We are homeschooling the kiddo at the moment (the plunge was reading by Bryan Caplan’s approach, and seeing with online schooling just how poor middle school education was). Wife is going through AP biology at the moment, and we looked up various job info on biomedical careers. Subsequently came across this gem of a map of MSA estimates from the Bureau of Labor Stats (BLS) Occupational Employment and Wage Stats series (OES).
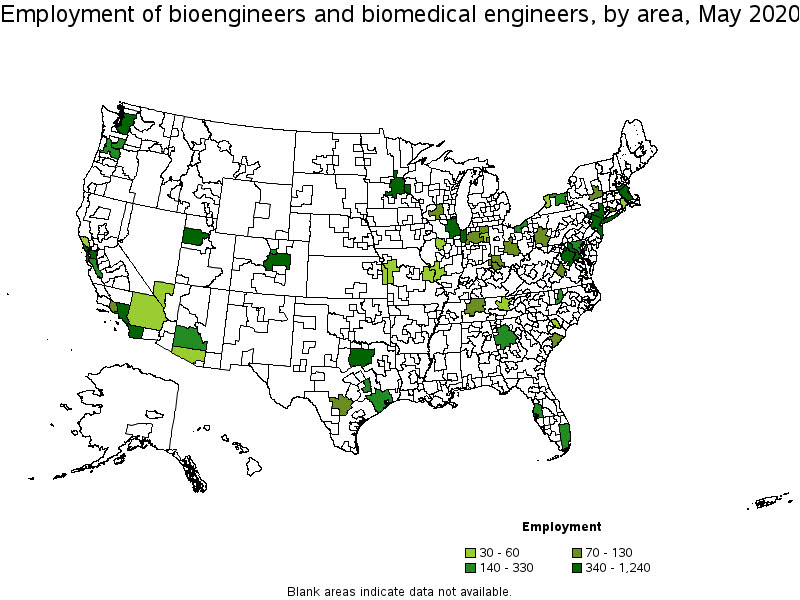
I was actually mapping some metro stat areas (MSAs) at work the other day, and these are just terrifically bad geo areas to show via a choropleth map. All choropleth maps have the issue of varying size areas, but I never realized having somewhat regular borders (more straight lines) makes the state and county maps not so bad – these MSA areas though are tough to look at. (Wife says it scintillates for her if she looks too closely.)
There are various incredibly tiny MSAs next to giant ones that you will just never see in these maps (no matter what color scheme you use). Nevada confused for me quite a bit, until I zoomed in to see that there are 4 areas, Reno is just a tiny squib.
Another example is Boulder above Denver. (Look closely at the BLS map I linked, you can just make out Boulder if you squint, but I cannot tell what color it corresponds to in the legend.) The outline heavy OES maps, which are mostly missing data, are just hopeless to display like this effectively. Reno could be the hottest market for whatever job, and it will always be lost in this map if you show employment via the choropleth approach. So of course I spent the weekend hacking together some maps in python and folium.
The BLS has a public API, but I was not able to find the OES stats in that. But if you go through the motions of querying the data and muck around in the source code for those queries, you can see they have an undocumented API call to generate json to fill the tables. Then using this tool to convert the json calls to python (thank you Hacker News), I was able to get those tables into python.
I have these functions saved on github, so check out that source for the nitty gritty. But just here quickly, here is a replicated choropleth map, showing the total employees for bio jobs (you can go to here to look up the codes, or run my function bls_maps.ocodes() to get a pandas dataframe of those fields).
