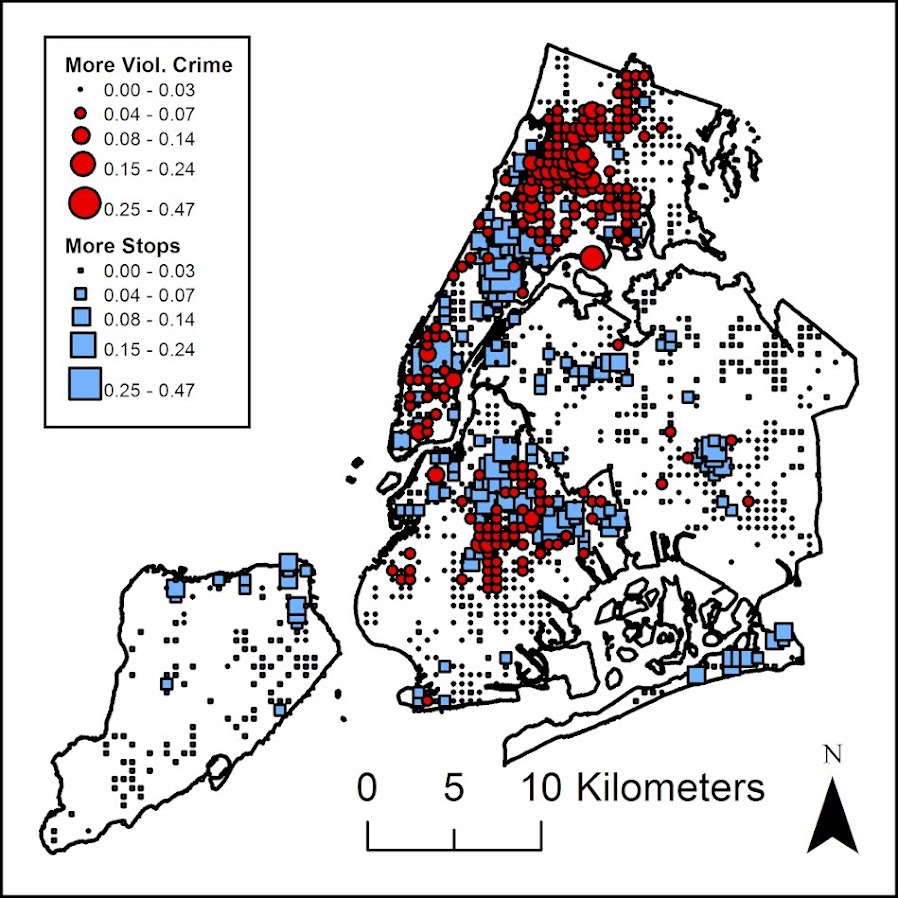
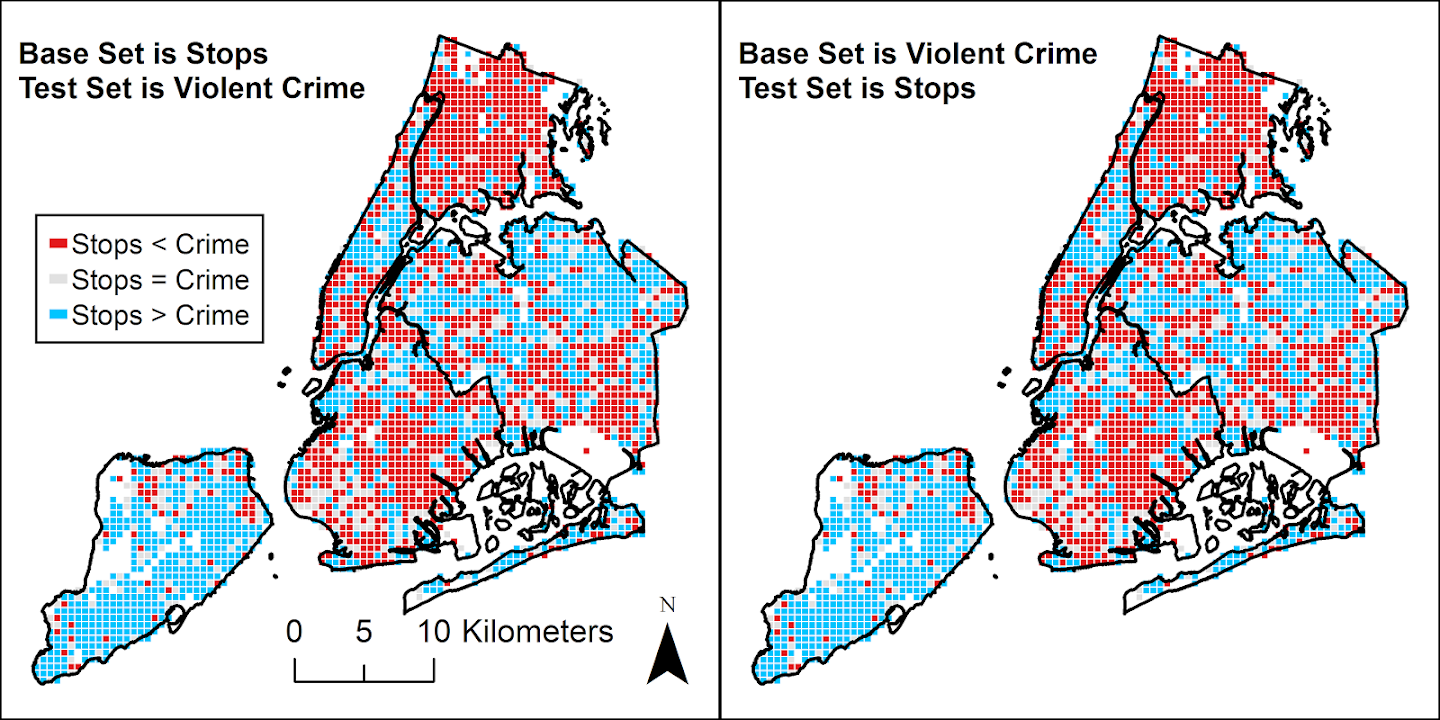
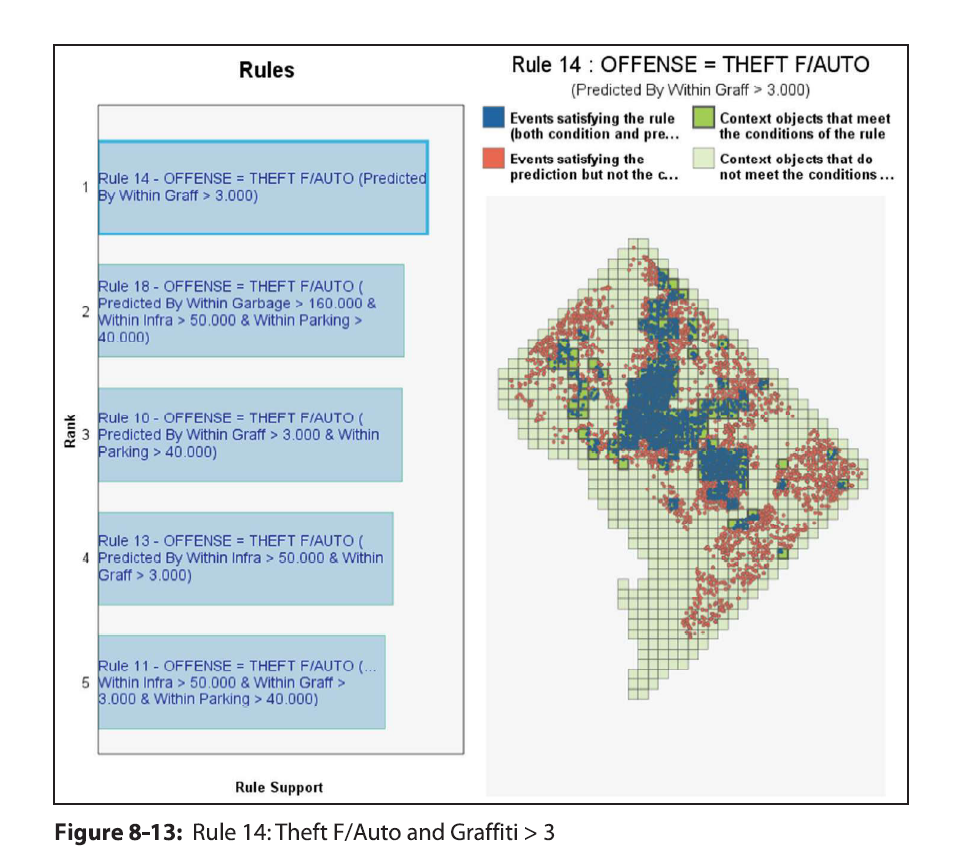
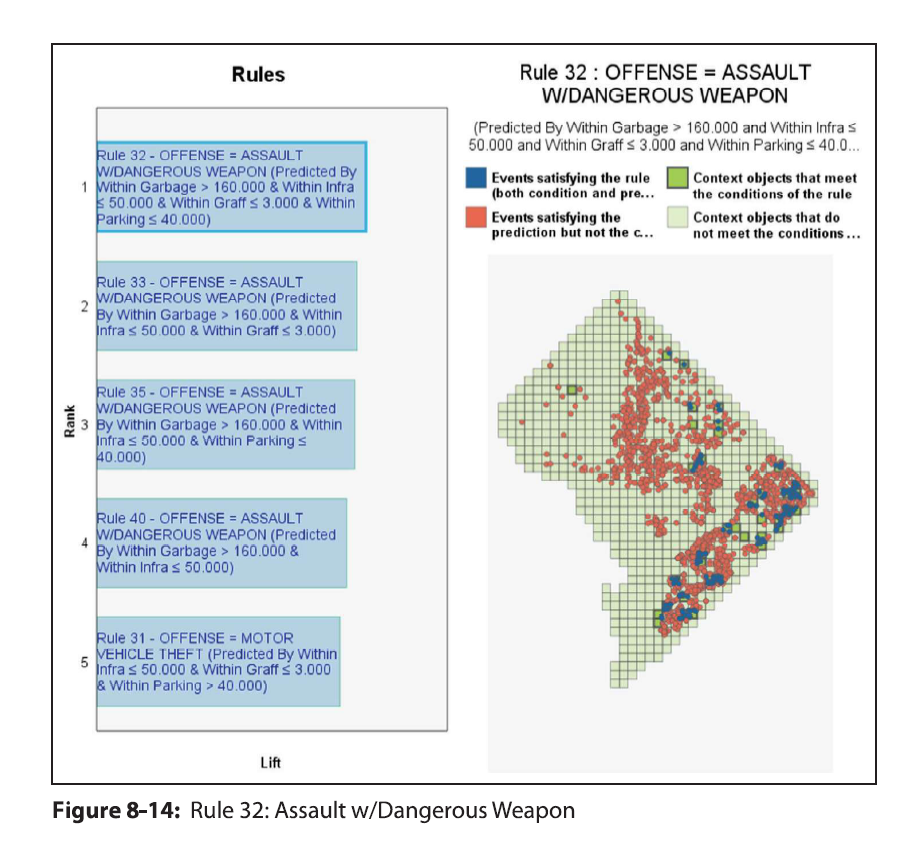
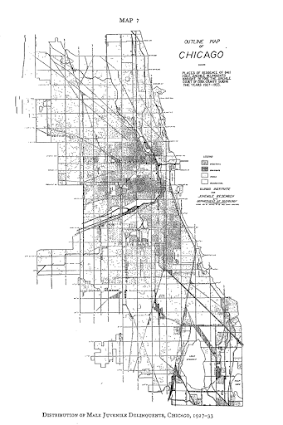
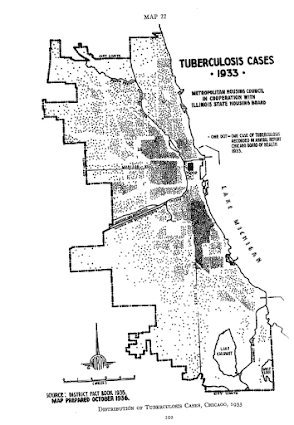
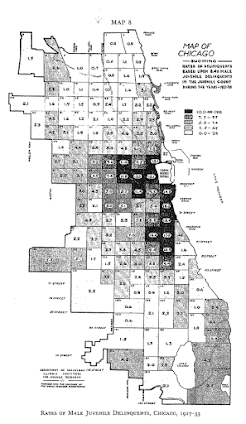
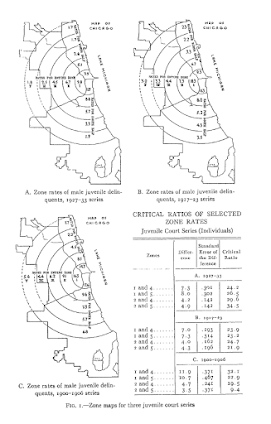
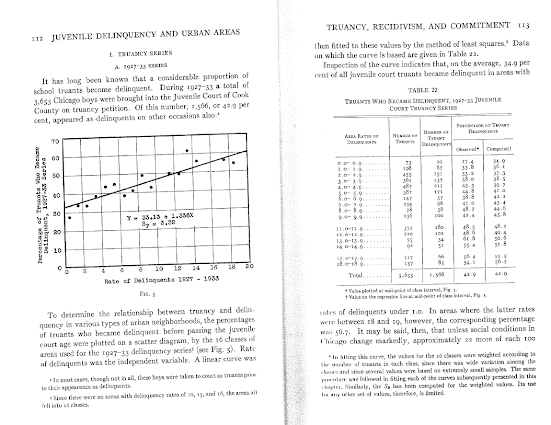
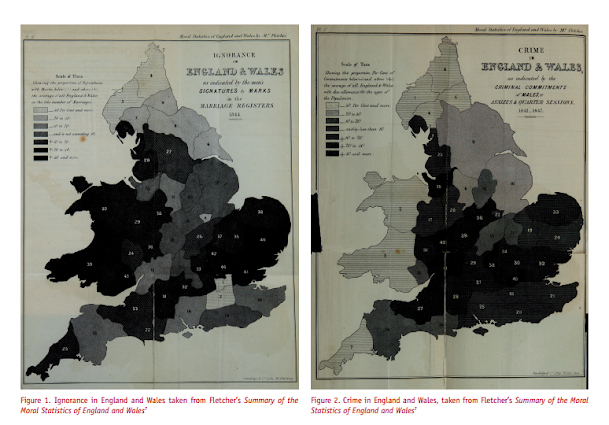
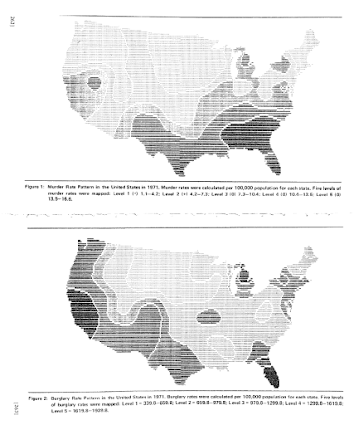
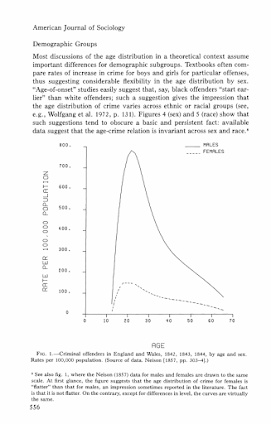
In my ask me anything series, Thom Snaphaan, a criminologist at Ghent University writes in with this question (slightly edited by me):
I read your blog post on using the Google Places API for criminological research. I am interested in using these data in the context of my PhD research. Can I ask you some questions on this matter? We think Google Places might be a very rich data source, specifically the user ratings of places. (1) Is it allowed to use these data on a large scale (two large cities) for scientific research? (2) Is it possible to download a set without the limit of 1,000 requests per day? (3) Are there, in your experience, other (perhaps more interesting) data sources to conduct this study? Many thanks! Best, Thom
