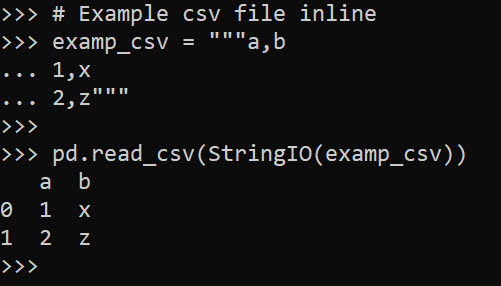
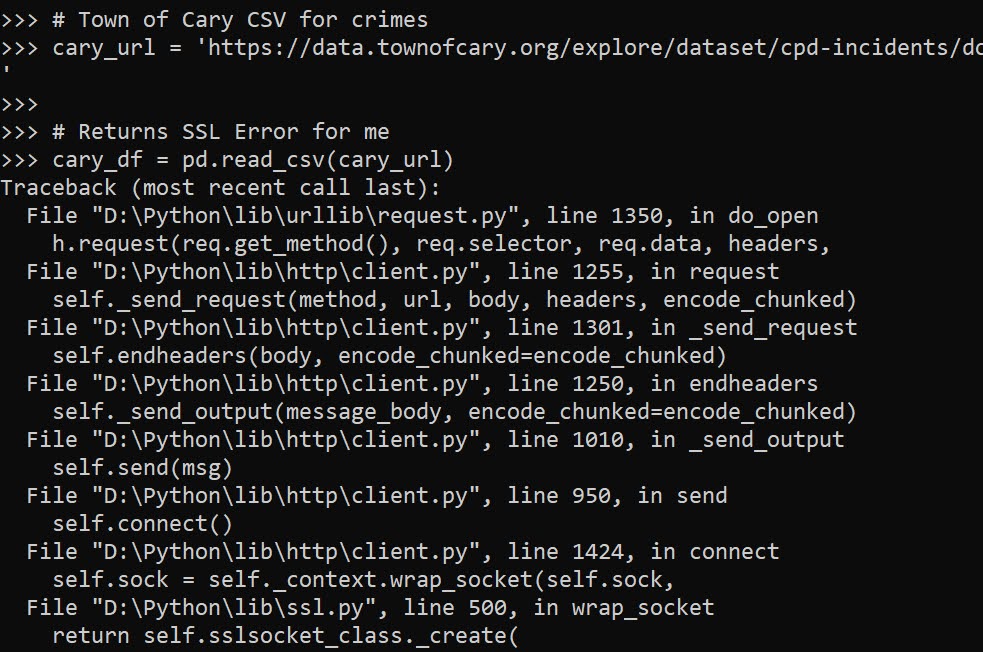
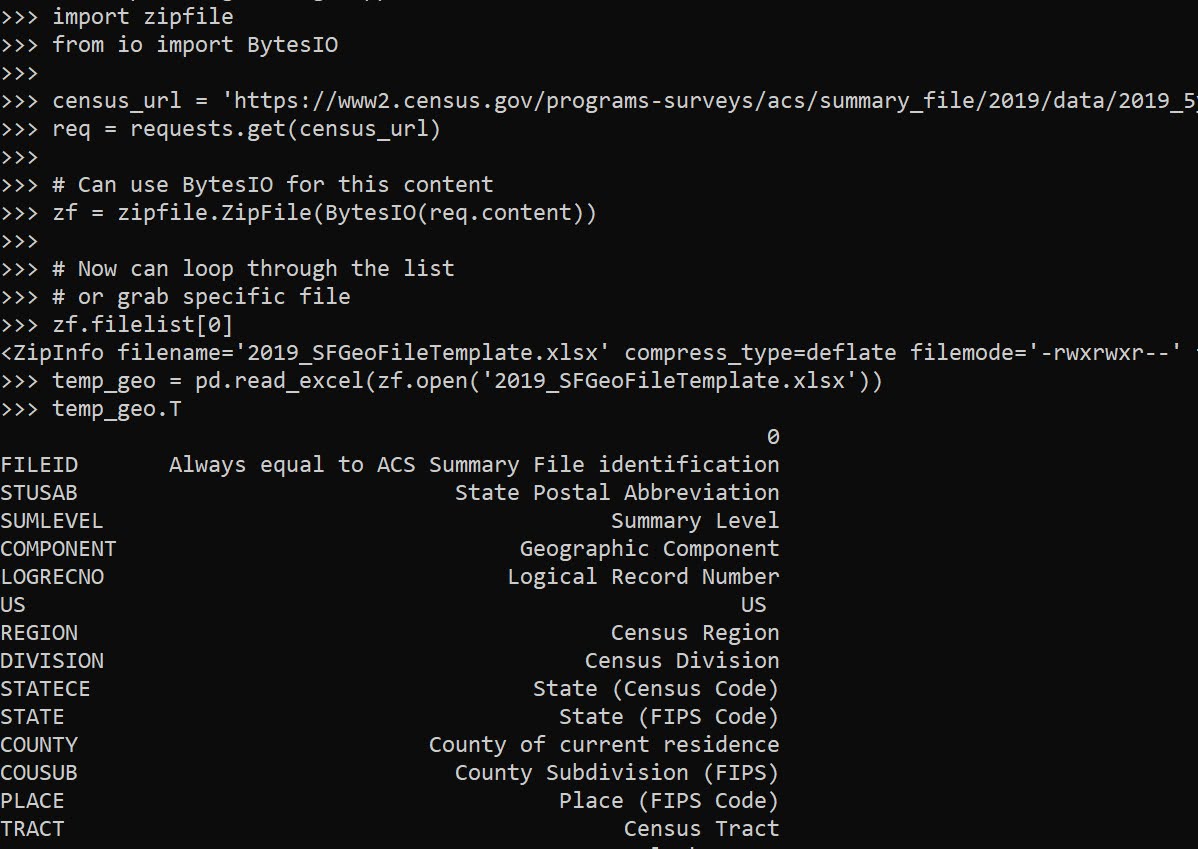
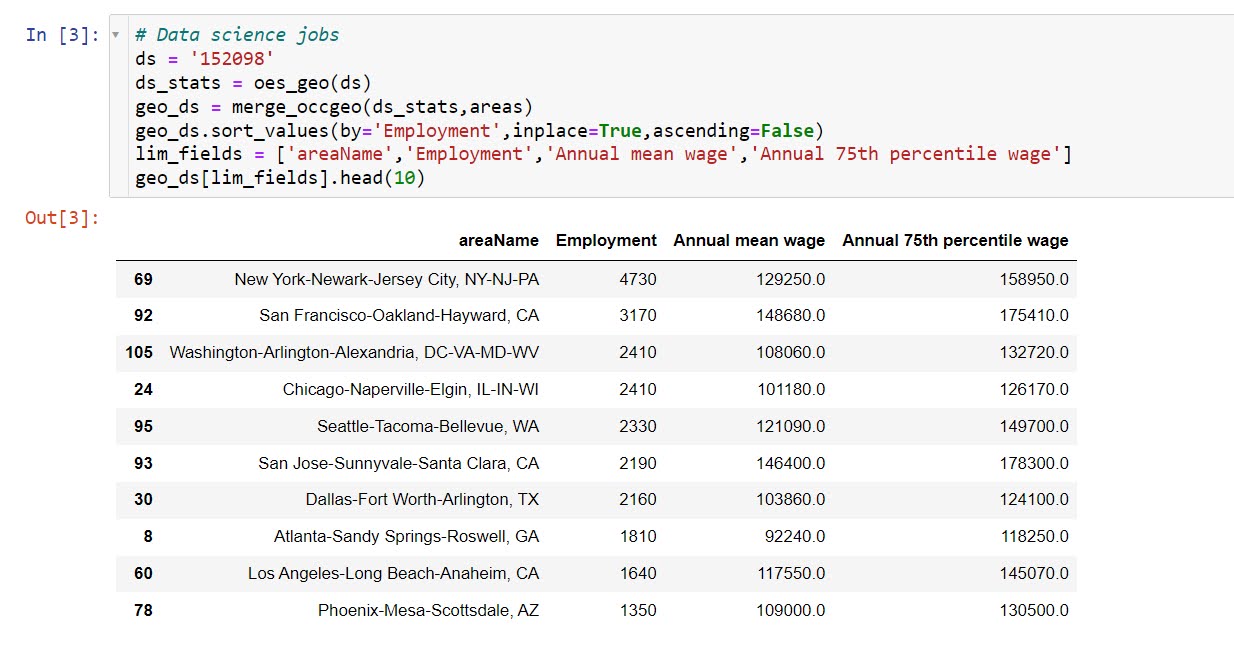
So I have a few posts in the past on scraping data. One shows downloading and parsing structured PDFs, almost all of the rest though use either JSON API backends, or just grab the HTML data directly. These are fairly straightforward to deal with in python. You generate the url directly, use requests, and then just parse the returned HTML however you want.
Came across a situation recently though where I needed to interact with the webpage. I figured a blog post to illustrate the process would be good. (For both myself and others!) So here I will illustrate entering data into San Antonio’s historical calls for service asp application (which I have seen several PDs use in the past).