# Creating example bls maps
from bls_geo import *
# can check out https://www.bls.gov/oes/current/oes_stru.htm
bio = '172031'
bio_stats = oes_geo(bio)
areas = get_areas() # this takes a few minutes
state = state_albers()
geo_bio = merge_occgeo(bio_stats,areas)
ax = geo_bio.plot(column='Employment',cmap='inferno',legend=True,zorder=2)
state.boundary.plot(ax=ax,color='grey',linewidth=0.5,zorder=1)
ax.set_ylim(0.1*1e6,3.3*1e6)
ax.set_xlim(-0.3*1e7,0.3*1e7) # lower 48 focus (for Albers proj)
ax.set_axis_off()
plt.show()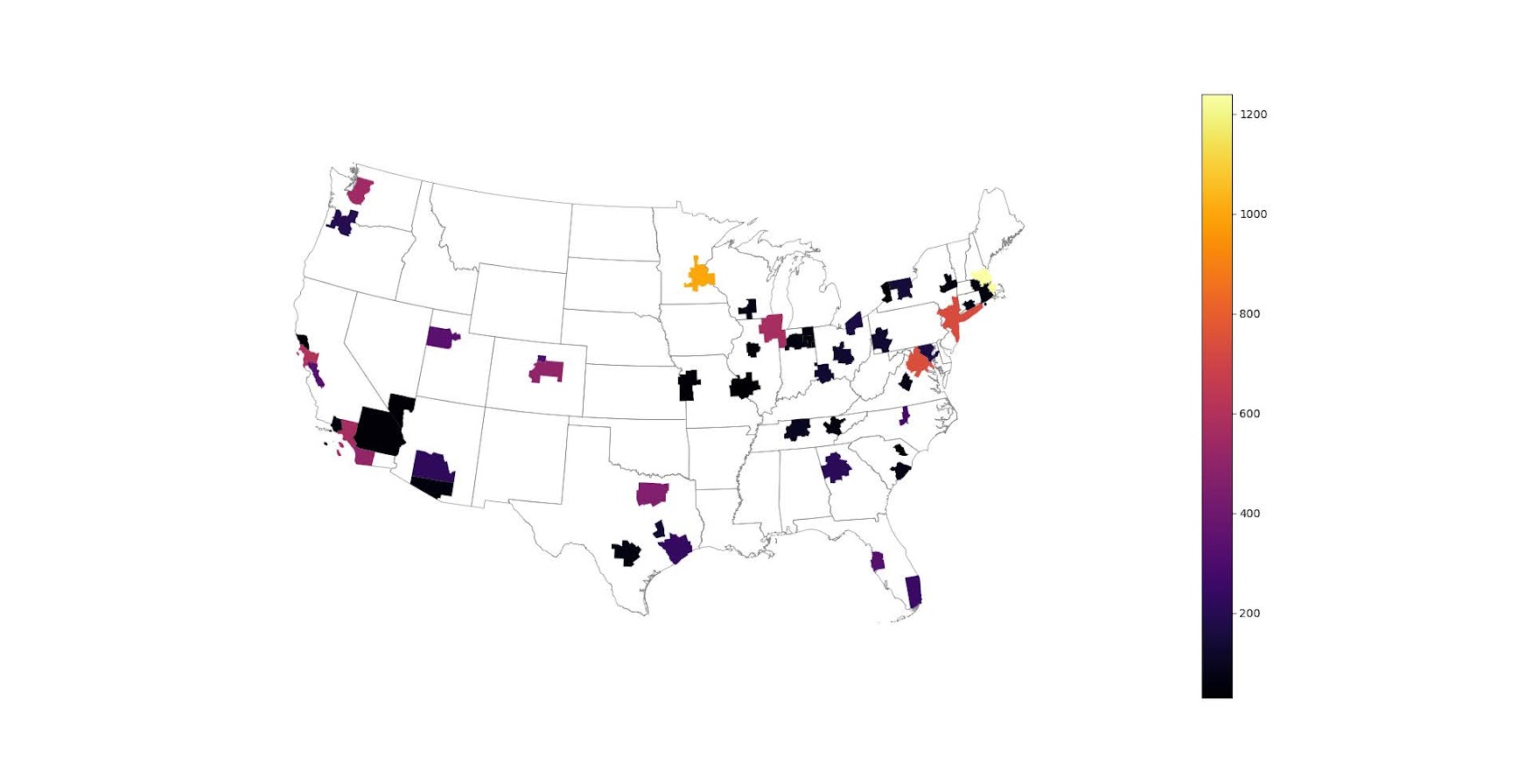
And that is not much better than BLSs version. For this data, if you are just interested in looking up or seeing the top metro areas, just doing a table, e.g. above geo_bio.to_excel('biojobs.xlsx'), works just as well as a map.
