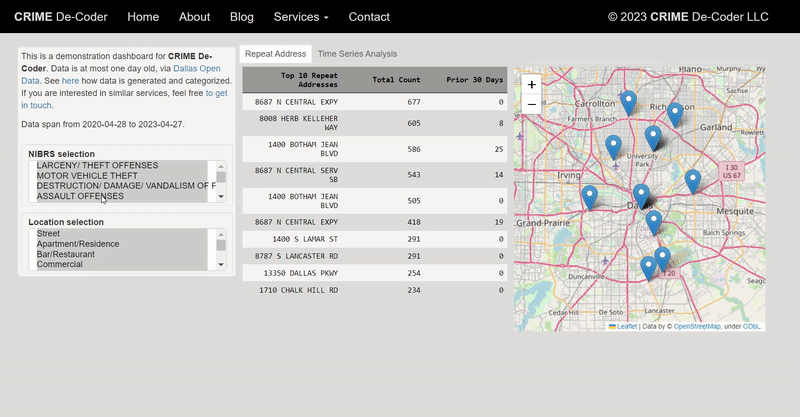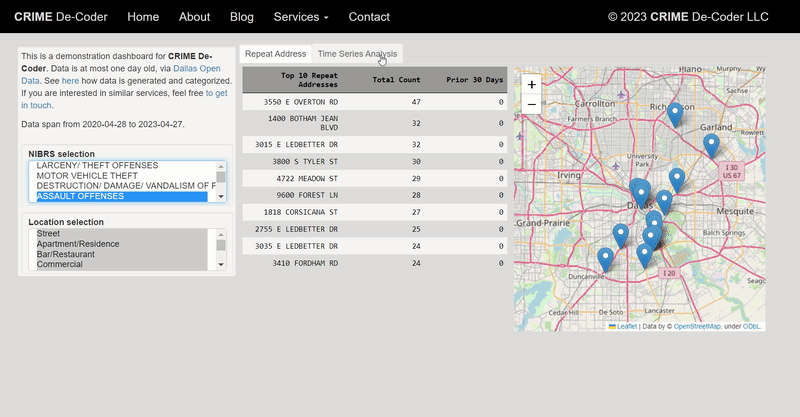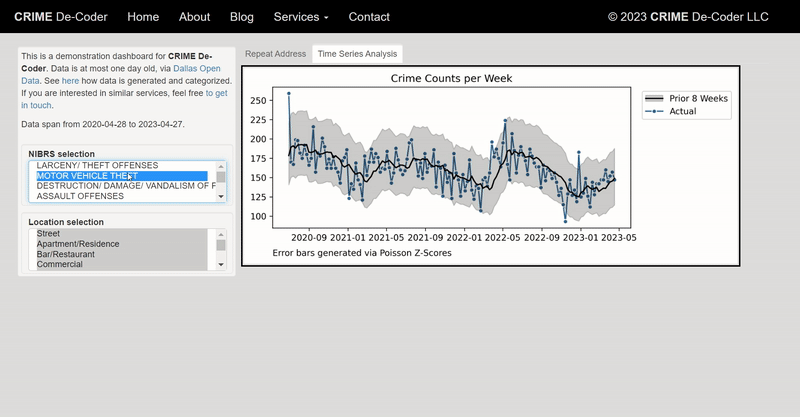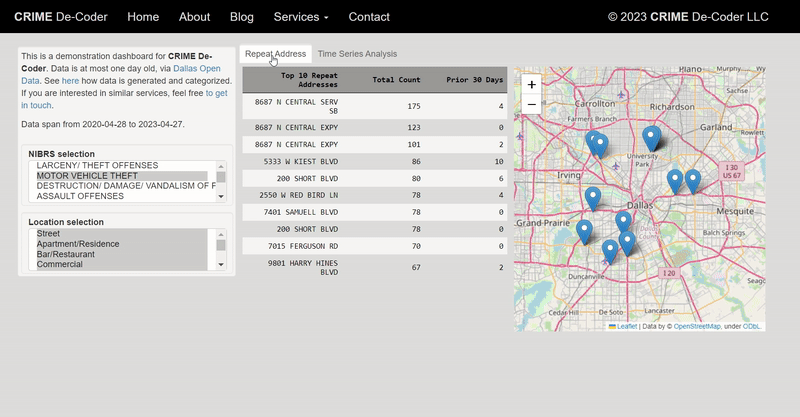
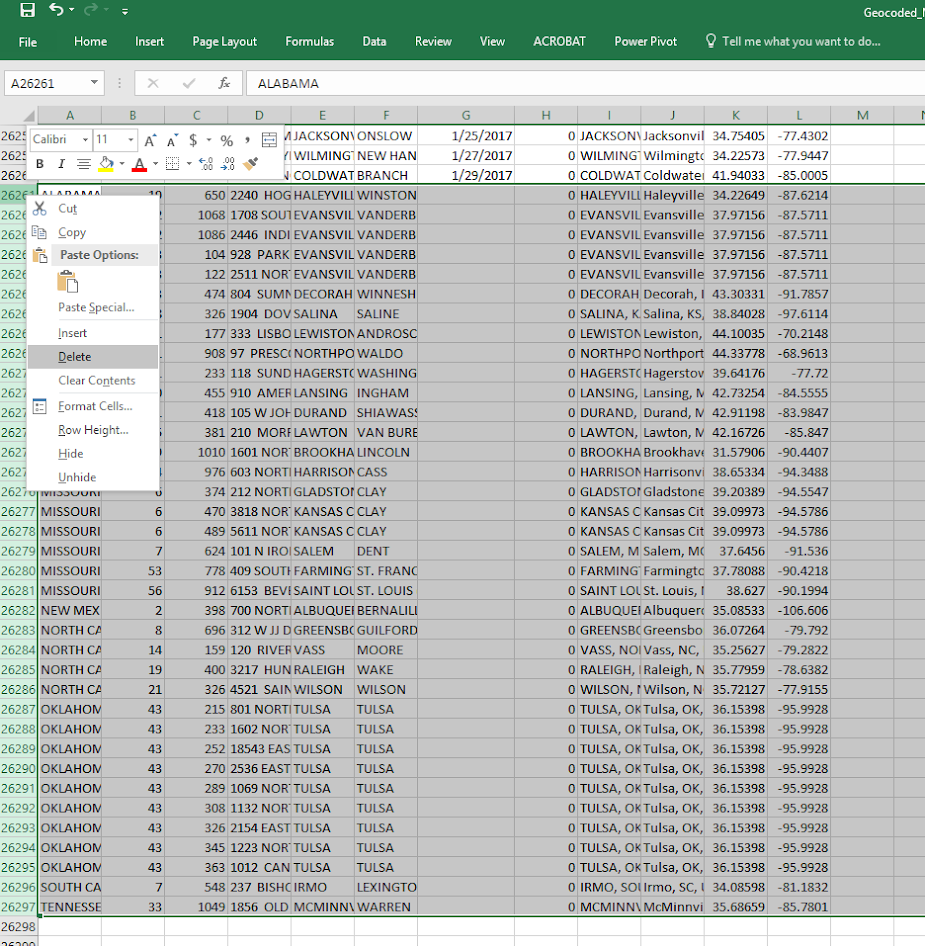
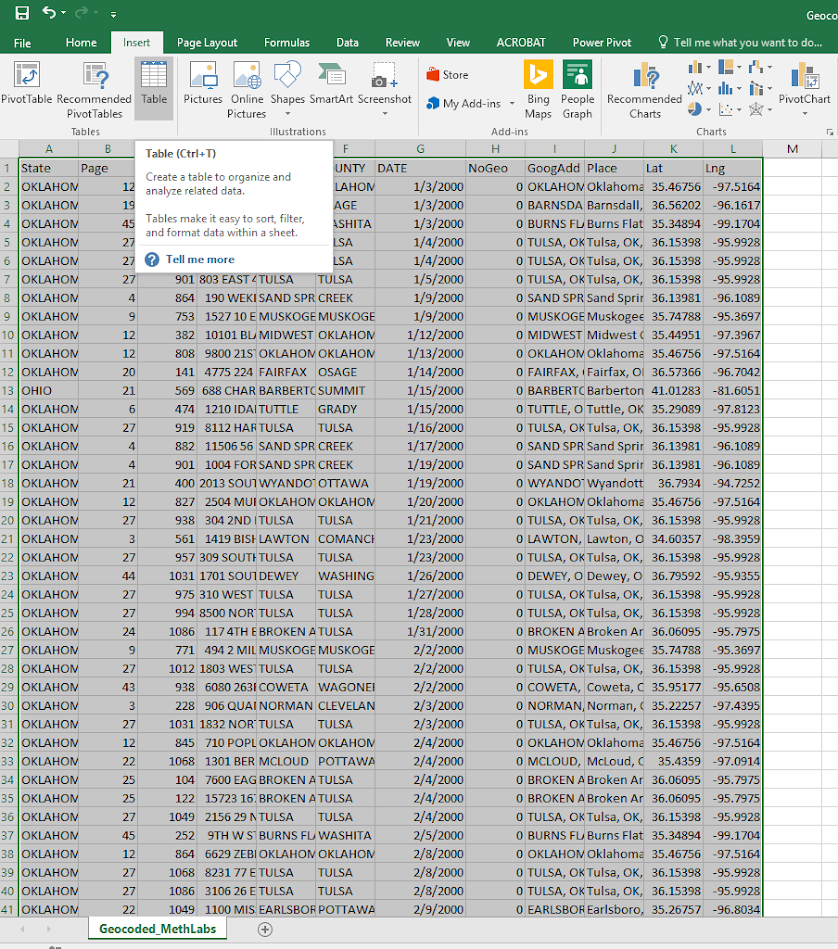
For awhile in my GIS courses I have pointed to the DEA’s website that has a list of busted meth labs across the county, named the National Clandestine Laboratory Register. Finally a student has shown some interest in this, and so I spent alittle time writing a scraper in Python to grab the data. For those who would just like the data, here I have a csv file of the scraped labs that are geocoded to the city level. And here is the entire SPSS and Python script to go from the original PDF data to the finished product.
