Jeff Asher recently wrote about the likely 2020 increase in Homicides, stating this is an unprecedented increase. (To be clear, this is 2020 data! Homicide reporting data in the US is just a few months shy of a full year behind.)

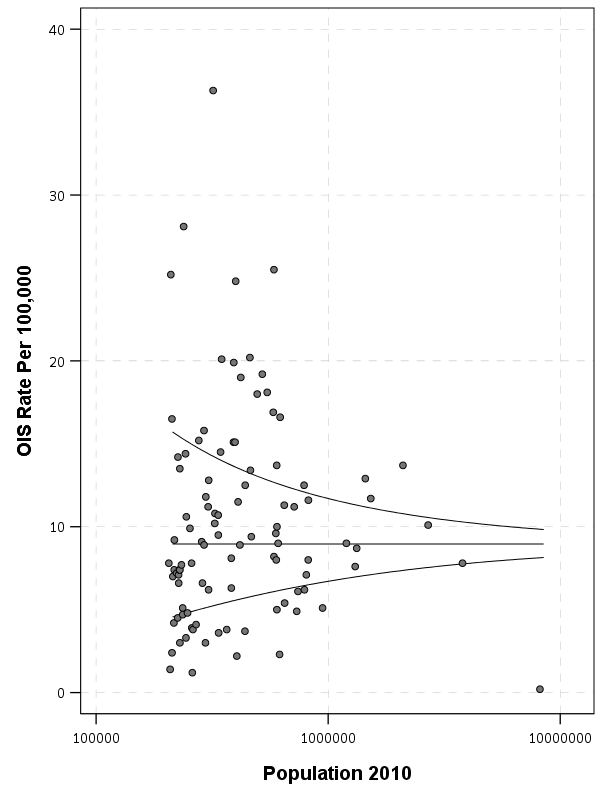
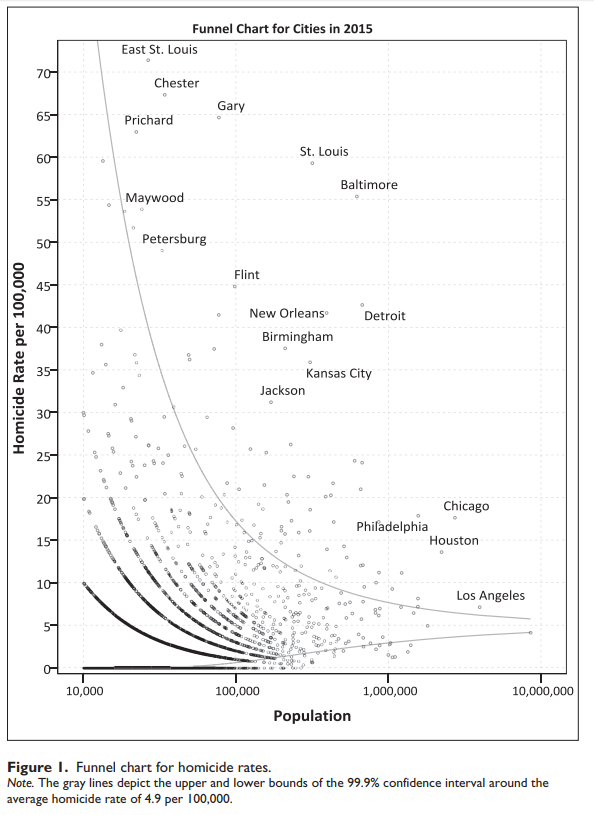
In the past folks have found me obnoxious, as I often point to how homicide rates (even for fairly large cities), are volatile (Wheeler & Kovandzic, 2018). Here is an example of how I thought the media coverage of the 2015/16 homicide increase was overblown.