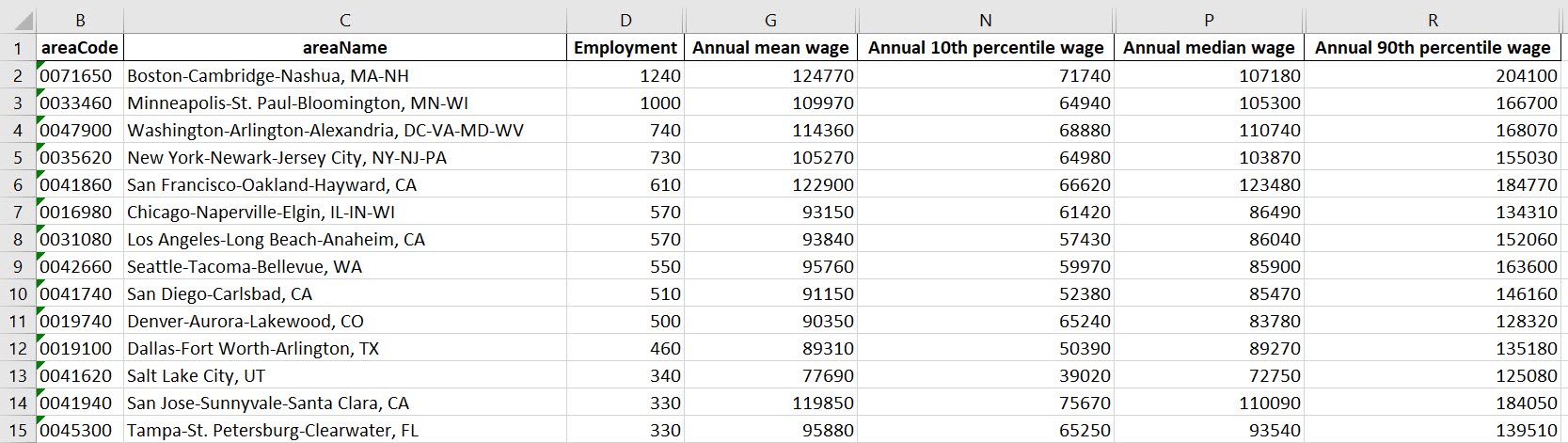
So I was surprised to see Minneapolis pop up at the top of that list (and also surprised Raleigh doesn’t make the list at all, but Durham has a few jobs). But if you insist on seeing spatial trends, I prefer to go the approach of mapping proportion or graduate circles, placing the points at the centroid of the MSA:
att = ['areaName','Employment','Location Quotient','Employment per 1,000 jobs','Annual mean wage']
form = ['',',.0f','.2f','.2f',',.0f']
map_bio = fol_map(geo_bio,'Employment',['lat', 'lon'],att,form)
#map_bio.save('biomap.html')
map_bio #if in jupyter can render like this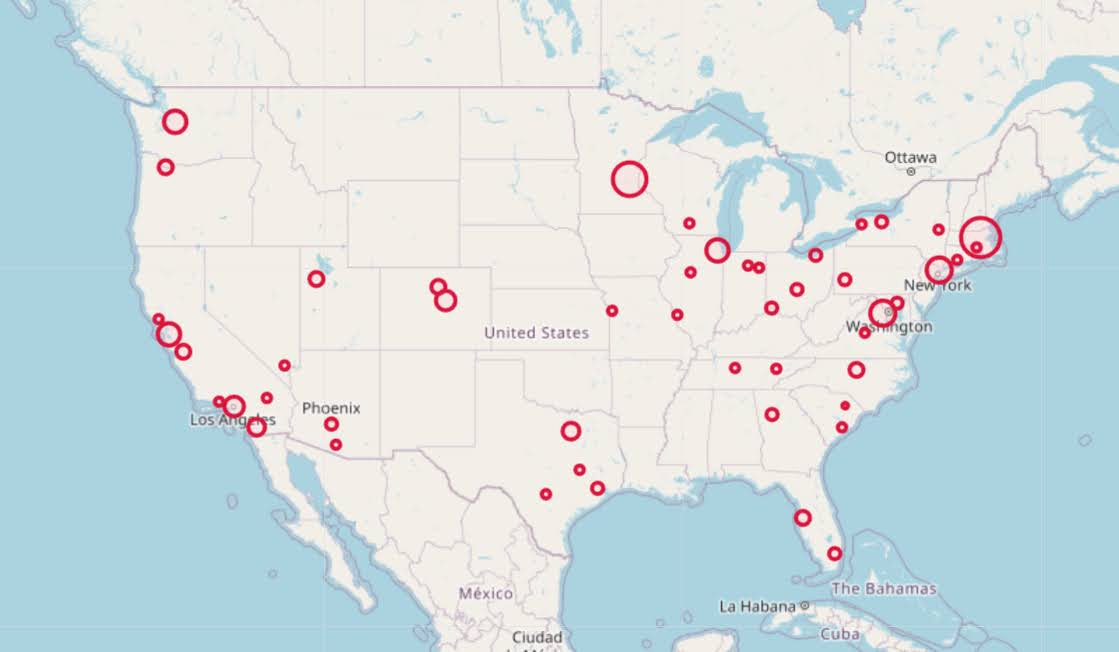
I am too lazy to make a legend, you can check out nbviewer to see an interactive Folium map, which I have tool tips (similar to the hover for the BLS maps).

