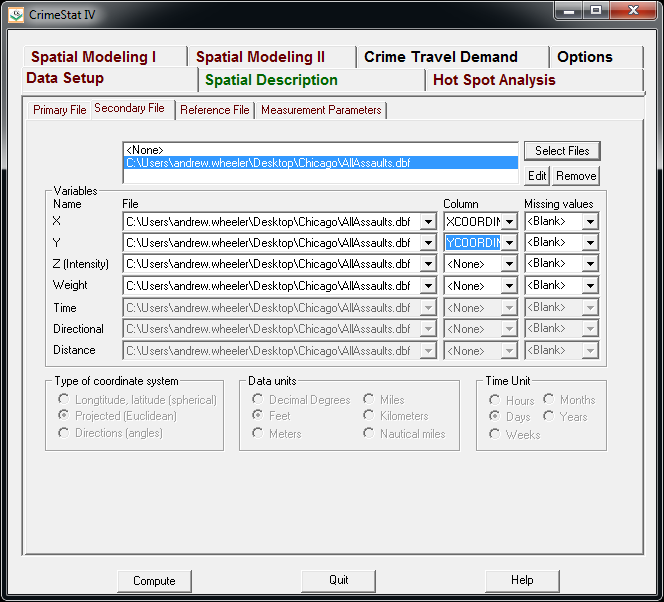
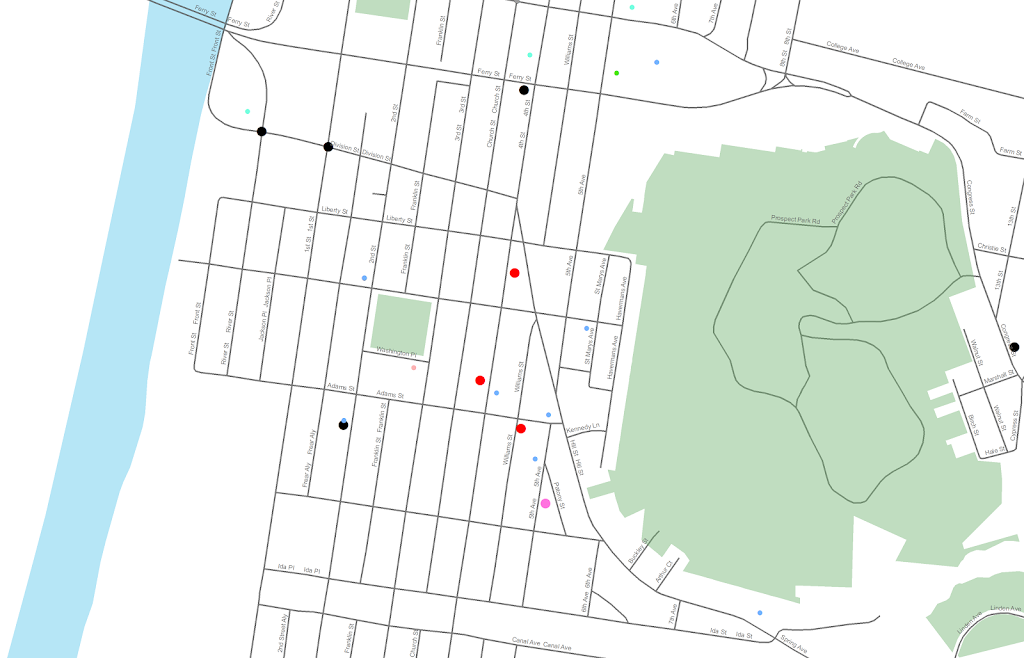
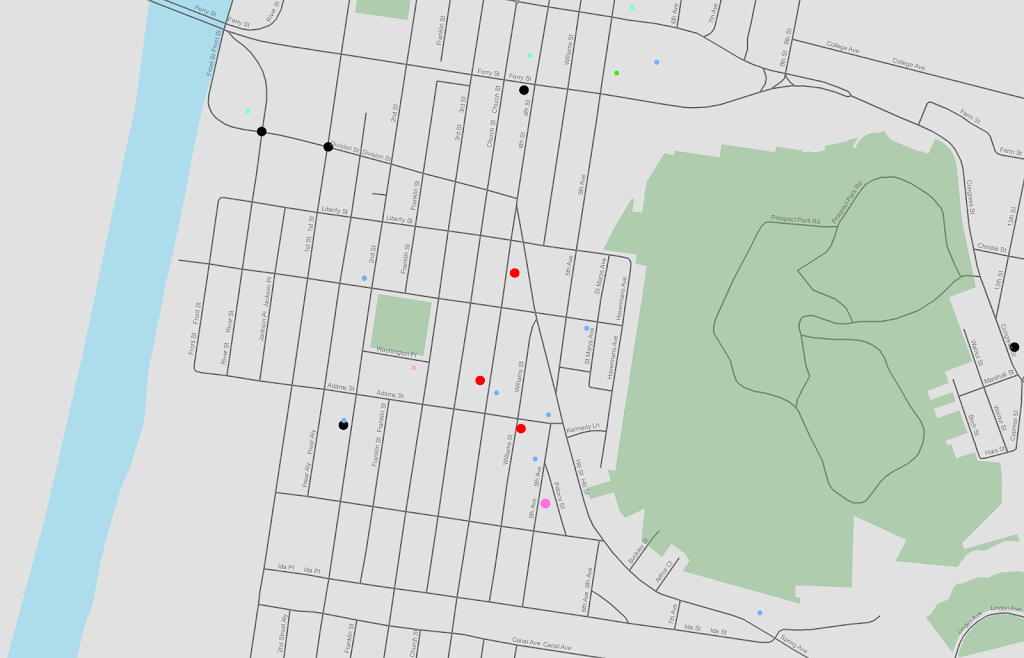
In the past to share interactive maps with others I’ve used BatchGeo and CartoDB. BatchGeo is super easy to geocode a few incidents, and CartoDB has a few more stylistic options (including some very cool animations). Both of these projects have a limit on the number of points you can map with the free service though. The new Google maps allows you make similar products to BatchGeo and CartoDB, in that you can upload a csv file or kml and then do some light editing of the points, and then embed an iframe in a website if you want (I wish Google Maps had a time slider like Google Earth does). Here is an example from my PhD of a few locations that one of my original models did a very poor job of predicting the amount of crime at the street midpoint or intersection.
