a Level 1/2 trauma ERs make a difference in the survival probabilities, which conflicts with prior work of mine with Gio Circo (Circo & Wheeler, 2021). Justin writes this as a potential explanation for the results:
The results of our multivariable analysis indicated that proximity to trauma care was not significantly associated with the odds of officers surviving a gunshot wound (see Table 2 on p. 9 of the post-print). On the one hand, this was somewhat surprising given that proximity to trauma care predicts survival of gunshot wounds among the general public.1 On the other hand, police have specialized equipment, such as ballistic vests and tourniquets, that reduce the severity of gunshot wounds or allow them to be treated immediately.
I think it is pretty common when results do not pan out, people turn to theoretical (or sociological) reasons why their hypothesis may be invalid. While these alternatives are often plausible, often equally plausible are simpler data based reasons. Here I was concerned about two factors, 1) power and 2) omitted severity of gun shot wound factors. I did a quick simulation in R to show power seems to be OK, but the omitted severity confounders may be more problematic in this design, although only bias the effect towards 0 (it would not cause the negative effect estimate MJB find).
Power In Logistic Regression
First, MJB’s sample size is just under 1,800 cases. You would think offhand this is plenty of power for whatever analysis right? Well, power just depends on the relevant effect size, a small effect and you need a bigger sample. My work with Gio found a linear effect in the logistic equation of 0.02 (per minute driving increases the logit). We had 5,500 observations, and our effect had a p-value just below 0.05, hence why a first thought was power. Also logistic regression is asymptotic, it is common to have small sample biases in situations even up to 1000 observations (Bergtold et al., 2018). So lets see in a simple example ignoring the other covariates:
# Some upfront work
logistic <- function(x){1/(1+exp(-x))}
set.seed(10)
# Scenario 1, no covariates omitted
n <- 2000;
de <- 0.02
dist <- runif(n,5,200)
p <- logistic(-2.5 + de*dist)
y <- rbinom(n,1,p)
# Variance is small enough, seems reasonably powered
summary(glm(y ~ dist, family = "binomial"))
Here with 2000 cases, taking the intercept from MJB’s estimates and the 0.02 from my paper, we see 2000 observations is plenty enough well powered to detect that same 0.02 effect in mine and Gio’s paper. Note when doing post-hoc power analysis, you don’t take the observed effect (the -0.001 in Justin’s paper), but a hypothetical effect size you think is reasonable (Gelman, 2019), which I just take from mine and Gio’s paper. Essentially saying “Is Justin’s analysis well powered to detect an effect of the same size I found in the Philly data”.
One thing that helps MJB’s design here is more variance in the distance parameter, looking intra city the drive time distances are smaller, which will increase the standard error of the estimate. If we pretend to limit the distances to 30 minutes, this study is more on the fence as to being well enough powered (but meets the threshold in this single simulation):
# Limited distance makes the effect have a higher variance
n <- 2000;
de <- 0.02
dist <- runif(n,1,30)
p <- logistic(-2.5 + de*dist)
y <- rbinom(n,1,p)
# Not as much variation in distance, less power
summary(glm(y ~ dist, family = "binomial"))
For a more serious set of analysis you would want to do these simulations multiple times and see the typical result (since they are stochastic), but this is good enough for me to say power is not an issue in this design. If people are planning on replications though, intra-city with only 1000 observations is really pushing it with this design though.
Omitted Confounders
One thing that is special about logistic regression, unlike linear regression, even if an omitted confounder is uncorrelated with the effect of interest, it can still bias the estimates (Mood, 2010). So even if you do a randomized experiment your effects could be biased if there is some large omitted effect from the regression equation. Several people interpret this as logistic regression is fucked, but like that linked Westfall article I think that is a bit of an over-reaction. Odds ratios are very tricky, but logistic regression as a method to estimate conditional means is not so bad.