Forgive my CSS/HTML skills, not sure how to make nicer popups. So you lose the exact areas these MSA cover in this approach, but I really only expect a general sense from these maps anyway.
These functions are general enough for whatever wage series you want (although these functions will likely break when the 2021 data comes out). So here is the OES table for data science jobs:
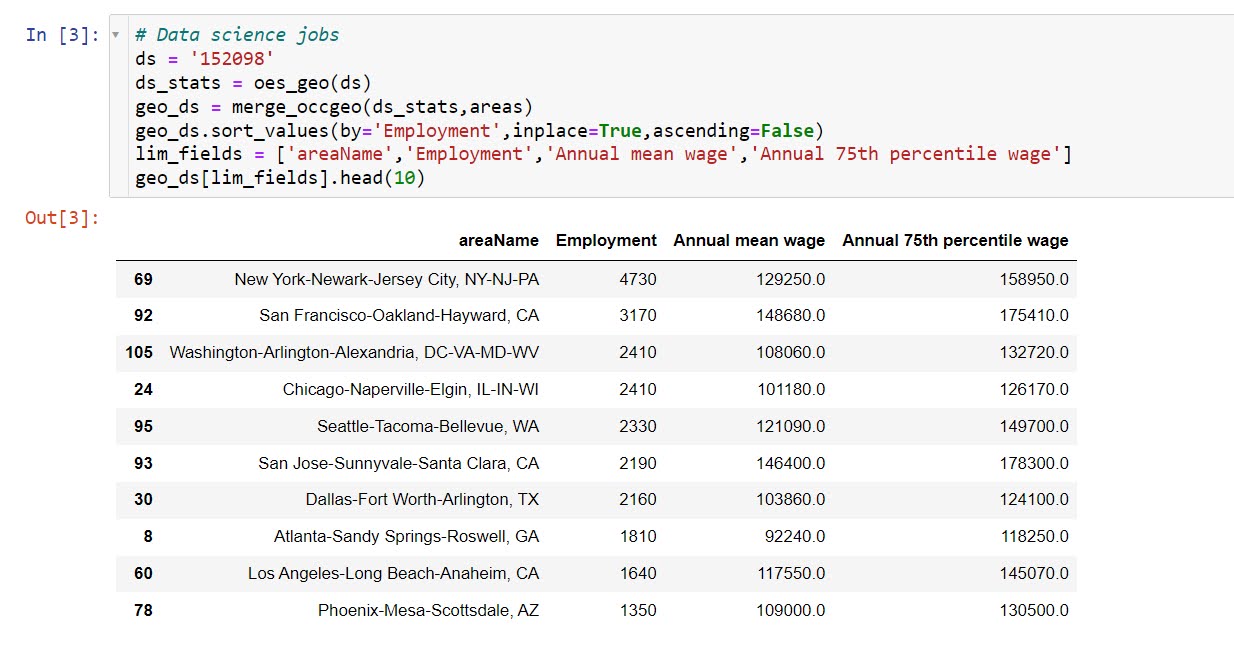
I feel going for the 90th percentile (mapping that to the 10 times programmer) is a bit too over the top. But I can see myself reasonably justifying 75th percentile. (Unfortunately these agg tables don’t have a way to adjust for years of experience, if you know of a BLS micro product I could do that with let me know!). So you can see here the somewhat inflated salaries for the SanFran Bay area, but not as inflated as many might have you think (and to be clear, these are for 2020 survey estimates).