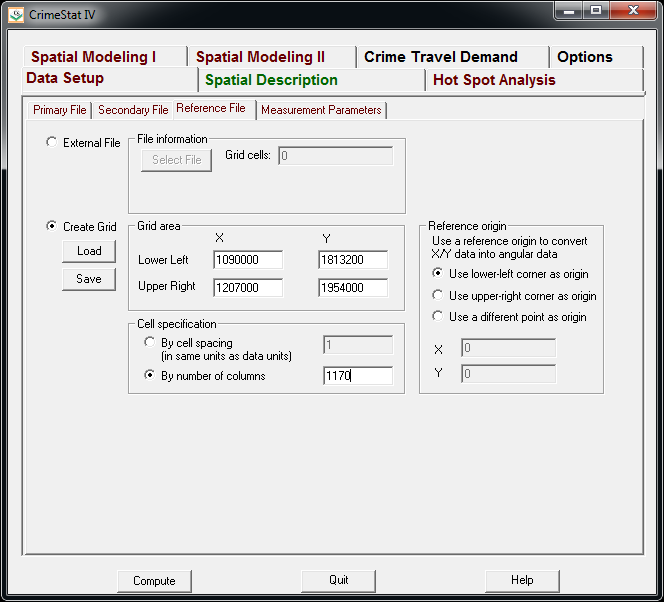
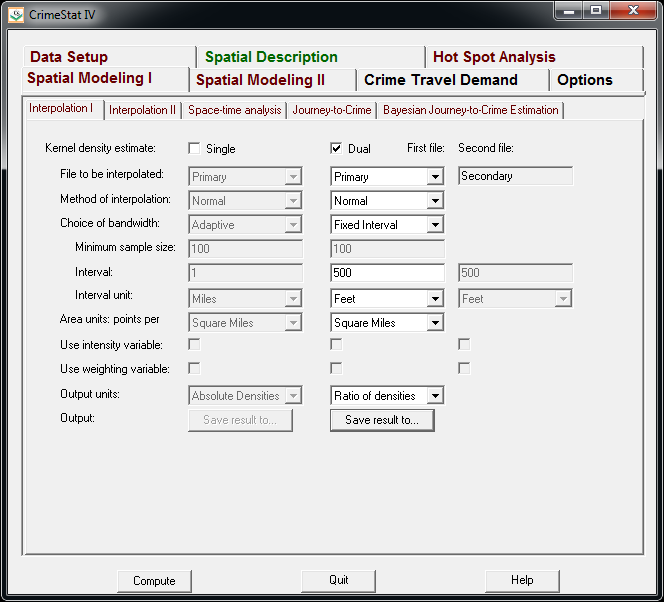
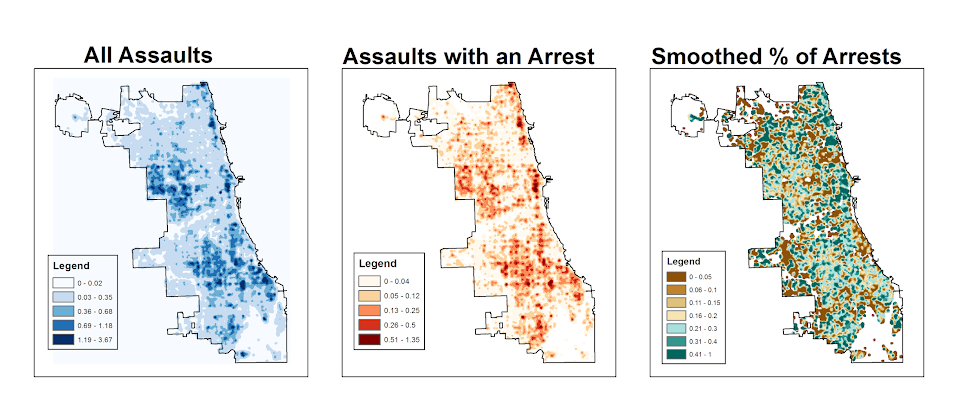
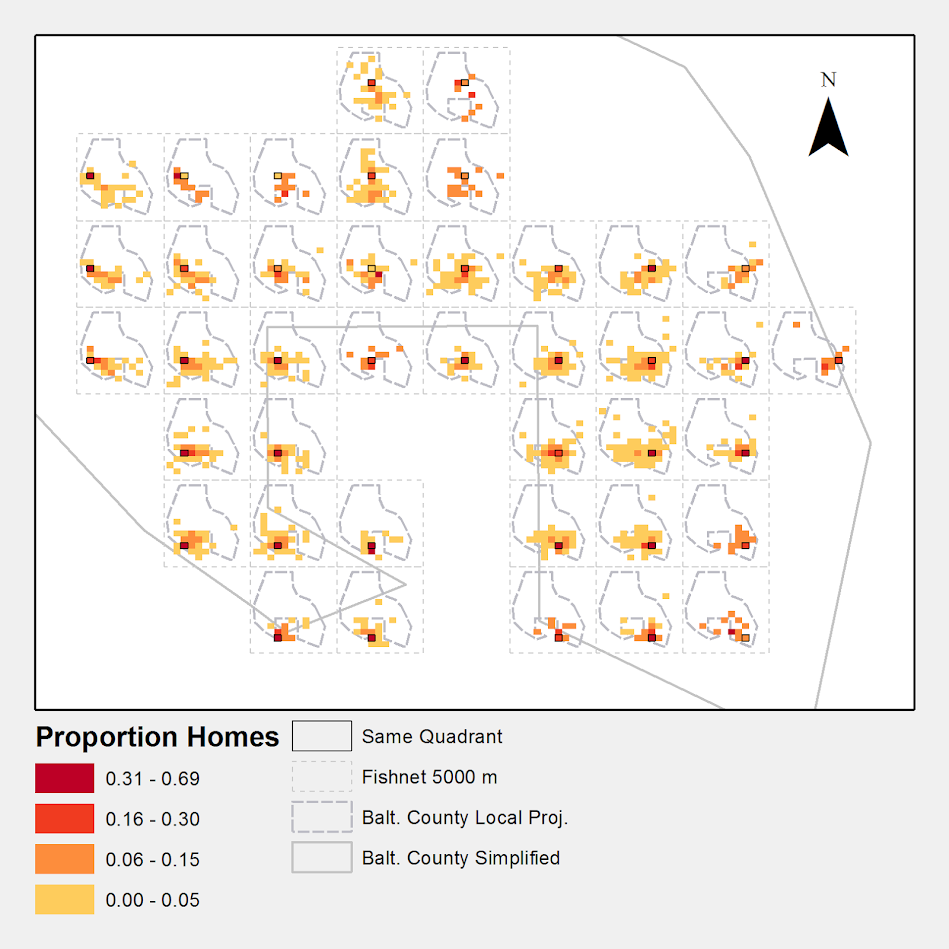
But a few recent projects I wanted to place many more geographies on the map than these free versions allow. ArcGIS online is pretty slick in my few tests, but I am settling on Google Fusion tables for the ability to link the geographies and data tables (plus the ability to filter is very nice). Basically you can upload your data table and kml in seperate Fusion tables and then merge them to create your own polygons with associated data. Here is another example from my dissertation and embedded map below.
Basically what I do is make a set of units of analysis based on street mid-points and intersections. I then divide the city up based on the Thiessen polygons of those sets of points for the allocation of different areal measures. E.g. I can calculate the overlap of the Thiessen polygon with the area of sidewalks.
I’m using Google Fusion tables for some other projects in which I want people within the PD to be able to interactively explore the data. My main interest in these slippy maps are that you can pan and zoom – and with a static map it is hard to recreate all of the potential views a consumer of the map wants. I can typically make a nicer overview map of the forest or any general data patterns in a static map, but if I think the user of the map will want to zoom in to particular locations these interactive maps meet that challenge. Pop-ups allow for a brief digging into the data as well, but don’t allow for visualizing patterns. Fusion tables are very limited though it the styling of the geography. (All of these free versions are pretty limited, but the Fusion tables are especially restrictive for point symbology and creating choropleth classes).