So first off, if you visit the DEA website, you will see that each state has its own PDF file (for example here is Texas) that lists all of the registered labs, with the county, city, street address, and date. To turn this into usable data, I am going to do three steps in Python:
- download the PDF file to my local machine using
urllib python library
- convert that PDF to an xml file using the
pdftohtml command line utility
- use
Beautifulsoup to parse the xml file
I will illustrate each in turn and then provide the entire Python script at the end of the post.
So first, lets import the libraries we need, and also note I downloaded the pdftohtml utility and placed that location as a system path on my Windows machine. Then we need to set a folder where we will download the files to on our local machine. Finally I create the base url for our meth labs.
from bs4 import BeautifulSoup
import urllib, os
myfolder = r'C:\Users\axw161530\Dropbox\Documents\BLOG\Scrape_Methlabs\PDFs' #local folder to download stuff
base_url = r'https://www.dea.gov/clan-lab' #online site with PDFs for meth lab seizures
Now to just download the Texas pdf file to our local machine we would simply do:
a = 'tx'
url = base_url + r'/' + a + '.pdf'
file_loc = os.path.join(myfolder,a)
urllib.urlretrieve(url,file_loc + '.pdf')
If you are following along and replaced the path in myfolder with a folder on your personal machine, you should now see the Texas PDF downloaded in that folder. Now I am going to use the command line to turn this PDF into an xml document using the os.system() function.
#Turn to xml with pdftohtml, does not need xml on end
cmd = 'pdftohtml -xml ' + file_loc + ".pdf " + file_loc
os.system(cmd)
You should now see that there is an xml document to go along with the Texas file. You can check out its format using a text editor (wordpress does not seem to like me showing it here).
So basically we can use the top and the left attributes within the xml to identify what row and what column the items are in. But first, we need to read in this xml and turn it into a BeautifulSoup object.
MyFeed = open(file_loc + '.xml')
textFeed = MyFeed.read()
FeedParse = BeautifulSoup(textFeed,'xml')
MyFeed.close()
Now the FeedParse item is a BeautifulSoup object that you can query. In a nutshell, we have a top level page tag, and then within that you have a bunch of text tags. Here is the function I wrote to extract that data and dump it into tuples.
#Function to parse the xml and return the line by line data I want
def ParseXML(soup_xml,state):
data_parse = []
page_count = 1
pgs = soup_xml.find_all('page')
for i in pgs:
txt = i.find_all('text')
order = 1
for j in txt:
value = j.get_text() #text
top = j['top']
left = j['left']
dat_tup = (state,page_count,order,top,left,value)
data_parse.append(dat_tup)
order += 1
page_count += 1
return data_parse
So with our Texas data, we could call ParseXML(soup_xml=FeedParse,state=a) and it will return all of the data nested in those text tags. We can just put these all together and loop over all of the states to get all of the data. Since the PDFs are not that large it works quite fast, under 3 minutes on my last run.