And for my responses to Thom,
For 1) I believe it is OK to use for research purposes. You are not allowed to download the data and resell it though.
For 2) The quotas for the places API are much larger, it is now you get $200 credit per month, which amounts to 100,000 API calls. So that should be sufficient even for a large city.
For 3) I do not know, I haven’t paid much attention to the different online apps that do user reviews. Here in the states we have another service called Yelp (mostly for restaurants), I am not sure if that has more reviews or not though.
One additional piece of information not commonly used in place based research (but have seen it used some Hipp, 2016; Perenzin-Askey, 2018), is the use of the number of employees or sales volume at particular crime generators/attractors. This is not available via google, but is via Reference USA or Lexis Nexis. For Dallas IIRC Reference USA had much better coverage (almost twice as many businesses), but I recently reviewed a paper that did boots on the ground validation for Google data in the Indian city of Chennai and the validation for google businesses was very high (Kuralarason & Bernasco, 2021)
Answer in the comments if you think you have more helpful information on leveraging the place based user reviews in research projects.
In the past I have written about using various google APIs, and which I have used in my research for several different projects.
- Google Places API, and here is a code snippet with some functions to scrape places data (although would need to be updated to include the atmosphere ratings)
- Google Distance API
- Google Streetview API (Address Based, Running Down Street)
- Google Geocoding API
- Google Vision API with streetview images
Google has new pricing now, where you get $200 in credits per month per API. But overall the Places and the streetview API you get a crazy ton of potential calls, so will work for most research projects. Looking it over I actually don’t think I have used Google places data in any projects, in Wheeler & Steenbeek, 2021 I use reference USA and some other sources.