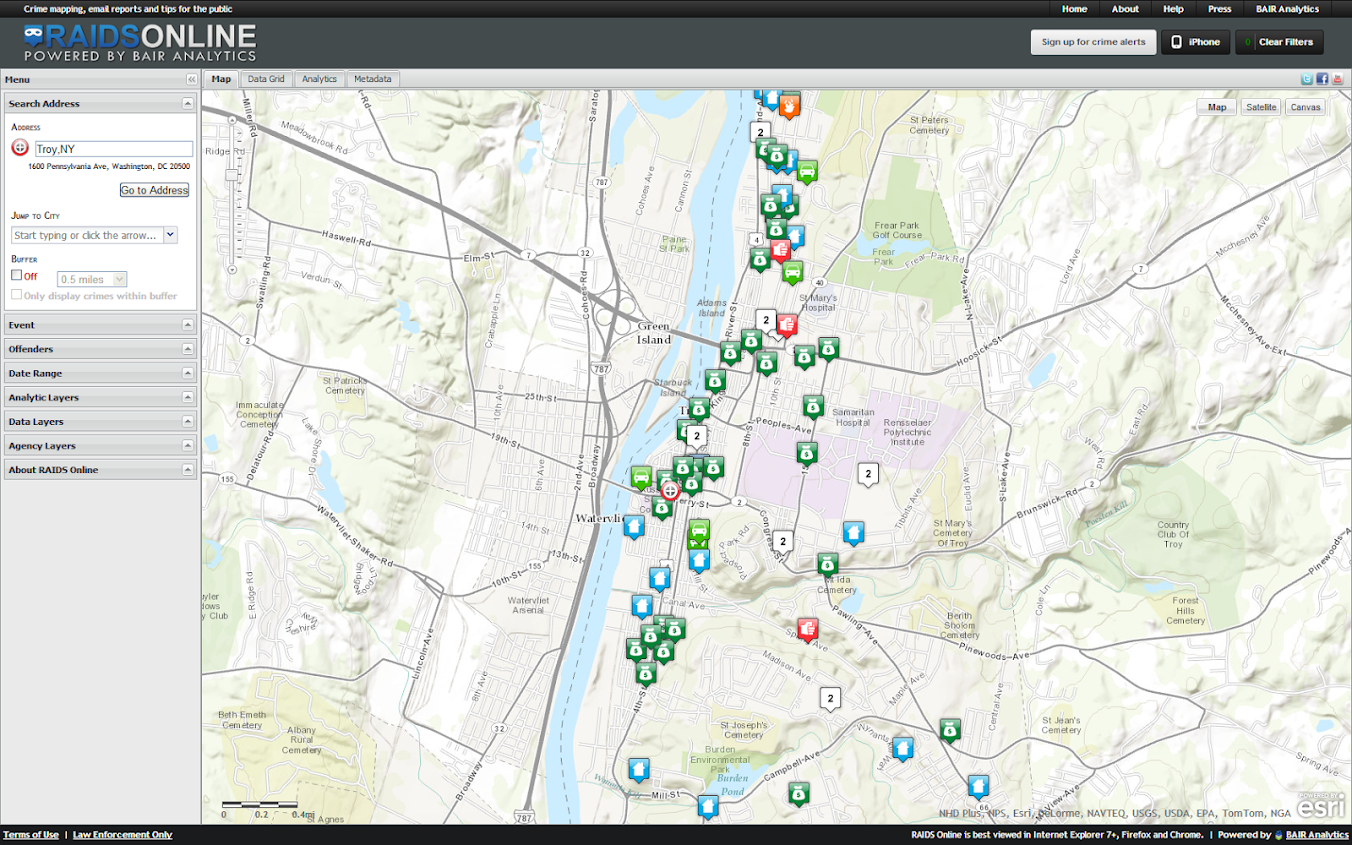
Using these maps has a trade off when sharing with the PD though. They are what I would call semi-public, in that if you want others to be able to view the map you can share a link, but anyone with the link can see the map. This prevents sharing of intimate information on the map that might be possibly leaked. (For the ability to have access control to more sensitive information, e.g. a user has to sign on to a secure website, I know Bair analytics offers paid for products like that – probably some of the prior web map apps I mentioned do so as well.) I’ve made them in the past for Troy P.D., but I really have no idea how often they were used – so other analysts let me know in the comments if you’ve had success with maps like these disseminating info. within the police department.
I’m getting devilishly close to finishing my dissertation, and I will post an update and link when the draft is complete. My prospectus can be seen here, and the linked maps are part of some supplemental material I compiled. The supplemental info. should provide a little more details on what the maps are showing.