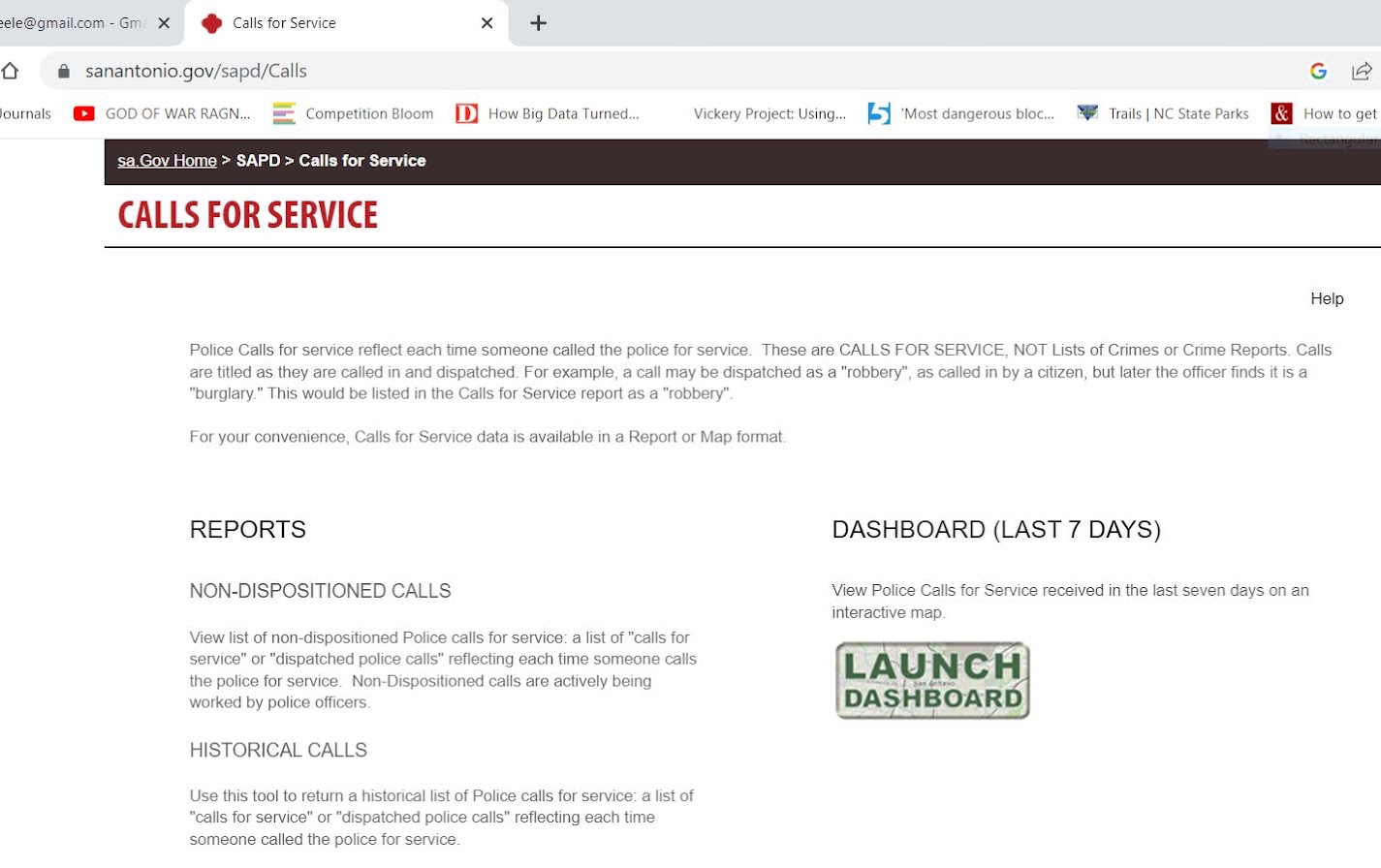
It is tough for me to give general advice about scraping, it involves digging into the source code for a website. Here if you click on the Historical Calls button, the url stays the same, but presents you with a new form page to insert your search parameters:
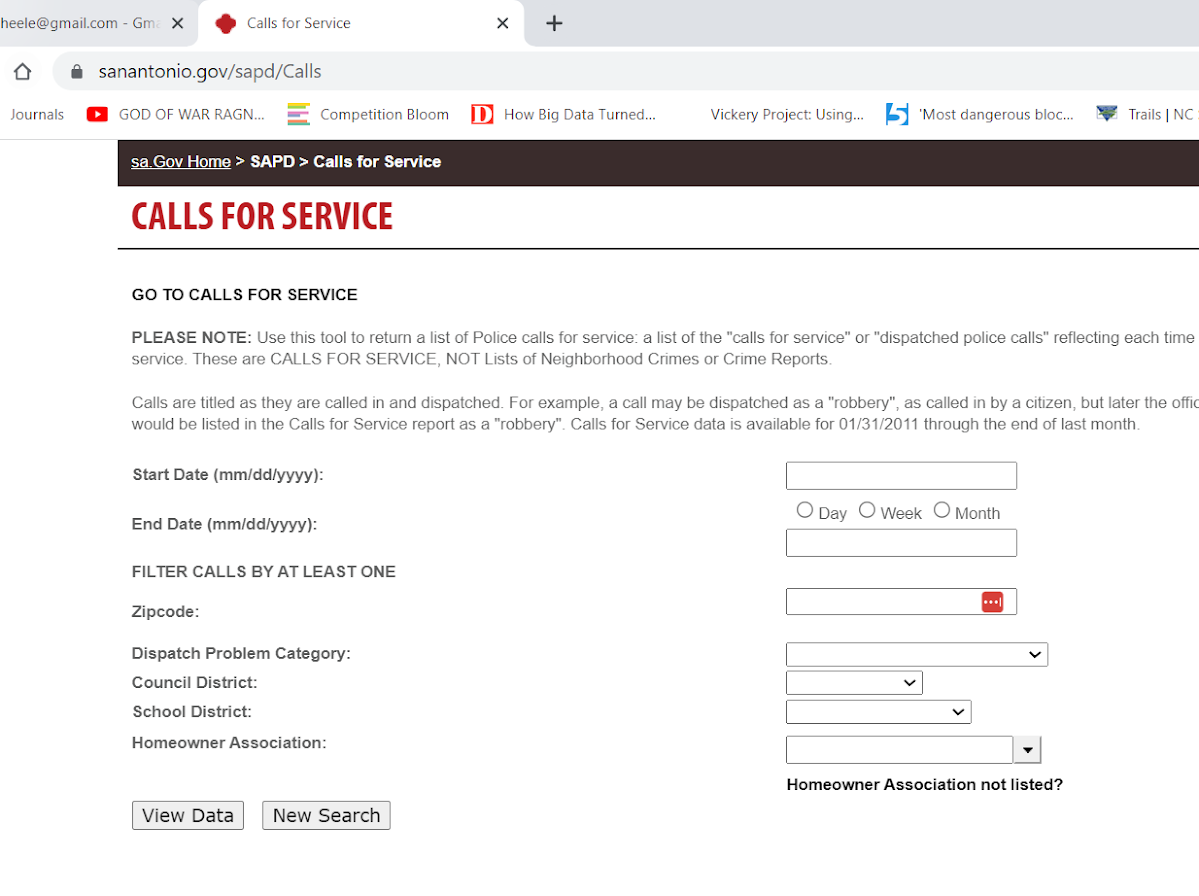
This is a bit of a red-herring though, it ends up being the entire page is embedded in what is called an i-frame, so the host URL stays the same, but the window inside the webpage changes. On the prior opening page, if you hover over the link for Historical Calls you can see it points to https://webapp3.sanantonio.gov/policecalls/Reports.aspx, so that is page we really need to pay attention to.
So for general advice, using Chrome to view a web-pages source html, you can right-click and select view-source:
And you can also go into the Developer tools to check out all the items in a page as well.