Geocoding and distance API limits are tougher, I ended up accidentally charging myself ~$150 for my work with Gio on gunshot fatalities (Circo & Wheeler, 2021) calculating network distance and approximate drive times. The vision API is also quite low (1000 per month), so will need to budget/plan if you need those services for your project. Geocoding you should be able to find alternatives, like the census geocoder (R, python) and then only use google for the leftovers.
References
- Circo, G. M., & Wheeler, A. P. (2021). Trauma Center Drive Time Distances and Fatal Outcomes among Gunshot Wound Victims. Applied Spatial Analysis and Policy, 14(2), 379-393.
- Hipp, J. R. (2016). General theory of spatial crime patterns. Criminology, 54(4), 653-679.
- Kuralarasan, K., & Bernasco, W. (2021). Location Choice of Snatching Offenders in Chennai City. Journal of Quantitative Criminology, Online First.
- Perezin-Askey, A., Taylor, R., Groff, E., & Fingerhut, A. (2018). Fast food restaurants and convenience stores: Using sales volume to explain crime patterns in Seattle. Crime & Delinquency, 64(14), 1836-1857.
- Wheeler, A. P., & Steenbeek, W. (2021). Mapping the risk terrain for crime using machine learning. Journal of Quantitative Criminology, 37(2), 445-480.