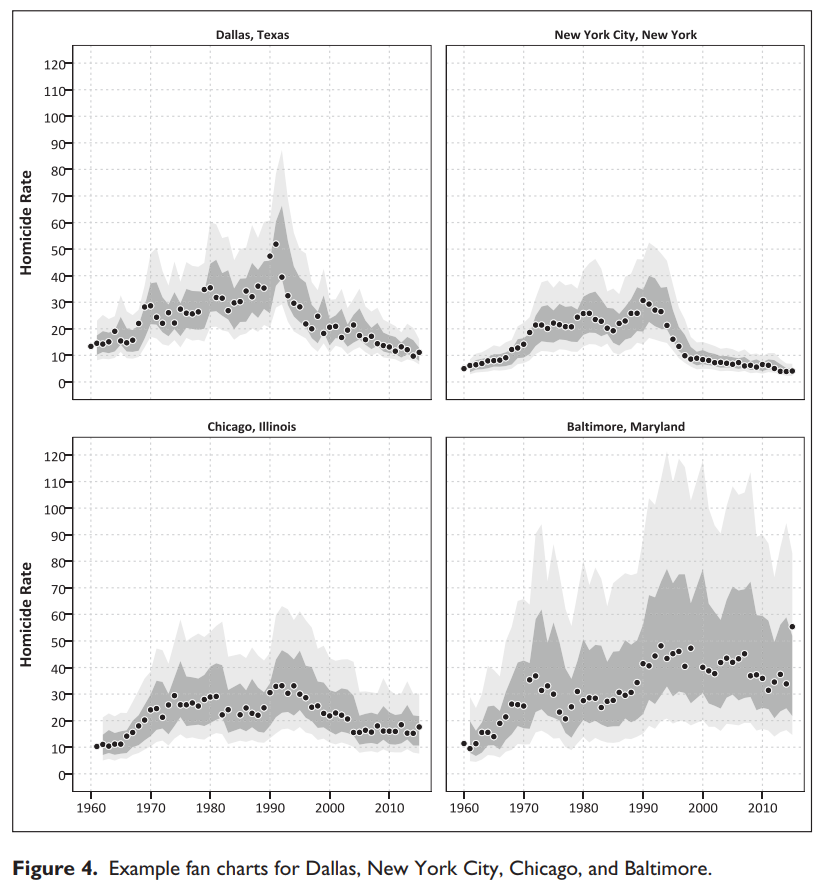
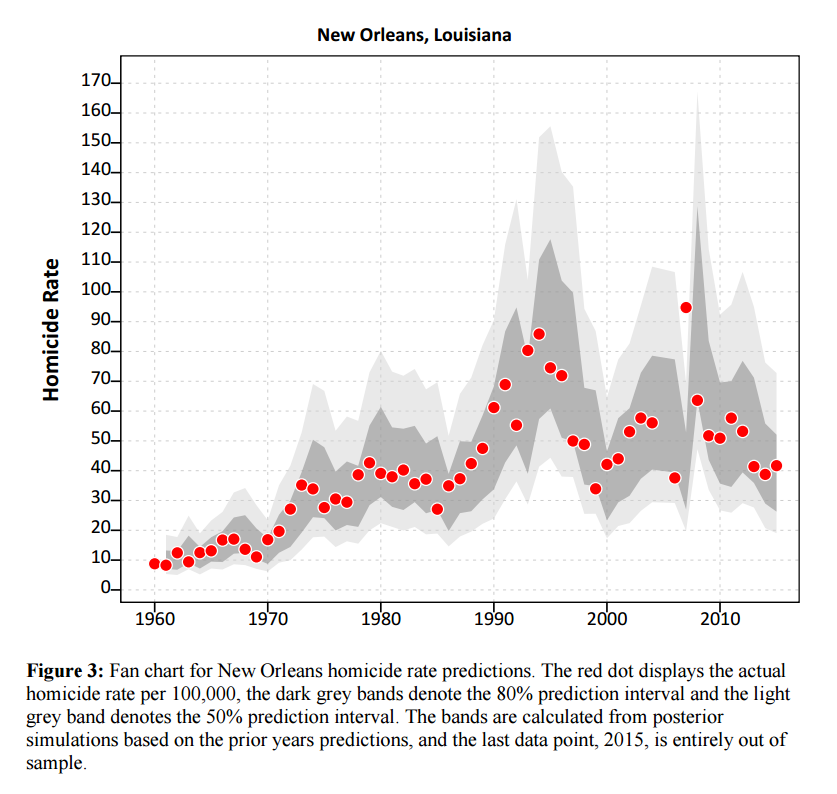
I actually later quantified this more formally with then students Haneul Yim and Jordan Riddell (Yim et al., 2020). We found the 2015 increase was akin to when folks on the news say a 1 in 100 year flood. So I was wrong in terms of it was a fairly substantive increase relative to typical year to year changes. Using the same methods, I updated the charts to 2020 data, and 2020 is obviously a much larger increase than the ARIMA model we fit based on historical data would expect:
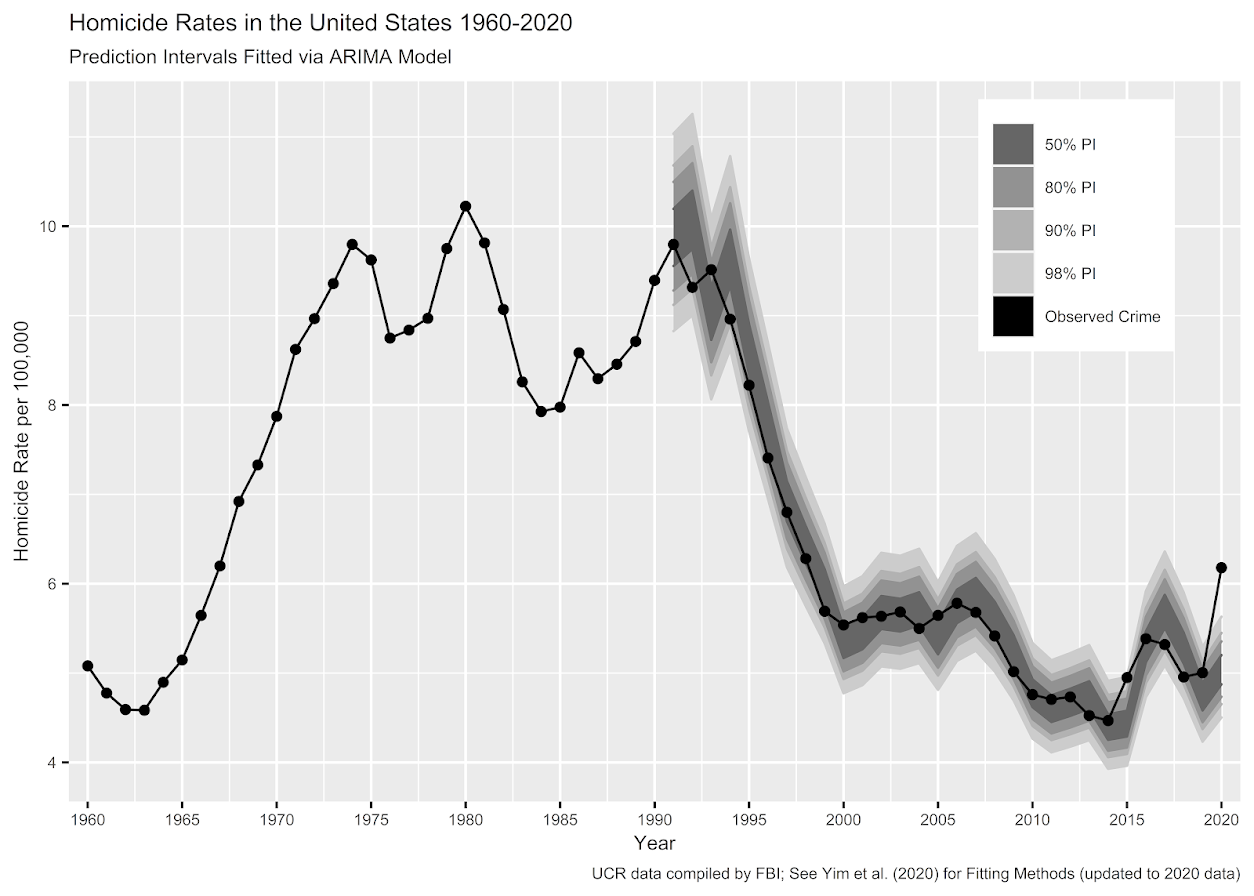
Looking at historical data, people often argue “it isn’t as high as the early 90’s” – this is not the point though I really intended to make (it is kind of silly to make a normative argument about the right or acceptable number of homicides) – but I can see how I conflated those arguments. Looking at the past is also about understanding the historical volatility (what is the typical year to year change). Here this is clearly a much larger swing (up or down) than we would expect based on the series where we have decent US coverage (going back to 1960).
For thinking about crime spikes, I often come from a place in my crime analyst days where I commonly was posed with ‘crime is on the rise’ fear in the news, and needed to debunk it (so I could get back to doing analysis on actual crime problems, not imaginary ones). One example was a convenience store was robbed twice in the span of 3 days, and of course the local paper runs a story crime is on the rise. So I go and show the historical crime trends to the Chief and the Mayor that no, commercial robberies are flat. And even for that scenario there were other gas stations that had more robberies in toto when looking at the data in the past few years. So when the community police officer went to talk to that convenience store owner to simply lock up his cash in more regular increments, I told that officer to also go to other stores and give similar target hardening advice.
