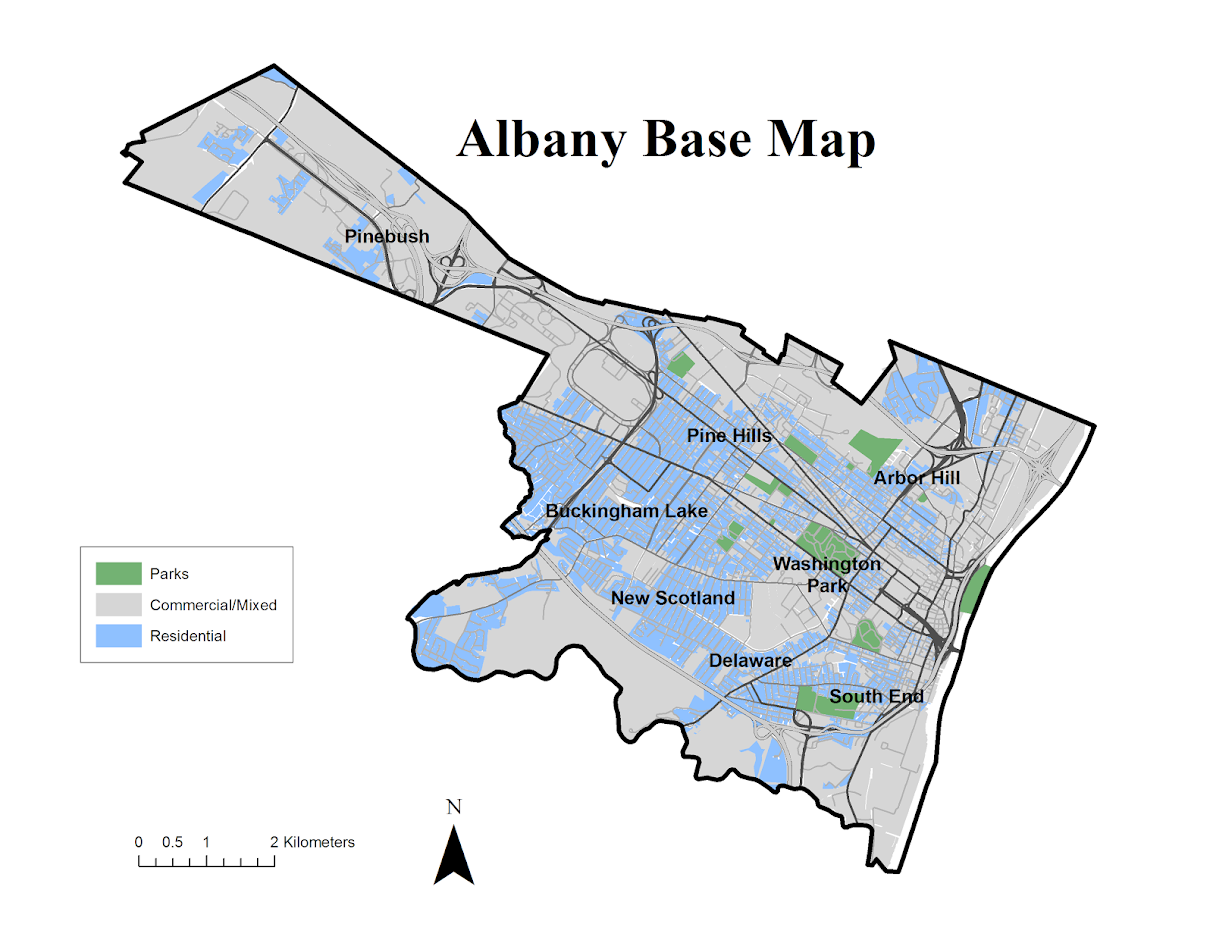
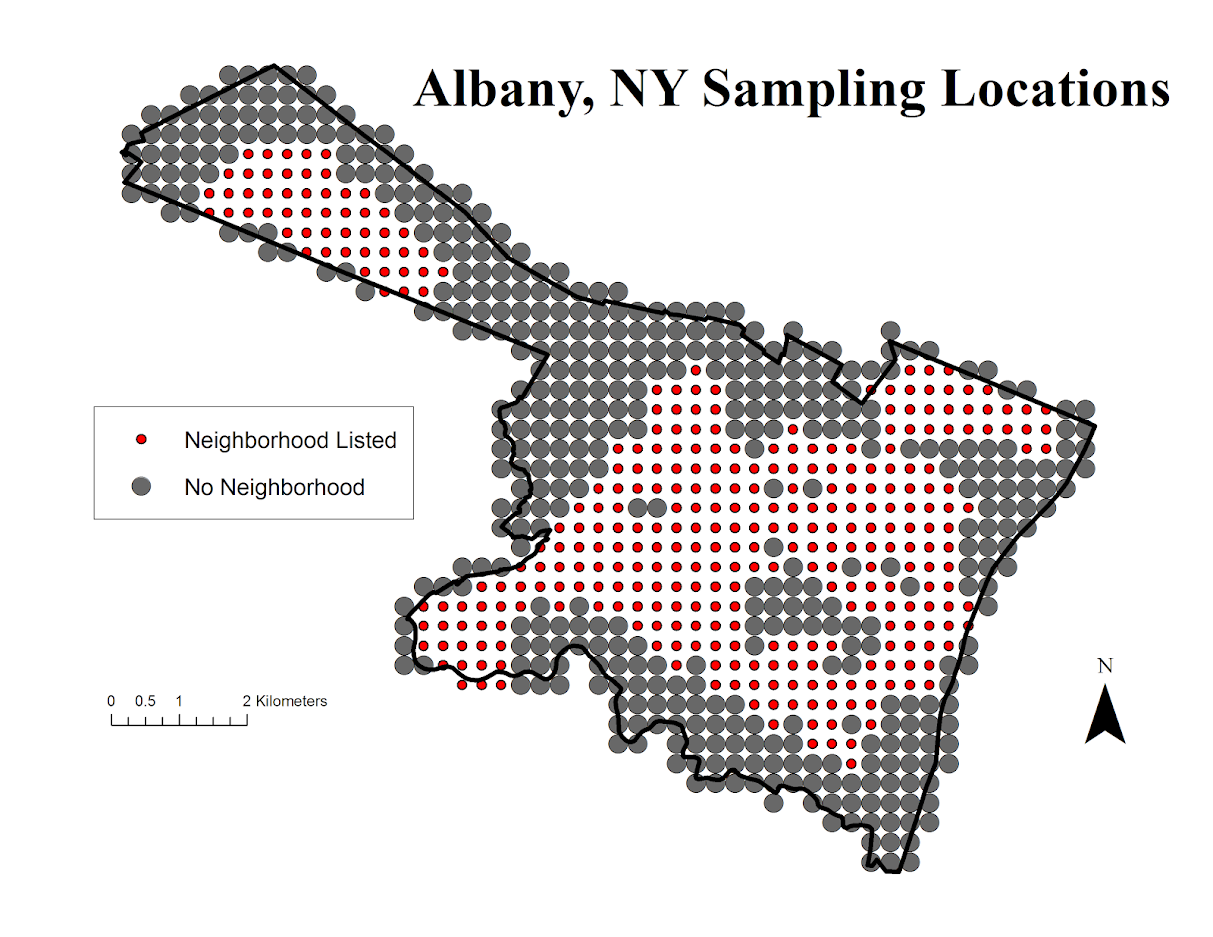
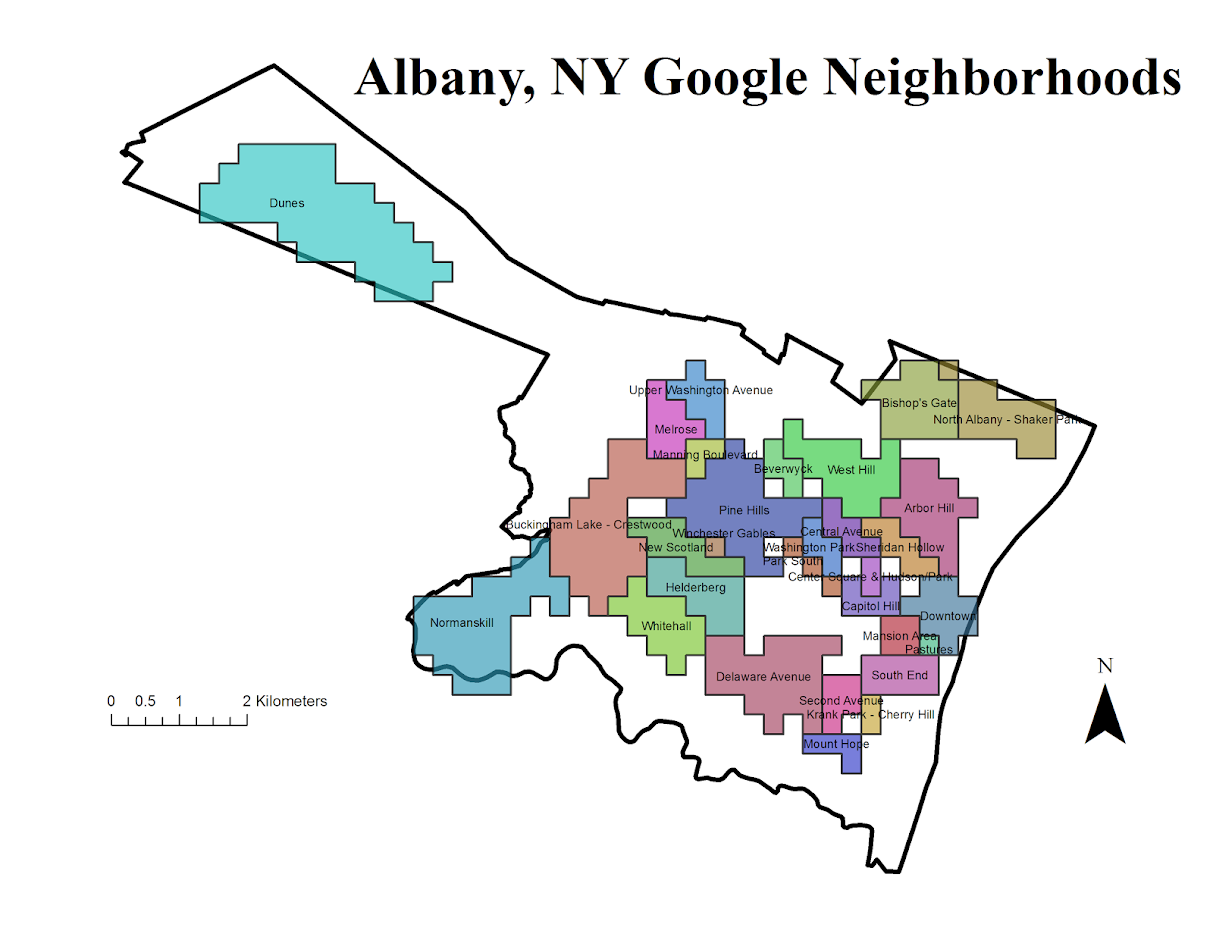
Google image on 5/4/16 – Jane Jacobs 100th birthday.
Continuing on with my discussion of neighborhoods, it seems apt to talk about how Jane Jacob defines neighborhoods in her book The Death and Life of Great American Cities. She is often given perfunctory citations in criminology articles for the idea that mixed zoned neighborhoods (those with both residential and commercial zoning all together) increase “eyes on the street” and thus can reduce crime. I will write another post more fully about informal social control and how her ideas fit in, but here I want to focus on her conception of neighborhoods.
She asks the question, what do neighborhoods accomplish – and from this attempts to define what is a neighborhood. Thus she feels a neighborhood can only be defined in terms of having actual political capital to use for its constituents – and so a neighborhood is any region in which can be