Marisa Iati interviewed me for a few clips in a recent update of the WaPo data on officer involved fatal police shootings. I’ve written in the past the data are very consistent with a Poisson process, and this continues to be true.
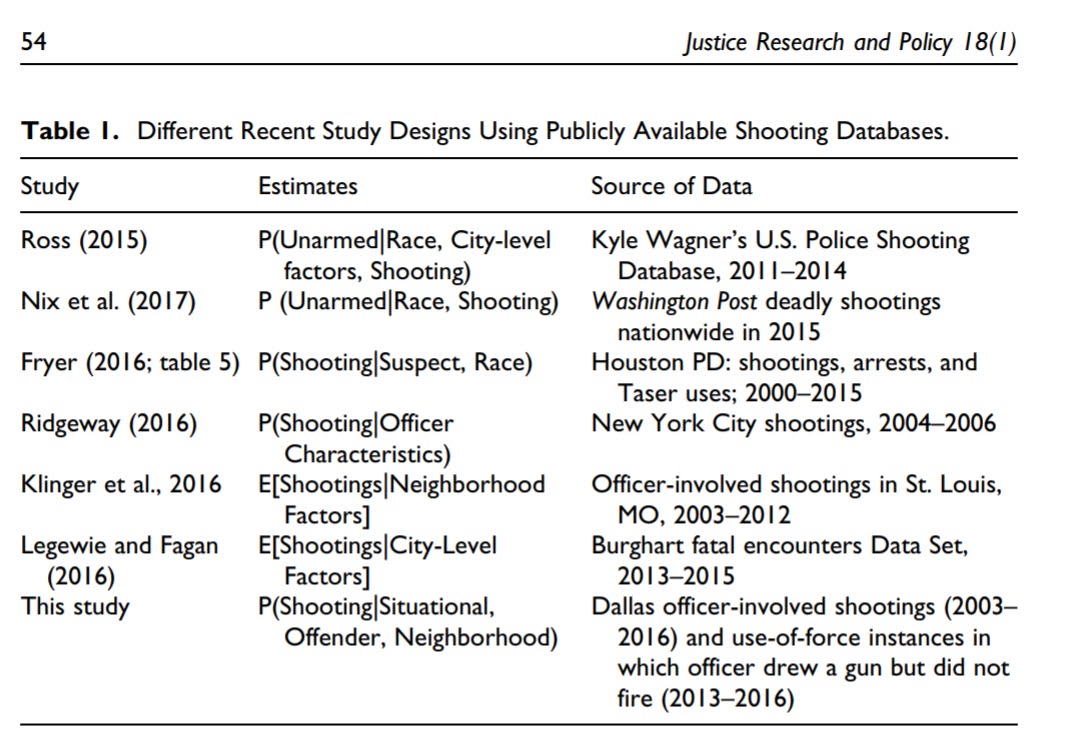
So first thing Marisa said was that shootings in 2021 are at 1055 (up from 1021 in 2020). Is this a significant increase? I said no off the cuff – I knew the average over the time period WaPo has been collecting data is around 1000 fatal shootings per year, so given a Poisson distribution mean=variance, we know the standard deviation of the series is close to sqrt(1000), which approximately equals 60. So anything 1000 plus/minus 60 (i.e. 940-1060) is within the typical range you would expect.
In every interview I do, I struggle to describe frequentist concepts to journalists (and this is no different). This is not a critique of Marisa, this paragraph is certainly not how I would write it down on paper, but likely was the jumble that came out of my mouth when I talked to her over the phone:
Despite setting a record, experts said the 2021 total was within expected bounds. Police have fatally shot roughly 1,000 people in each of the past seven years, ranging from 958 in 2016 to last year’s high. Mathematicians say this stability may be explained by Poisson’s random variable, a principle of probability theory that holds that the number of independent, uncommon events in a large population will remain fairly stagnant absent major societal changes.
So this sort of mixes up two concepts. One, the distribution of fatal officer shootings (a random variable) can be very well approximated via a Poisson process. Which I will show below still holds true with the newest data. Second, what does this say about potential hypotheses we have about things that we think might influence police behavior? I will come back to this at the end of the post,
R Analysis at the Daily Level
So my current ptools R package can do a simple analysis to show that this data is very consistent with a Poisson process. First, install the most recent version of the package via devtools, then you can read in the WaPo data directly via the Github URL:
library(devtools)
install_github("apwheele/ptools")
library(ptools)
url <- 'https://raw.githubusercontent.com/washingtonpost/data-police-shootings/master/fatal-police-shootings-data.csv'
oid <- read.csv(url,stringsAsFactors = F)Looking at the yearly statistics (clipping off events recorded so far in 2022), you can see that they are hypothetically very close to a Poisson distribution with a mean/variance of 1000, although perhaps have a slow upward trend over the years.