Another aspect of crime trends is not only whether a spike is abnormal (or whether we actually have an upward trend), but what causes it. I am going to punt on that – in short it is basically impossible in normal times to know what caused short term spikes absent identifying specific criminal groups (which is not so relevant for nationwide spikes, but even in large cities one active criminal group can cause observable spikes). We have quite a bit of crazy going on at the moment – Covid, BLM riots, depolicing – I don’t know what caused the increase and I doubt we will ever have a real firm answer. We cannot run an experiment to see why these increases occurred – it is mostly political punditry pinning it on one theory versus another.
For the minor bit it is worth – the time series methods I use here signal that the homicide series is ARIMA(1,1,0) – which means both an integrated random walk component and a auto-regressive component. Random walks will occur in macro level data in which the micro level data are a bunch of AR components. So this suggests a potential causal attribution to increased homicides is homicides itself (crime begets more crime). And this can cause run away effects of long upwards/downwards trends. I don’t know of a clear way though to validate that theory, nor any obvious utility in terms of saying what we should do to prevent increases in homicides or stop any current trends. Even if we have national trends, any intervention I would give a thumbs up to is likely to be local to a particular municipality. (Thomas Abt’s Bleeding Out is about the best overview of potential interventions that I mostly agree with.)
References
- Wheeler, A. P., & Kovandzic, T. V. (2018). Monitoring volatile homicide trends across US cities. Homicide Studies, 22(2), 119-144.
- Yim, H. N., Riddell, J. R., & Wheeler, A. P. (2020). Is the recent increase in national homicide abnormal? Testing the application of fan charts in monitoring national homicide trends over time. Journal of Criminal Justice, 66, 101656.
Notes for the 2019/2020 updated homicide data. 2019 data is available from the FBI page, 2020 homicide data I have taken from estimates at USA Facts and total USA pop is taken from Google search results.
R code and data to replicate the chart can be downloaded here.