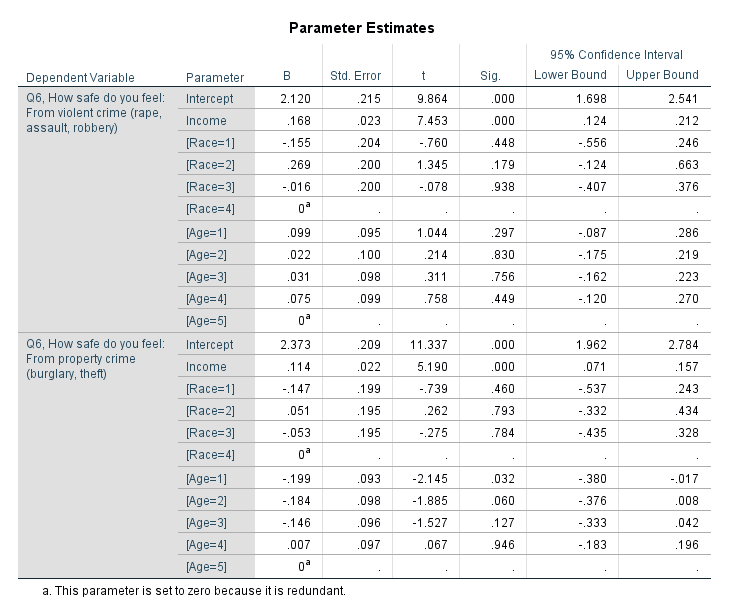
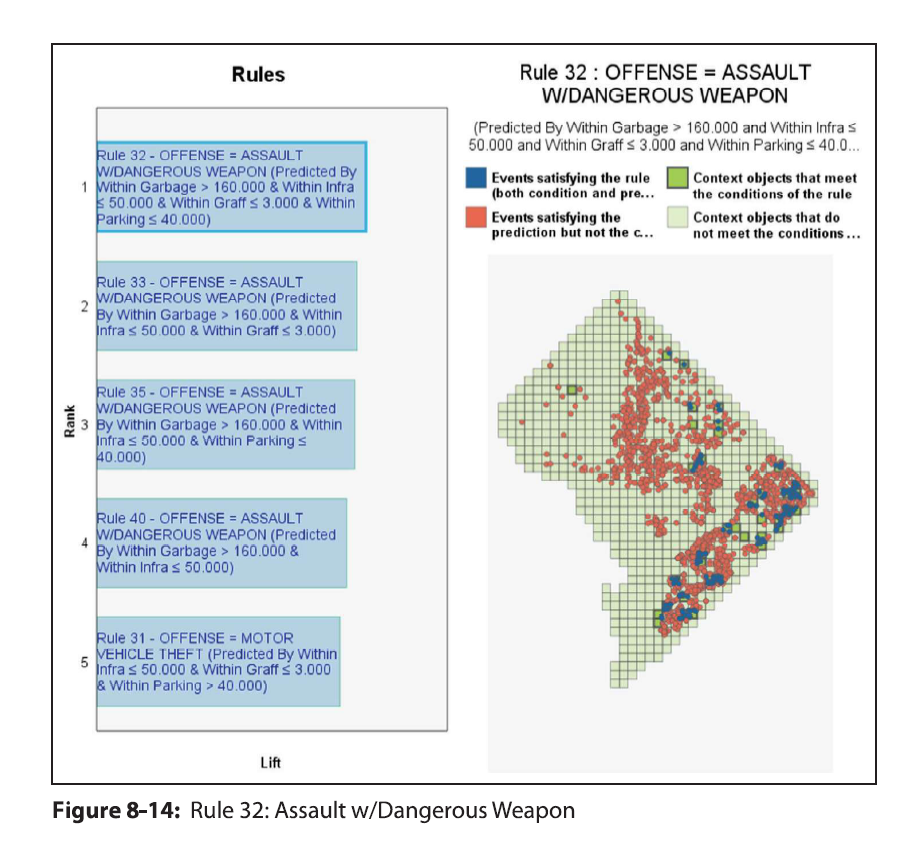
Heatmap is a visualization term that gets used in a few different circumstances, but here I mean a regular grid in which you use color to indicate particular values. Here is an example from Nathan Yau via FlowingData:
They are often not the best visualization to use to evaluate general patterns, but they offer a mix of zooming into specific individuals, as well as to identify overall trends. In particular I like using them to look at missing data patterns in surveys in SPSS, which I will show an example of in this blog post. Here I am going to use a community survey for Dallas in 2016. The original data can be found here, and the original survey questions can be found here. I’ve saved that survey as an SPSS file you can access at this link. (The full code in one sps syntax file is here.)