Typically before worrying about selenium, I study the network tab in here. You want to pay attention to the items that take the longest/have the most data. Typically I am looking for JSON or text files here if I can’t scrape the data directly from the HTML. (Example blog posts grabbing an entire dump of data here, and another finding a hidden/undocumented JSON api using this approach.) Here is an example network call when inputting the search into the San Antonio web-app.
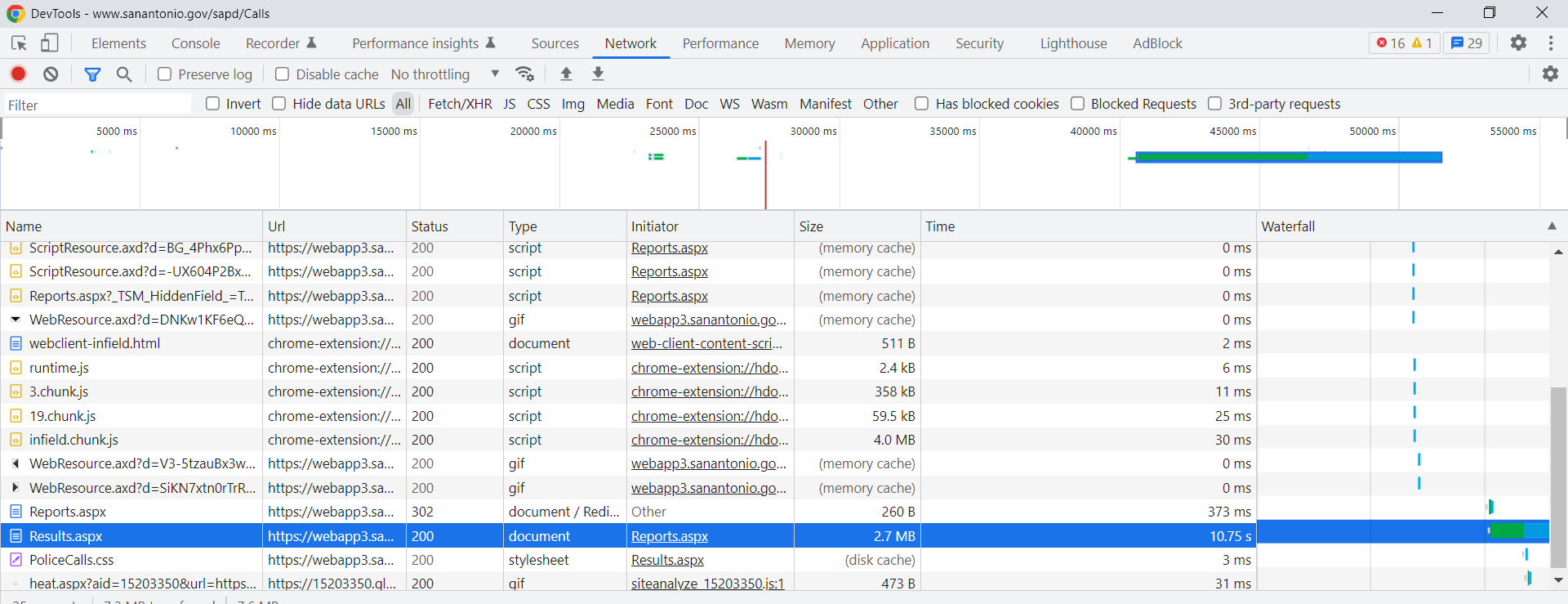
The data is all being transmitted inside of aspx application, not via JSON or other plain text files (don’t take my terminology here as authoritative, I really know near 0% about servers). So we will need to use selenium here. Using python you can install the selenium library, but you also need to download a driver (here I use chrome), and then wherever you save that exe file, add that location to your PATH environment variable.
