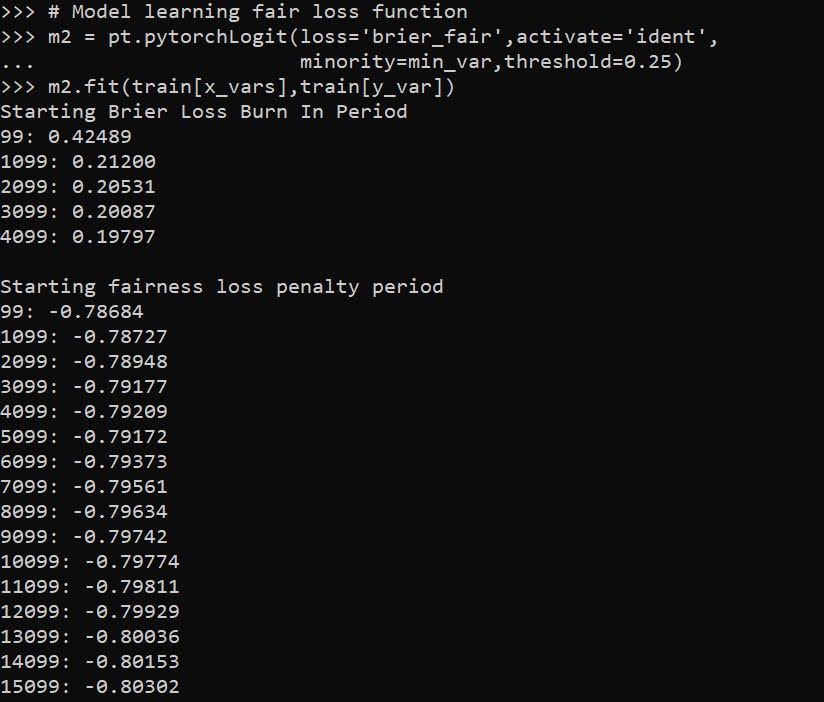
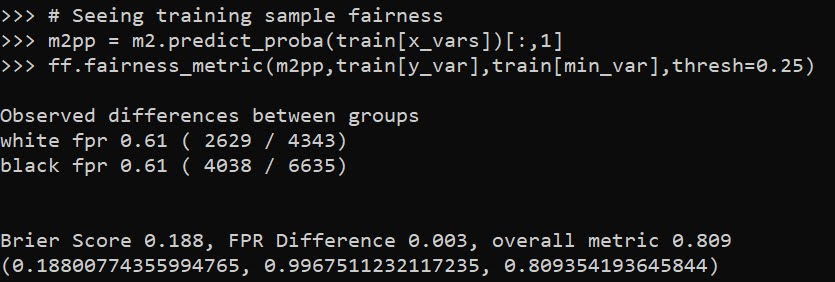
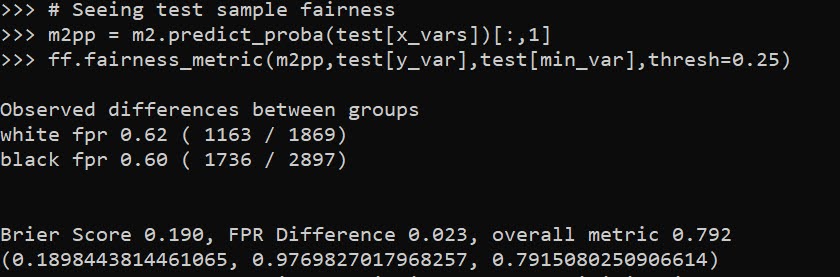