organized enough to act as an independent polity and campaign against the larger government in which it is nested. This is quite different from the current conception of neighborhoods in most social sciences – in which we assume neighborhoods exist, calculate their effects on behavior, and then tautologically say they exist when we find they do affect behavior.
Based on her polity idea Jacob’s defines three levels of possible neighborhoods:
- your street
- the greater area of persons – around 100,000
- the entire city
This again is quite different than most of current social sciences. Census tracts and block groups are larger swaths than just one block. In very dense cities like NYC, census block groups are often the square defined by streets on either side, so they split apart people across the street from one another. Census tracts intentionally are made to contain around 8,000 people. For a counter-example criminologist, Ralph Taylor does think streets are neighborhood units. A hearsay paraphrase of his I recently heard was “looking out your front door, all that matters is how far you can see down the street in either direction”.
I think Jacob’s guesstimate of 100,000 may be partly biased from only thinking about giant megapolises. Albany itself has only around 100,000 residents – so it is either streets or the whole city per her definition. Although I can’t argue much about smaller areas having little to no political capital to accomplish specific goals.
In some of the surveys I have participated in they have asked the question about how you define your neighborhood. Here are the responses for two different samples (from the same city at two different time points) for an example:
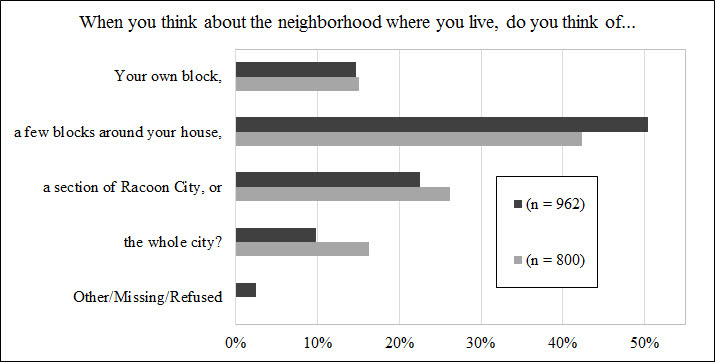
I think the current approach – that neighborhoods are defined by their coefficients on the right hand side of regression models is untenable in the end – based on ideas that are derivatives of the work in my dissertation. Mainly that discrete neighborhood boundaries are a fiction of social scientists.