Now you are ready for the python part.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import Select
import pandas as pd
# Setting Chrome Options
chrome_options = Options()
#chrome_options.add_argument("-- headless")
chrome_options.add_argument("--window-size=1920,1080")
chrome_options.add_argument("log-level=3")
# Getting the base page
driver = webdriver.Chrome(options=chrome_options)
base_url = "https://webapp3.sanantonio.gov/policecalls/Reports.aspx"
driver = webdriver.Chrome(options=chrome_options)
driver.get(base_url)Once you run this code, you will see a new browser pop-up. This is great for debugging, but once you get your script finalized, you can see I commented out a line to run in headerless (so it doesn’t bug you by flashing up the browser on your screen).
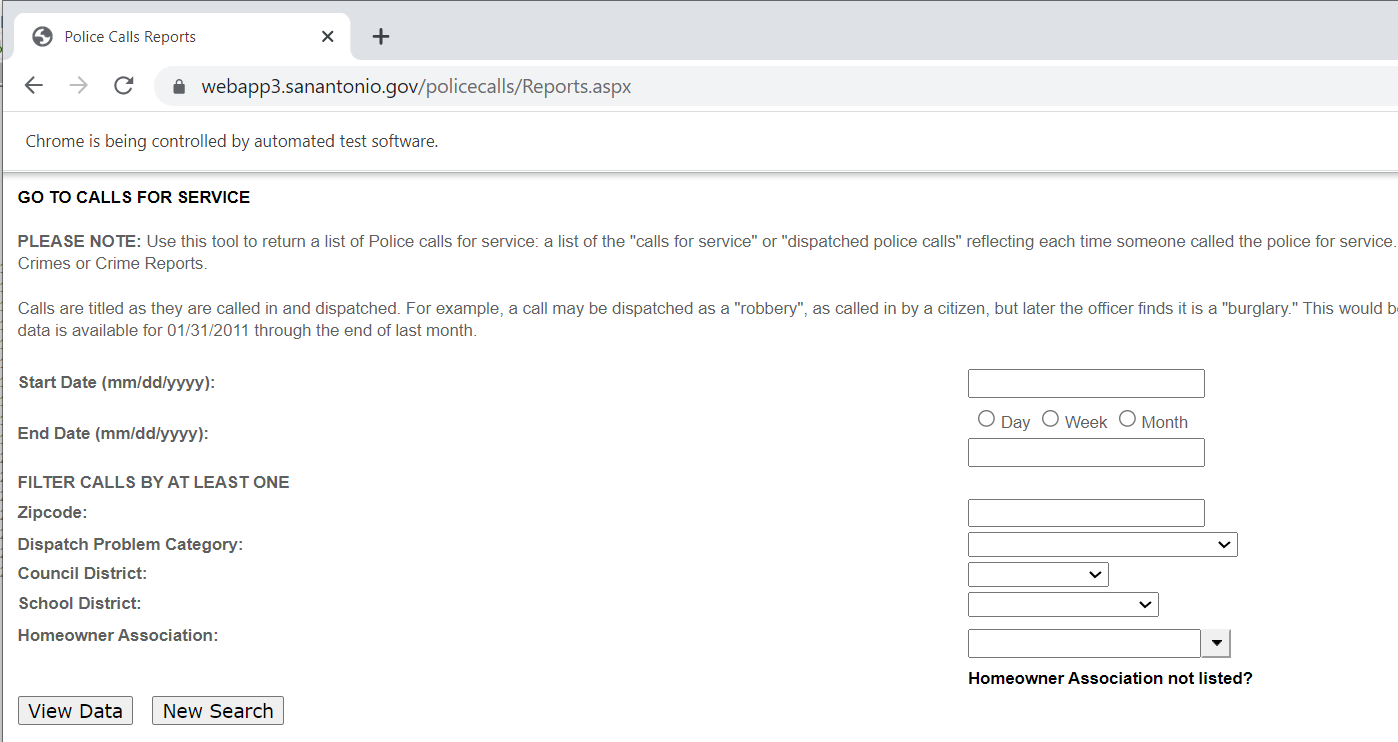
Now typically what I do is look at the HTML source (like I showed earlier), and then search for the input buttons in HTML. We are trying to figure out the elements we need to insert the data for us to submit a search. Here is the first input for an item we care about, the begin date of the search.