# Year Stats
oid$year <- as.integer(substr(oid$date,1,4))
year_stats <- table(oid$year)
print(year_stats)
mean(year_stats[1:7]) # average of 1000 per year
var(year_stats[1:7]) # variance just under 1000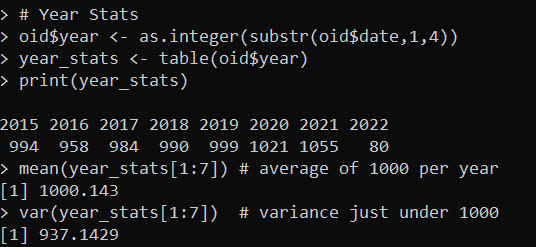
We can also look at the distribution at shorter time intervals, here per day. First I aggregat the data to the daily level (including 0 days), second I use my check_pois function to get the comparison distributions:
#Now aggregating to count per day
oid$date_val <- as.Date(oid$date)
date_range <- paste0(seq(as.Date('2015-01-01'),max(oid$date_val),by='days'))
day_counts <- as.data.frame(table(factor(oid$date,levels=date_range)))
head(day_counts)
pfit <- check_pois(day_counts$Freq, 0, 10, mean(day_counts$Freq))
print(pfit)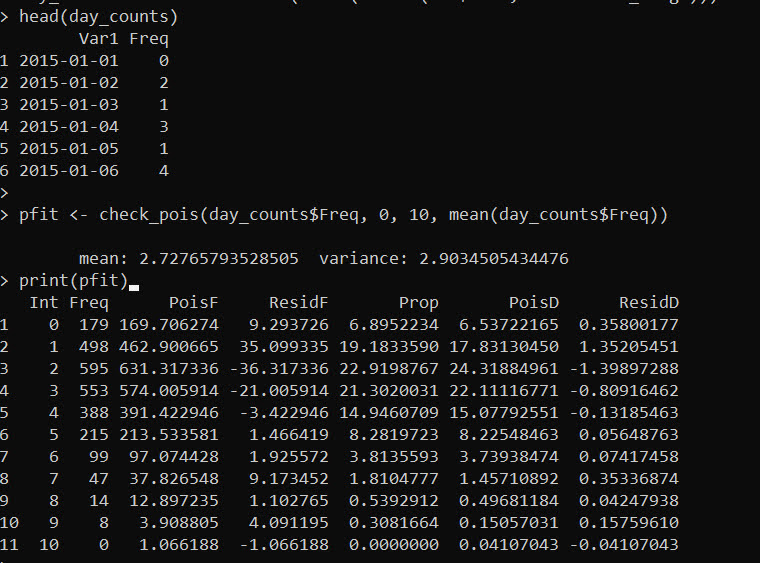
The way to read this, for a mean of 2.7 fatal OIS per day (and given this many days), we would expect 169.7 0 fatality days in the sample (PoisF), but we actually observed 179 0 fatality days, so a residual of 9.3 in the total count. The trailing rows show the same in percentage terms, so we expect 6.5% of the days in the sample to have 0 fatalities according to the Poisson distribution, and in the actual data we have 6.9%.
You can read the same for the rest of the rows, but it is mostly the same. It is only very slight deviations from the baseline Poisson expected Poisson distribution. This data is the closest I have ever seen to real life, social behavioral data to follow a Poisson process.
For comparison, lets compare to the NYC shootings data I have saved in the ptools package.
# Lets check against NYC Shootings
data(nyc_shoot)
date_range <- paste0(seq(as.Date('2006-01-01'),max(nyc_shoot$OCCUR_DATE),by='days'))
shoot_counts <- as.data.frame(table(factor(nyc_shoot$OCCUR_DATE,levels=date_range)))
sfit <- check_pois(shoot_counts$Freq,0,max(shoot_counts$Freq),mean(shoot_counts$Freq))
round(sfit,1)
This is much more typical of crime data I have analyzed over my career (in that it deviates from a Poisson process by quite a bit). The mean is 4.4 shootings per day, but the variance is over 13. There are many more 0 days than expected (433 observed vs 73 expected). And there are many more high crime shooting days than expected (tail of the distribution even cut off). For example there are 27 days with 18 shootings, whereas a Poisson process would only expect 0.1 days in a sample of this size.