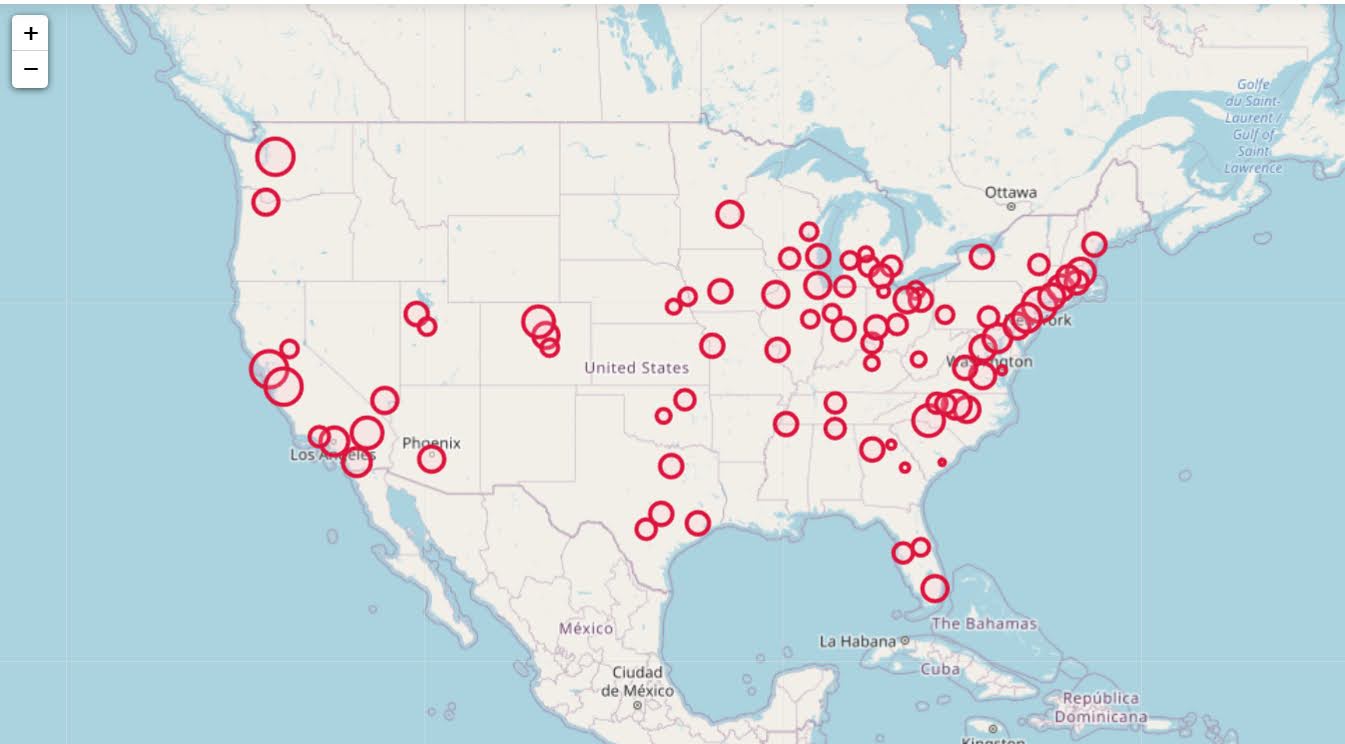
If we look at map of data science jobs, varying the circles by that 75th annual wage percentile, it looks quite uniform. What happens is we have some real low outliers (wages under 70k), resulting in tiny circles (such as Athen’s GA). Most of the other metro regions though are well over 100k.
In more somber news, those interactive maps are built using Leaflet as the backend, which was create by a Ukranian citizen, Vladimir Agafonkin. We can do amazing things with open source code, but we should always remember it is on the backs of someones labor we are able to do those things.






")