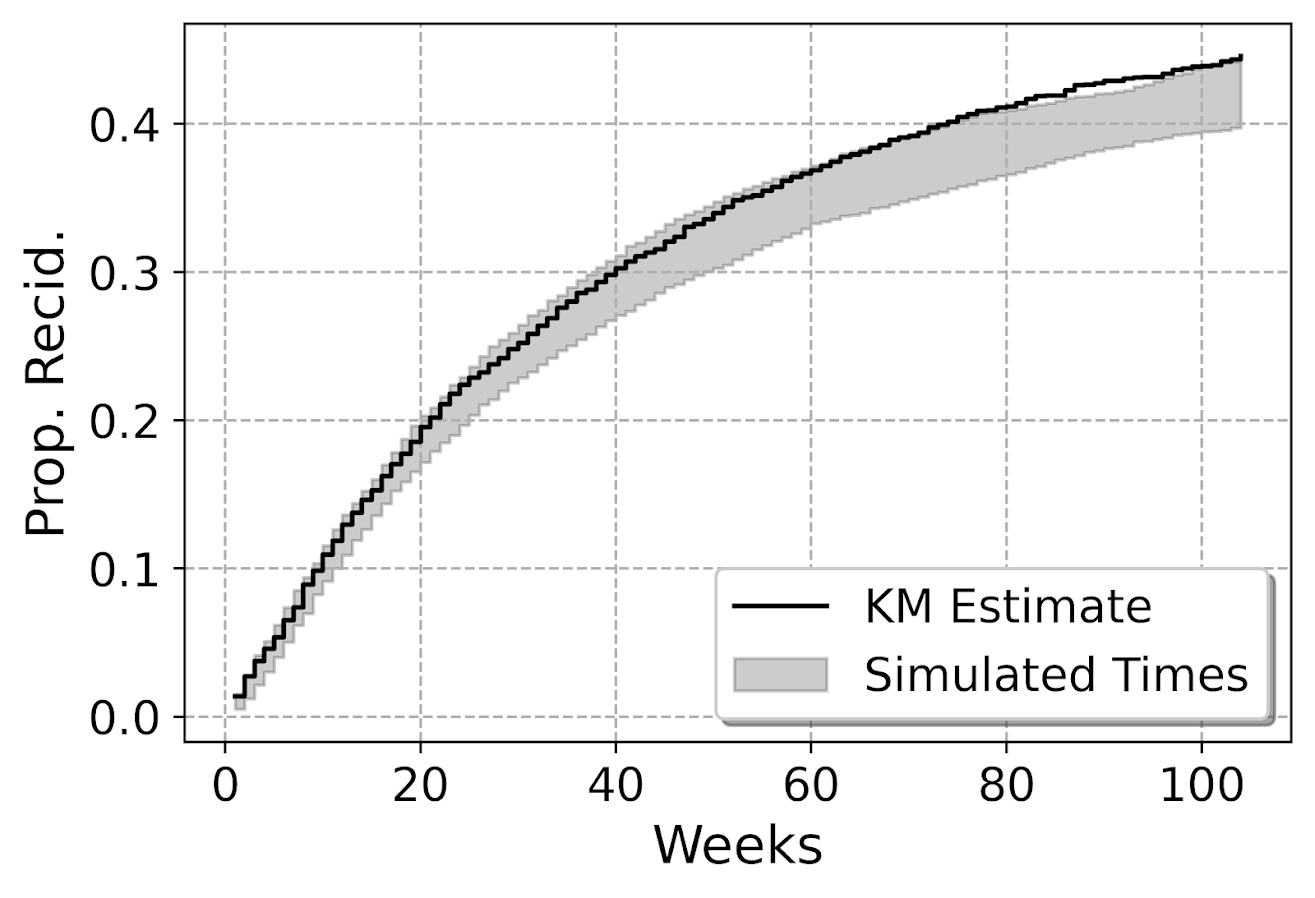
In my paper with Gio, the largest effect on whether someone would survive was based on the location of the bullet wound. Drive time distances then only marginal pushed up/down that probability. Here are conditional mean estimates from our paper:

So you can see that being shot in the head, drive time can make an appreciable difference over these ranges, from ~45% to 55% probability of death. Even if the location of the wound is independent of drive time (which seems quite plausible, people don’t shoot at your legs because you are far away from a hospital), it can still be an issue with this research design. I take Justin’s comment about ballistic vests as reducing death as essentially taking the people in the middle of my graph (torso and multiple injuries) and pushing them into the purple line at the bottom (extremities). But people shot in the head are not impacted by the vests.
So lets see what happens to our effect estimates when we generate the data with the extremities and head effects (here I pulled the estimates all from my article, baseline reference is shot in head and negative effect is reduction in baseline probability when shot in extremity):
# Scenario 3, wound covariate omitted
dist <- runif(n,5,200)
ext_wound <- rbinom(n,1,0.8)
ef <- -4.8
pm <- logistic(0.2 + de*dist + ef*ext_wound)
ym <- rbinom(n,1,pm)
# Biased downward (but not negative)
summary(glm(ym ~ dist, family = "binomial"))
You can see here the effect estimate is biased downward by a decent margin (less than half the size of the true effect). If we estimate the correct equation, we are on the money in this simulation run:

What happens if we up the sample size? Does this bias go away? Unfortunately it does not, here is an example with 10,000 observations:
# Scenario 3, wound covariate ommitted larger sample
n2 <- 10000
dist <- runif(n2,5,200)
ext_wound <- rbinom(n2,1,0.8)
ef <- -4.8
pm <- logistic(0.2 + de*dist + ef*ext_wound)
ym <- rbinom(n2,1,pm)
# Still a problem
summary(glm(ym ~ dist, family = "binomial"))
So this omission is potentially a bigger deal – but not in the way Justin states in his conclusion. The quote earlier suggests the true effect is 0 due to vests, I am saying here the effect in MJB’s sample is biased towards 0 due to this large omitted confounder on the severity of the wound. These are both plausible, there is no way based just on MJB’s data to determine if one interpretation is right and the other is wrong.