My experience though is that when the data is overdispersed, a negative binomial distribution will fit quite well. (Many people default to a zero-inflated, like Paul Allison I think that is a mistake unless you have a structural reason for the excess zeroes you want to model.)
So here is an example of fitting a negative binomial to the shooting data:
# Lets fit a negative binomial and check out
library(fitdistrplus)
fnb <- fitdist(shoot_counts$Freq,"nbinom")
print(fnb$estimate)
sfit$nb <- 100*mapply(dnbinom, x=sfit$Int, size=fnb$estimate[1], mu=fnb$estimate[2])
round(sfit[,c('Prop','nb')],1) # Much better overall fit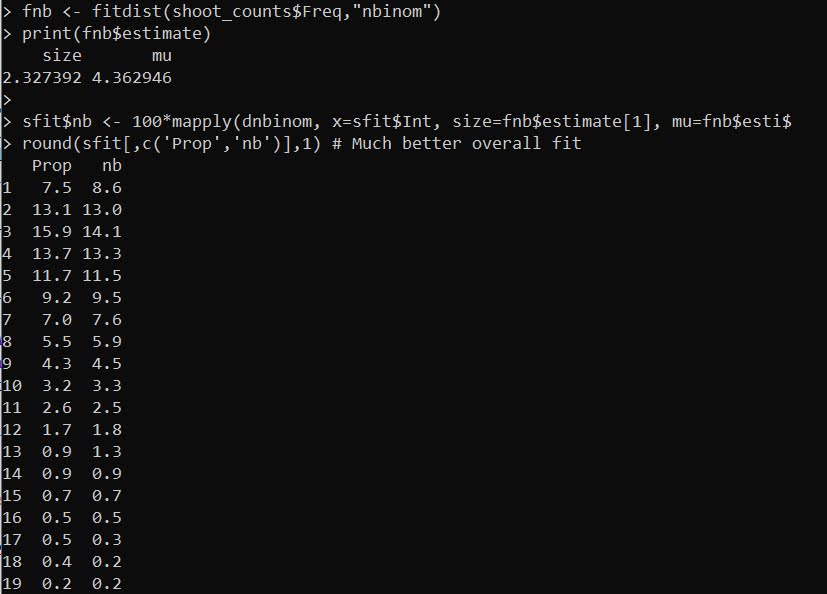
And this compares the percentages. So you can see observed 7.5% 0 shooting days, and expected 8.6% according to this negative binomial distribution. Much closer than before. And the tails are fit much closer as well, for example, days with 18 shootings are expected 0.2% of the time, and are observed 0.4% of the time.
So What Inferences Can We Make?
In social sciences, we are rarely afforded the ability to falsify any particular hypothesis – or in more lay-terms we can’t really ever prove something to be false beyond a reasonable doubt. We can however show whether empirical data is consistent or inconsistent with any particular hypothesis. In terms of Fatal OIS, several ready hypotheses ones may be interested in are Does increased police scrutiny result in fewer OIS?, or Did the recent increase in violence increase OIS?.
While these two processes are certainly plausible, the data collected by WaPo are not consistent with either hypothesis. It is possible both mechanisms are operating at the same time, and so cancel each other out, to result in a very consistent 1000 Fatal OIS per year. A simpler explanation though is that the baseline rate has not changed over time (Occam’s razor).
Again though we are limited in our ability to falsify these particular hypotheses. For example, say there was a very small upward trend, on the order of something like +10 Fatal OIS per year. Given the underlying variance of Poisson variables, even with 7+ years of data it would be very difficult to identify that small of an upward trend. Andrew Gelman likens it to measuring the weight of a feather carried by a Kangaroo jumping on the scale.
So really we could only detect big changes that swing OIS by around 100 events per year I would say offhand. Anything smaller than that is likely very difficult to detect in this data. And so I think it is unlikely any of the recent widespread impacts on policing (BLM, Ferguson, Covid, increased violence rates, whatever) ultimately impacted fatal OIS in any substantive way on that order of magnitude (although they may have had tiny impacts at the margins).
Given that police departments are independent, this suggests the data on fatal OIS are likely independent as well (e.g. one fatal OIS does not cause more fatal OIS, nor the opposite one fatal OIS does not deter more fatal OIS). Because of the independence of police departments, I am not sure there is a real great way to have federal intervention to reduce the number of fatal OIS. I think individual police departments can increase oversight, and maybe state attorney general offices can be in a better place to use data driven approaches to oversee individual departments (like ProPublica did in New Jersey). I wouldn’t bet money though on large deviations from that fatal 1000 OIS anytime soon though.