from bs4 import BeautifulSoup
import urllib, os
myfolder = r'C:\Users\axw161530\Dropbox\Documents\BLOG\Scrape_Methlabs\PDFs' #local folder to download stuff
base_url = r'https://www.dea.gov/clan-lab' #online site with PDFs for meth lab seizures
#see https://www.dea.gov/clan-lab/clan-lab.shtml
state_ab = ['al','ak','az','ar','ca','co','ct','de','fl','ga','guam','hi','id','il','in','ia','ks',
'ky','la','me','md','ma','mi','mn','ms','mo','mt','ne','nv','nh','nj','nm','ny','nc','nd',
'oh','ok','or','pa','ri','sc','sd','tn','tx','ut','vt','va','wa','wv','wi','wy','wdc']
state_name = ['Alabama','Alaska','Arizona','Arkansas','California','Colorado','Connecticut','Delaware','Florida','Georgia','Guam','Hawaii','Idaho','Illinois','Indiana','Iowa','Kansas',
'Kentucky','Louisiana','Maine','Maryland','Massachusetts','Michigan','Minnesota','Mississippi','Missouri','Montana','Nebraska','Nevada','New Hampshire','New Jersey',
'New Mexico','New York','North Carolina','North Dakota','Ohio','Oklahoma','Oregon','Pennsylvania','Rhode Island','South Carolina','South Dakota','Tennessee','Texas',
'Utah','Vermont','Virginia','Washington','West Virginia','Wisconsin','Wyoming','Washington DC']
all_data = [] #this is the list that the tuple data will be stashed in
#Function to parse the xml and return the line by line data I want
def ParseXML(soup_xml,state):
data_parse = []
page_count = 1
pgs = soup_xml.find_all('page')
for i in pgs:
txt = i.find_all('text')
order = 1
for j in txt:
value = j.get_text() #text
top = j['top']
left = j['left']
dat_tup = (state,page_count,order,top,left,value)
data_parse.append(dat_tup)
order += 1
page_count += 1
return data_parse
#This loops over the pdfs, downloads them, turns them to xml via pdftohtml command line tool
#Then extracts the data
for a,b in zip(state_ab,state_name):
#Download pdf
url = base_url + r'/' + a + '.pdf'