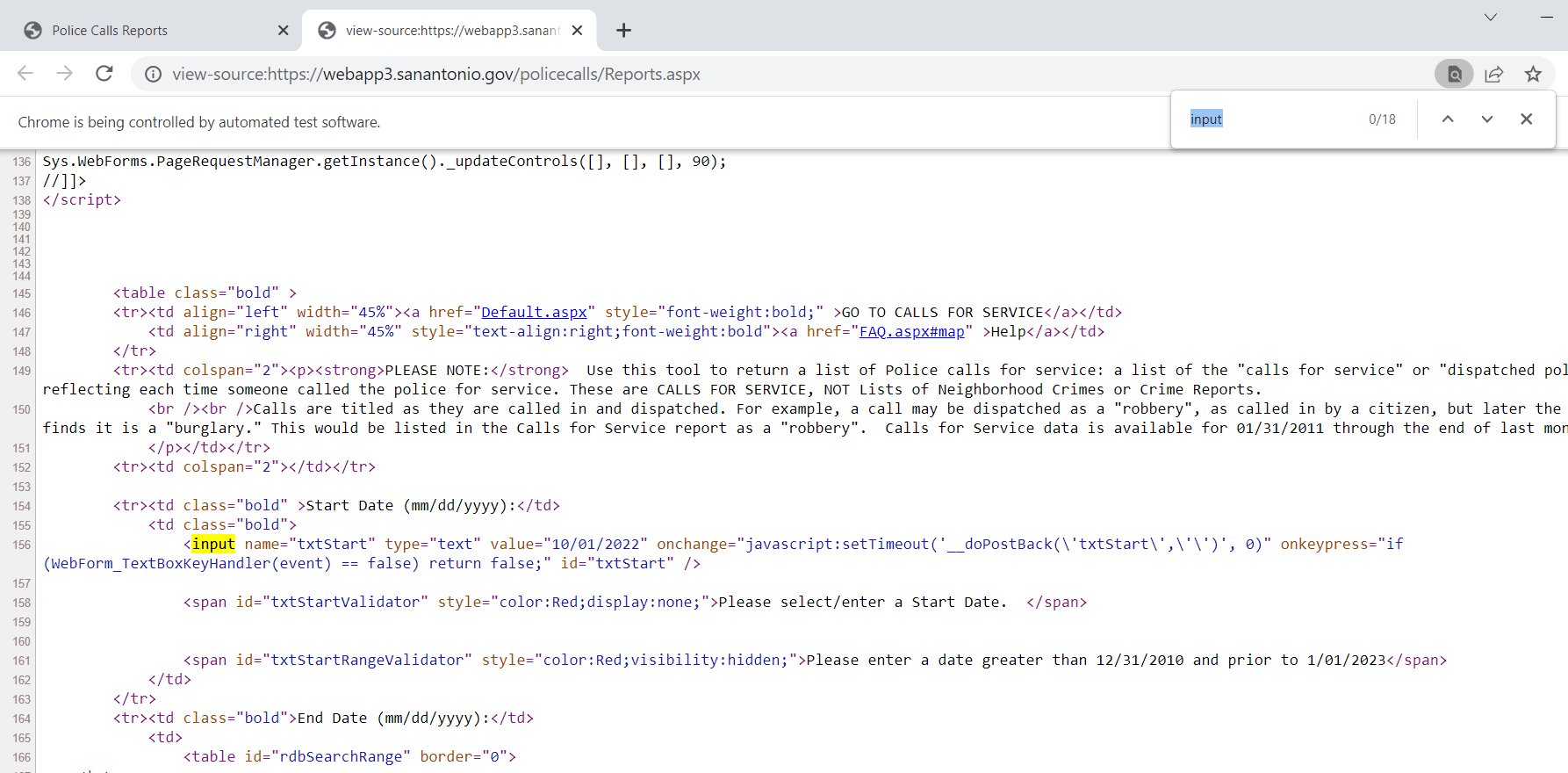
Now we can insert our own date by grabbing the element from the web-page. I grab it here by the “id” attribute in the HTML (many tutorials use xpath, which I am not as familiar with, but at least for these aspx apps what I show works fine). For dates that have a validation stage, you need to not only .send_keys, but to also submit to get past the date validation.
# Inserting date field for begin date
from_date = driver.find_element("id", "txtStart")
from_date.send_keys("10/01/2022")
from_date.submit()Once you run that code you can actually view the web-page, and see that your date is entered! Now we need to do the same thing for the end date. Then we can put in a plain text zipcode. Since this does not have validation, we do not need to submit it.
# Now for end date
end_date = driver.find_element("id", "txtEndDate")
end_date.send_keys("10/02/2022")
end_date.submit()
# Now inserting text for zipcode
zip = driver.find_element("id", "txtZipcode")
zip.send_keys("78207")
# Sometimes need to clear, zip.clear()I have a note there on clearing a text box. Sometimes websites have pre-filled options. Sometimes web-sites also do not like .clear(), and you can simulate backspace keystrokes directly. This website does not like it if you clear a date-field for example.
Now the last part, I am going to select a drop-down. If you go into the HTML source again, you can see the list of options.