So first I am going to open up the data file from online, and name the dataset DallasSurv16.
*Grab the data from online.
SPSSINC GETURI DATA
URI="https://dl.dropbox.com/s/5e07yi9hd0u5opk/Surv2016.sav?dl=0"
FILETYPE=SAV DATASET=DallasSurv16.
Here I am going to illustrate making a heatmap with the questions asking about fear of crime and victimization, the Q6 questions. First I am going to make a copy of the original dataset, as we will be making some changes to the data. I do this via the DATASET COPY function, and follow it up by activating that new dataset. Then I do a frequency to check out the set of Q6 items.
DATASET COPY HeatMap.
DATASET ACTIVATE HeatMap.
FREQ Q6_1Inyourneighborhoodduringthe TO Q69Fromfire.
From the survey instrument, the nine Q6 items have values of 1 through 5, and then a "Don’t Know" category labeled as 9. All of the items also have system missing values. First we are going to recode the system missing items to a value of 8, and then we are going to sort the dataset by those questions.
RECODE Q6_1Inyourneighborhoodduringthe TO Q69Fromfire (SYSMIS = 8)(ELSE = COPY).
SORT CASES BY Q6_1Inyourneighborhoodduringthe TO Q69Fromfire.
You will see the effect of the sorting the cases in a bit for our graph. But the idea about how to make the heatmap in the grammar of graphics is that in your data you have a variable that specifies the X axis, a variable for the Y axis, and then a variable for the color in your heatmap. To get that set up, we need to go from our nine separate Q6 variables to one variable. We do this in SPSS by using VARSTOCASES to reshape the data.
VARSTOCASES /MAKE Q6 FROM Q6_1Inyourneighborhoodduringthe TO Q69Fromfire /INDEX = QType.
So now every person who answered the survey has 9 different rows in the dataset instead of one. The original answers to the questions are placed in the new Q6 variable, and the QType variable is a number of 1 to 9. So now individual people will go on the Y axis, and each question will go on the X axis. But before we make the chart, we will add the meta-data in SPSS to our new Q6 and QType variables.
VALUE LABELS QType
1 'In your neigh. During Day'
2 'In your neigh. At Night'
3 'Downtown during day'
4 'Downtown at night'
5 'Parks during day'
6 'Parks at Night'
7 'From violent crime'
8 'From property crime'
9 'From fire'
.
VALUE LABELS Q6
8 "Missing"
9 "Don't Know"
1 'Very Unsafe'
2 'Unsafe'
3 'Neither safe or unsafe'
4 'Safe'
5 'Very Safe'
.
FORMATS Q6 QType (F1.0).
Now we are ready for our GGRAPH statement. It is pretty gruesome but just bare with me for a second.
TEMPORARY.
SELECT IF DISTRICT = 1.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=QType ID Q6
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
PAGE: begin(scale(800px,2000px))
SOURCE: s=userSource(id("graphdataset"))
DATA: QType=col(source(s), name("QType"), unit.category())
DATA: ID=col(source(s), name("ID"), unit.category())
DATA: Q6=col(source(s), name("Q6"), unit.category())
GUIDE: axis(dim(1), opposite())
GUIDE: axis(dim(2), null())
SCALE: cat(aesthetic(aesthetic.color.interior), map(("1", color.darkred),("2", color.red),("3", color.lightgrey),
("4", color.lightblue), ("5", color.darkblue), ("9", color.white), ("8", color.white)))
SCALE: cat(dim(2), sort.data(), reverse())
ELEMENT: polygon(position(QType*ID), color.interior(Q6), color.exterior(color.grey), transparency.exterior(transparency."0.7"))
PAGE: end()
END GPL.