This would not explain the negative effect estimate MJB finds though in their paper, it would only bias towards 0. To be fair, Jessica Beard critiqued mine and Gio’s paper in a similar vein (saying the police wound location data had errors), this would make our drive time estimates be biased towards 0 as well, so if that factor may be even larger than me and Gio even estimated.
Potential robustness checks here are to simply do a linear regression instead of logistic with the same data (my graph above shows a linear regression would be fine for the data if I included interaction effects with wound location). And another would be to look at the unconditional marginal distribution of distance vs probability of death. If that is highly non-linear, it is likely due to omitted confounders in the data (I suspect it may plateau as well, eg the first 30 minutes make a big difference, but after that it flattens out, you’ve either stabilized someone or they are gone at that point).
Policy?
In the case of intra-city public violence, the policy implication of drive times on survival are relevant when people are determining whether to keep open or close trauma centers. I did not publish this in my paper with Gio (you can see the estimates in the replication code), but we actually estimated counter-factual increased deaths by taking away facilities. Its marginal effect is around 10~20 homicides over the 4.5 years if you take away one of the facilities in Philadelphia. I don’t know if reducing 5 homicides per year is sufficient justification to keep a trauma facility open, but officer shootings are themselves much less frequent, and so the marginal effects are very unlikely to justify keeping a trauma facility open/closed by themselves.
You could technically figure out the optimal location to site a new trauma facility from mine and Gio’s paper, but probably a more reasonable response would be to site resources to get people to the ER faster. Philly already does scoop and run (Winter et al., 2021), where officers don’t wait for an ambulance. Another possibility though is to proactively locate ambulances to get to scenes faster (Hosler et al., 2019). Again though it just isn’t as relevant/feasible outside of major urban areas though to do that.
Often times social science authors do an analysis, and then in the policy section say things that are totally reasonable on their face, but are not supported by the empirical analysis. Here the suggestion that officers should increase their use of vests by MJB is totally reasonable, but nothing in their analysis supports that conclusion (ditto with the tourniquets statement). You would need to measure those incidents that had those factors, and see its effect on officer survival to make that inference. MJB could have made the opposite statement, since drive time doesn’t matter, maybe those things don’t make a difference in survival, and be equally supported by the analysis.
I suspect MJB’s interest in the analysis was simply to see if survival rates were potential causes of differential officer deaths across states (Sierra-Arévalo & Nix, 2020). Which is fine to look at by itself, even if it has no obviously direct policy implications. Talking back and forth with Justin before posting this, he did mention it was a bit of prodding from a reviewer to add in the policy implications. Which it goes for both (reviewers or original writers), I don’t think we should pad papers with policy recommendations (or ditto for theoretical musings) that aren’t directly supported by the empirical analysis we conduct.
References
- Bergtold, J. S., Yeager, E. A., & Featherstone, A. M. (2018). Inferences from logistic regression models in the presence of small samples, rare events, nonlinearity, and multicollinearity with observational data. Journal of Applied Statistics, 45(3), 528-546.
- Circo, G. M., & Wheeler, A. P. (2021). Trauma Center Drive Time Distances and Fatal Outcomes among Gunshot Wound Victims. Applied Spatial Analysis and Policy, 14(2), 379-393.
- Gelman, A. (2019). Don’t calculate post-hoc power using observed estimate of effect size. Annals of Surgery, 269(1), e9-e10.
- Hosler, R., Liu, X., Carter, J., & Saper, M. (2019). RaspBary: Hawkes Point Process Wasserstein Barycenters as a Service.
- Mood, C. (2010). Logistic regression: Why we cannot do what we think we can do, and what we can do about it. European Sociological Review, 26(1), 67-82.
- Sierra-Arévalo, M., & Nix, J. (2020). Gun victimization in the line of duty: Fatal and nonfatal firearm assaults on police officers in the United States, 2014–2019. Criminology & Public Policy, 19(3), 1041-1066.
- Sierra-Arévalo, Michael, Justin Nix, & Bradley O’Guinn (2022). A National Analysis of Trauma Care Proximity and Firearm Assault Survival among U.S. Police. Forthcoming in Police Practice and Research. Post-print available at
- Winter, E., Hynes, A. M., Shultz, K., Holena, D. N., Malhotra, N. R., & Cannon, J. W. (2021). Association of police transport with survival among patients with penetrating trauma in Philadelphia, Pennsylvania. JAMA network open, 4(1), e2034868-e2034868.