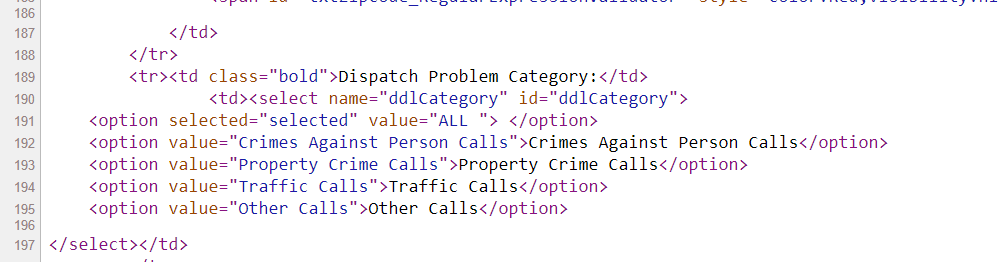
And now we can use the Select function I imported at the beginning to select a particular element of that drop-down. Here I select the crimes against persons.
# Now selecting dropdown
crime_cat = driver.find_element("id", "ddlCategory")
crime_sel = Select(crime_cat)
crime_sel.select_by_visible_text("Crimes Against Person Calls")Many of these applications have rate limits, so you need to limit the search to tiny windows and subsets, and then loop over the different sets you want to grab all of the data. (Being nice and using time.sleep() between calls to get the results.
Now we are ready to submit the query. The same way you can enter in text into input forms, buttons you can click are also labeled as inputs in the HTML. Here I find the submit button, and then .click() that button. (If there is a direct button to download CSV or some other format, it may make sense to click that button.)
# Now can find the View Data button and submit
view_data = driver.find_element("id", "btnSearch")
view_data.click()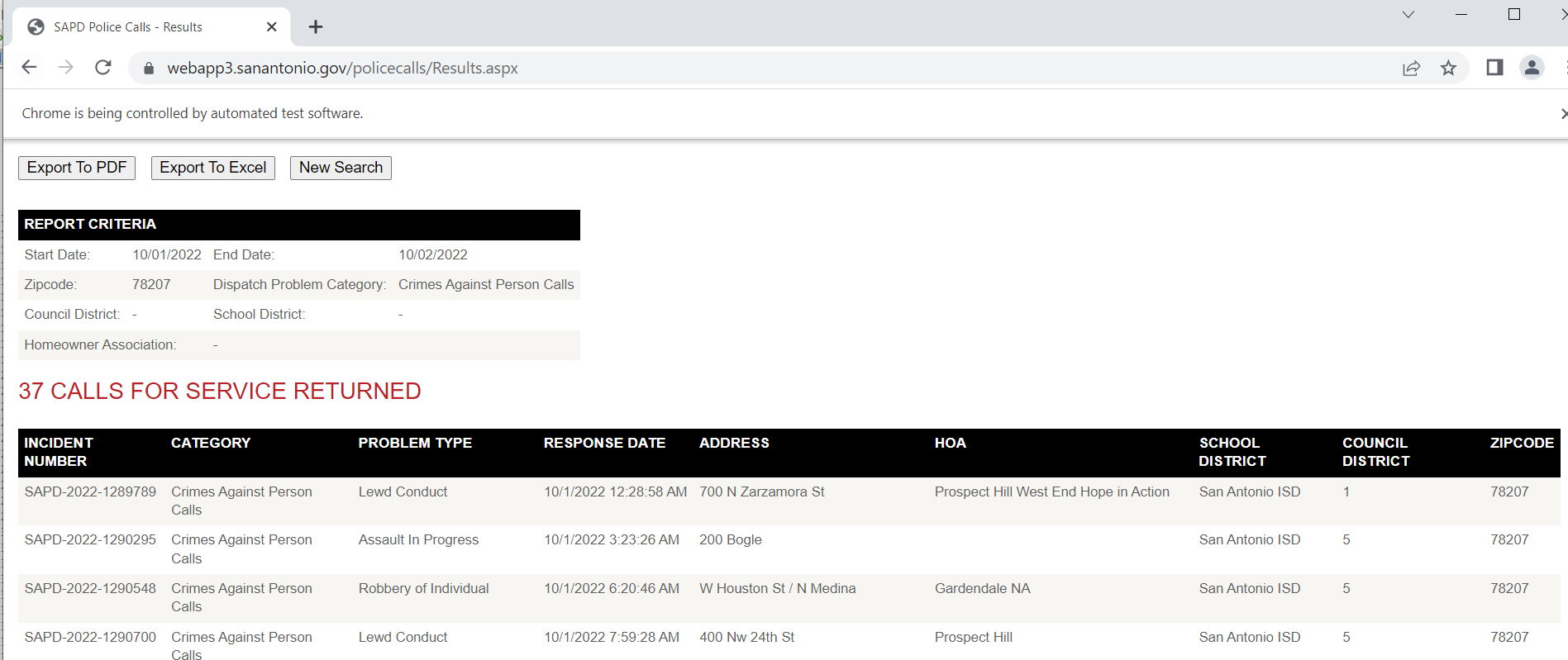
Now that we have our web-page, we can get the HTML source directly and then parse that. Pandas has a nice method to grab tables, and this application is actually very nicely formatted. (I tend to not use this, as many webpages have some very bespoke tables that are hard to grab directly like this). This method grabs all the tables in the web-page by default, here I just want the calls for service table, which has an id of "gvCFS", which I can pass into the pandas .read_html function.