EXECUTE.
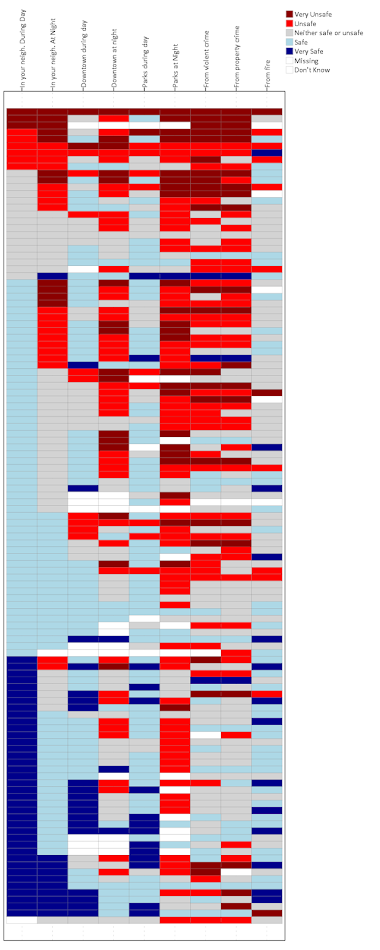
And this produces the chart,
So to start, normally I would use the chart builder dialog to make the skeleton for the GGRAPH code and update that. Here if you make a scatterplot in the chart dialog and assign the color it gets you most of the way there. But I will walk through some of the other steps.
TEMPORARY. and then SELECT IF – these two steps are to only draw a heatmap for survey responses for the around 100 individuals from council district 1. Subsequently the EXECUTE. command at the end makes it so the TEMPORARY command is over.- Then for in the inline GPL code,
PAGE: begin(scale(800px,2000px)) changes the chart dimensions to taller and skinnier than the default chart size in SPSS. Also note you need a corresponding PAGE: end() command when you use a PAGE: begin() command.
GUIDE: axis(dim(1), opposite()) draws the labels for the X axis on the top of the graph, instead of the bottom.GUIDE: axis(dim(2), null()) prevents drawing the Y axis, which just uses the survey id to displace survey responsesSCALE: cat(aesthetic maps different colors to each different survey response. Feeling safe are given blues, and not safe are given red colors. I gave neutral grey and missing white as well.SCALE: cat(dim(2), sort.data(), reverse()), this tells SPSS to draw the Y axis in the order in which the data are already sorted. Because I sorted the Q6 variables before I did the VARSTOCASES this sorts the responses with the most fear to the top.- The
ELEMENT: polygon( statement just draws the squares, and then specifies to color the interior of the squares according to the Q6 variable. I given the outline of the squares a grey color, but white works nice as well. (Black is a bit overpowering.)
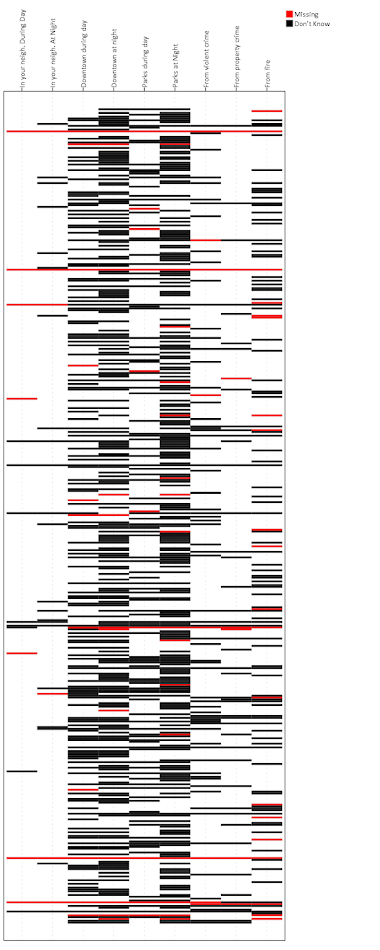
So now you have the idea. But like I said this can be hard to identify overall patterns sometimes. So sometimes I like to limit the responses in the graph. Here I make a heatmap of the full dataset (over 1,500 responses), but just look at the different types of missing data. Red is system missing in the original dataset, and Black is the survey filled in "Don’t Know".