file_loc = os.path.join(myfolder,a)
urllib.urlretrieve(url,file_loc + '.pdf')
#Turn to xml with pdftohtml, does not need xml on end
cmd = 'pdftohtml -xml ' + file_loc + ".pdf " + file_loc
os.system(cmd)
#parse with BeautifulSoup
MyFeed = open(file_loc + '.xml')
textFeed = MyFeed.read()
FeedParse = BeautifulSoup(textFeed,'xml')
MyFeed.close()
#Extract the data elements
state_data = ParseXML(soup_xml=FeedParse,state=b)
all_data = all_data + state_data
Now to go from those sets of tuples to actually formatted data takes a bit of more work, and I used SPSS for that. See here for the full set of scripts used to download, parse and clean up the data. Basically it is alittle more complicated than just going from long to wide using the top marker for the data as some rows are off slightly. Also there is complications for long addresses being split across two lines. And finally there are just some data errors and fields being merged together. So that SPSS code solves a bunch of that. Also that includes scripts to geocode the to the city level using the Google geocoding API.
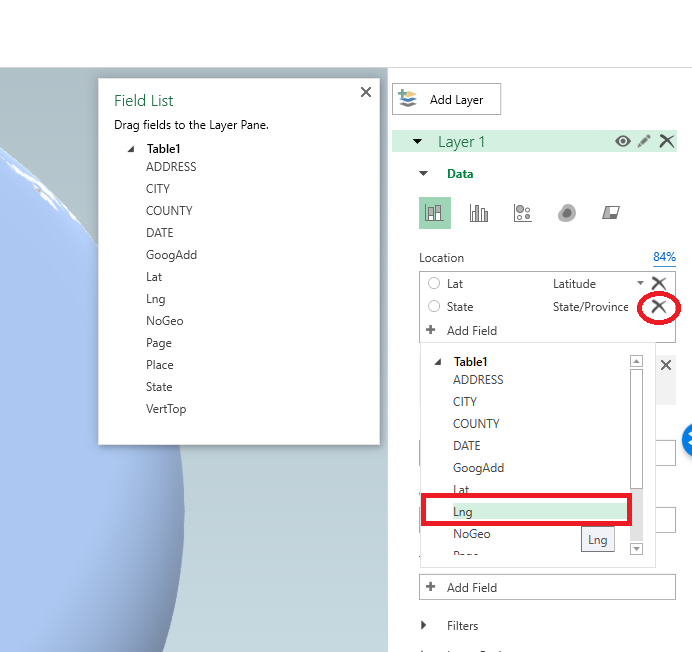
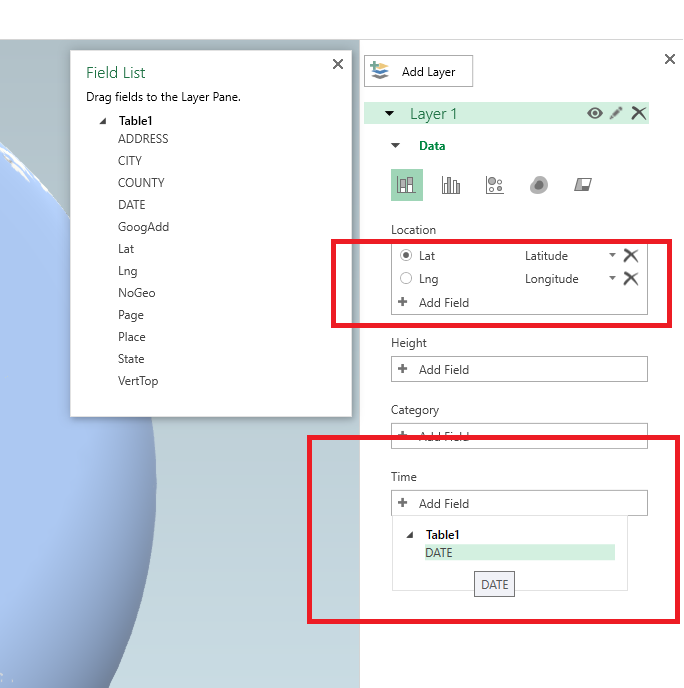
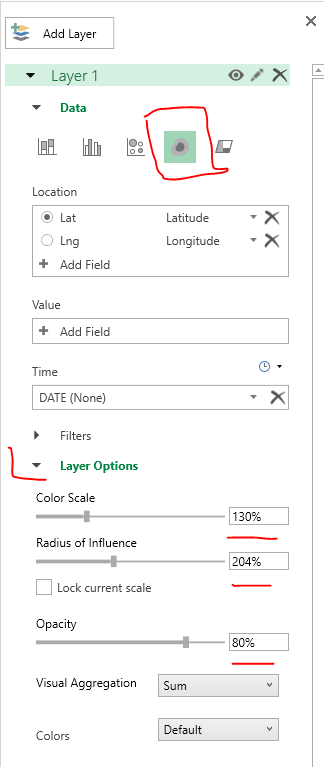
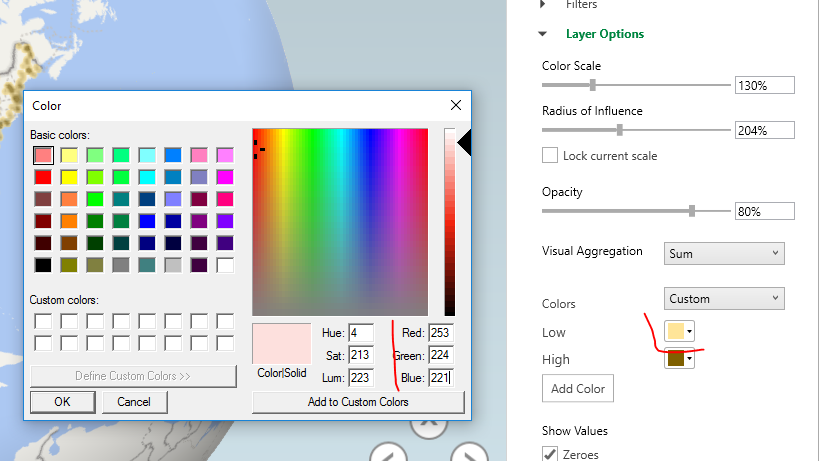
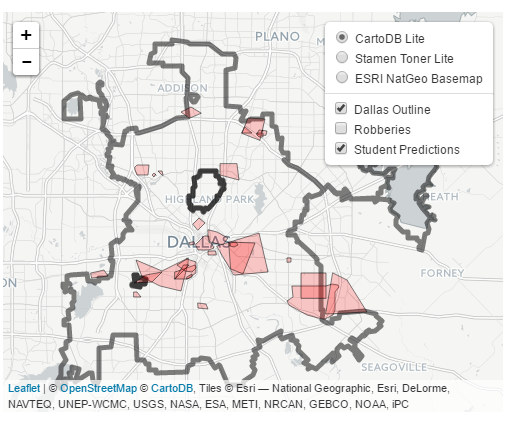
Let me know if you do any analysis of this data! I quickly made a time series map of these events via CartoDB. You can definately see some interesting patterns of DEA concentration over time, although I can’t say if that is due to them focusing on particular areas or if they are really the areas with the most prevalent Meth lab problems.
https://andyw.carto.com/viz/882243de-ff69-11e6-b574-0e98b61680bf/public_map
If interested in other tutorials like this, I suggest you check out two of my books:
Each can be purchase in either paperback for epub versions worldwide from my Crime De-Coder store.