# Pandas has a nice option to read tables directly
html = driver.page_source
cfs = pd.read_html(html, attrs={"id":"gvCFS"})[0]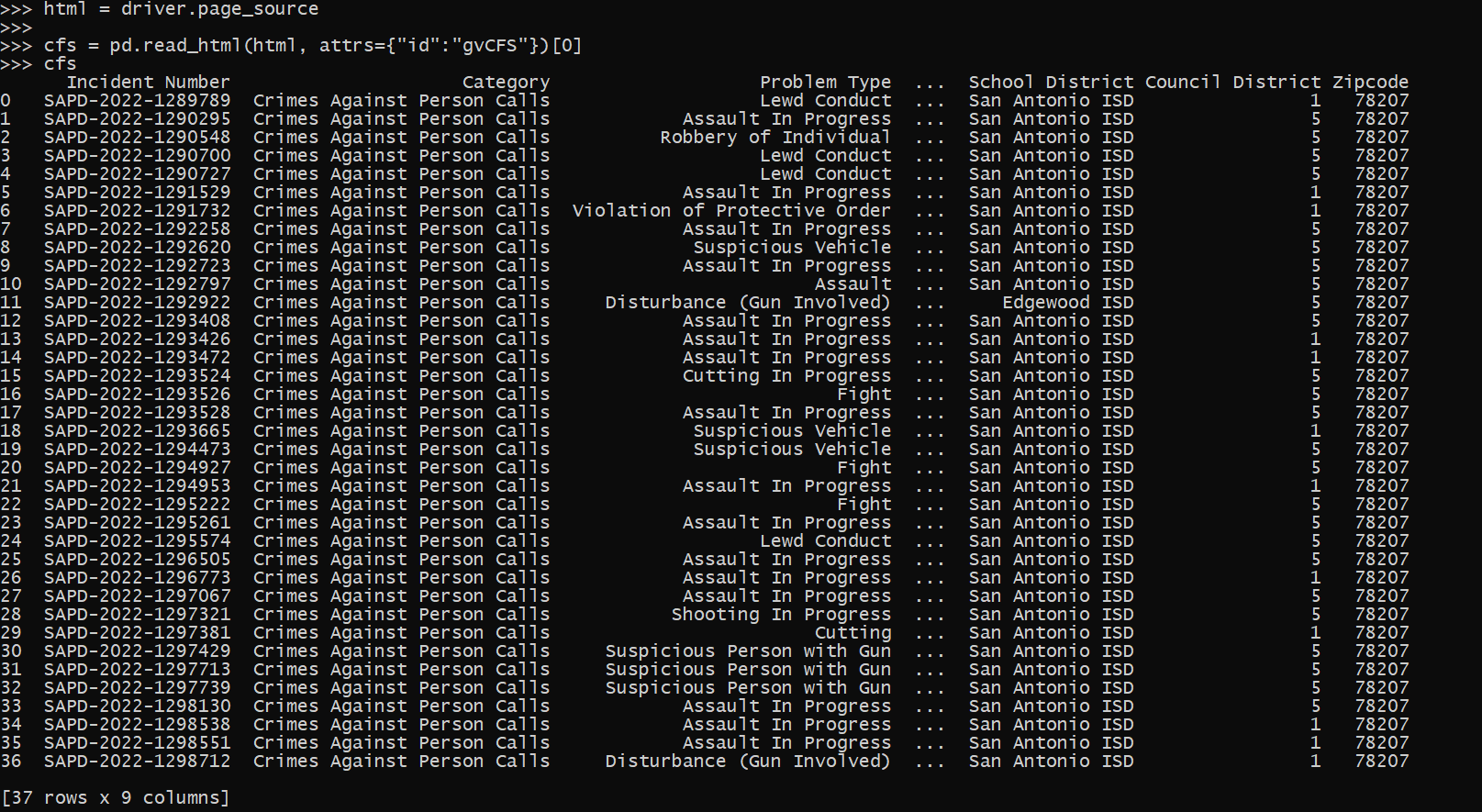
And that shows grabbing a single result. Of course to scrape, you will need to loop over many days (and here different search selections), depending on what data you want to grab. Most of these applications have search limits, so if you do too large a search, will only return the first say 500 results. And San Antonio’s is nice because it returns as a single table in the web-page, most you need to page the results though as well. Which takes further scraping the data and interacting with the page. So it is more painful whenever you need to resort to selenium.
Sometimes pages will point to PDF files, and you can set Chrome’s options to download to a particular location in that scenario (and then use os.rename to name the PDF whatever you want after it is downloaded). You can basically do anything in selenium you can manually, it is often just a tricky set of steps to replicate in code.