*Missing data representation.
TEMPORARY.
SELECT IF (Q6 = 9 OR Q6 = 8).
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=QType ID Q6 MISSING = VARIABLEWISE
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
PAGE: begin(scale(800px,2000px))
SOURCE: s=userSource(id("graphdataset"))
DATA: QType=col(source(s), name("QType"), unit.category())
DATA: ID=col(source(s), name("ID"), unit.category())
DATA: Q6=col(source(s), name("Q6"), unit.category())
GUIDE: axis(dim(1), opposite())
GUIDE: axis(dim(2), null())
SCALE: cat(aesthetic(aesthetic.color.interior), map(("1", color.darkred),("2", color.red),("3", color.lightgrey),
("4", color.lightblue), ("5", color.darkblue), ("9", color.black), ("8", color.red)))
ELEMENT: polygon(position(QType*ID), color.interior(Q6), color.exterior(color.grey), transparency.exterior(transparency."0.7"))
PAGE: end()
END GPL.
EXECUTE.
You can see the system missing across all 6 questions happens very rarely, I only see three cases, but there are a ton of "Don’t Know" responses. Another way to simplify the data is to use small multiples for each type of response. Here is the first graph, but using a panel for each of the individual survey responses. See the COORD: rect(dim(1,2), wrap()) and then the ELEMENT statement for the updates. As well as making the size of the chart shorter and fatter, and not drawing the legend.
*Small multiple.
TEMPORARY.
SELECT IF DISTRICT = 1.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=QType ID Q6
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
PAGE: begin(scale(1000px,1000px))
SOURCE: s=userSource(id("graphdataset"))
DATA: QType=col(source(s), name("QType"), unit.category())
DATA: ID=col(source(s), name("ID"), unit.category())
DATA: Q6=col(source(s), name("Q6"), unit.category())
COORD: rect(dim(1,2), wrap())
GUIDE: axis(dim(1), opposite())
GUIDE: axis(dim(2), null())
GUIDE: legend(aesthetic(aesthetic.color.interior), null())
SCALE: cat(aesthetic(aesthetic.color.interior), map(("1", color.darkred),("2", color.red),("3", color.lightgrey),
("4", color.lightblue), ("5", color.darkblue), ("9", color.white), ("8", color.white)))
SCALE: cat(dim(2), sort.data(), reverse())
ELEMENT: polygon(position(QType*ID*Q6), color.interior(Q6), color.exterior(color.grey), transparency.exterior(transparency."0.7"))
PAGE: end()
END GPL.
EXECUTE.
You technically do not need to reshape the data using VARSTOCASES at first to make these heatmaps (there is an equivalent VARSTOCASES command within GGRAPH you could use), but this way is simpler in my opinion. (I could not figure out a way to use multiple response sets to make these non-aggregated charts, so if you can figure that out let me know!)
The idea of a heatmap can be extended to much larger grids — basically any raster graphic can be thought of as a heatmap. But for SPSS you probably do not want to make heatmaps that are very dense. The reason being SPSS always makes its charts in vector format, you cannot tell it to just make a certain chart a raster. So a very dense heatmap will take along time to render. But I like to use them in some situations as I have shown here with smaller N data in SPSS.
Also off-topic, but I may be working on a cook-book with examples for SPSS graphics. If I have not already made a blog post let me know what you would examples you would like to see!