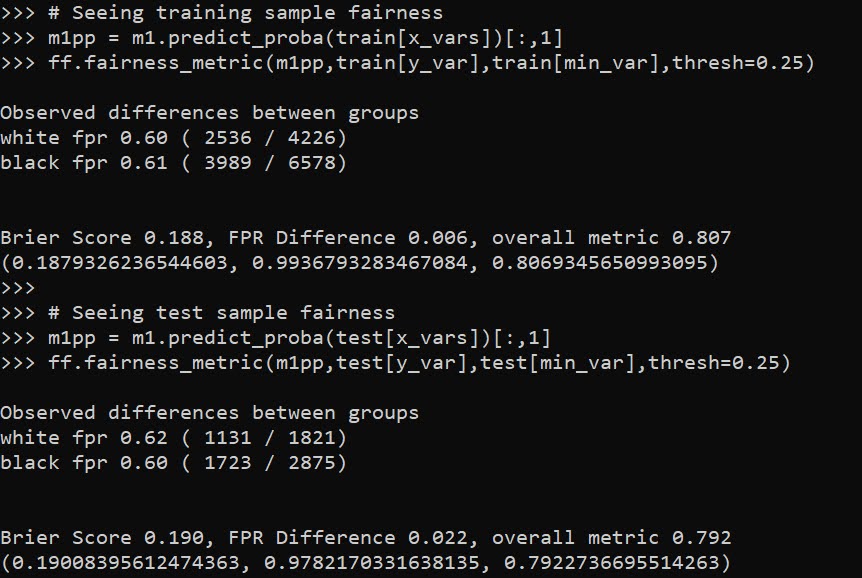
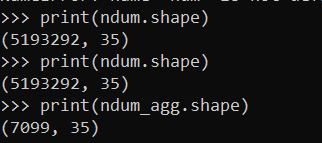
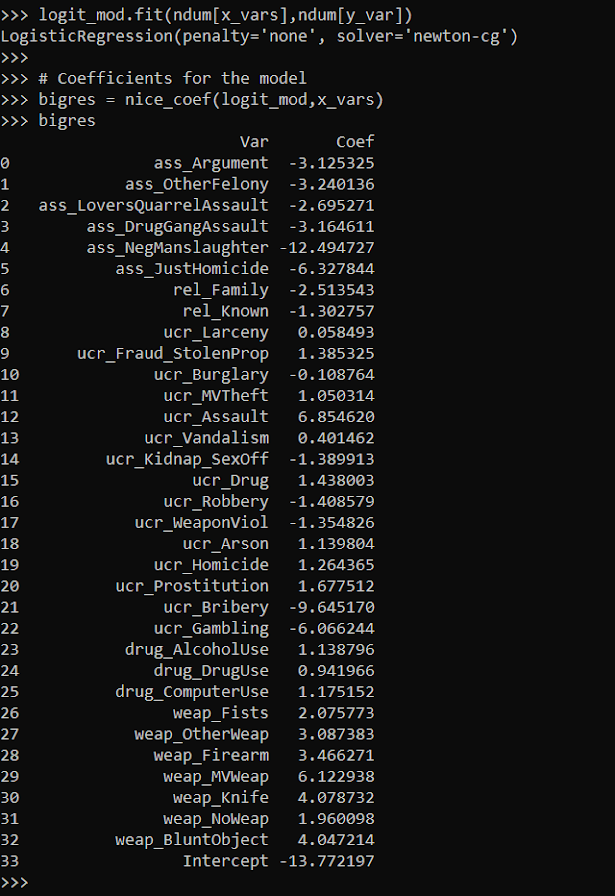
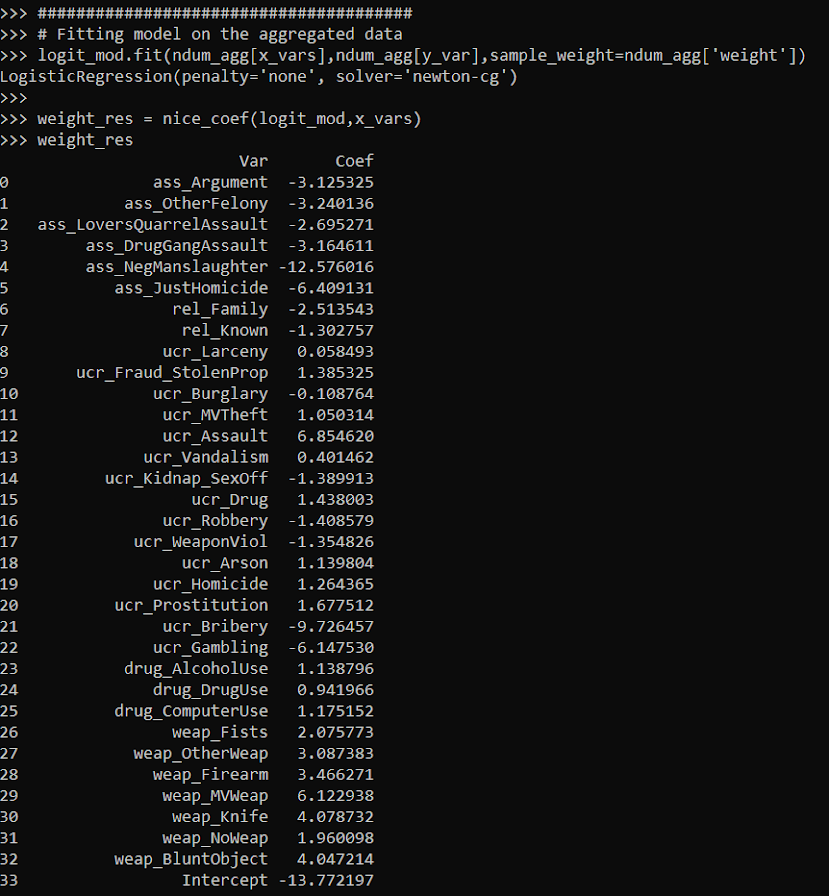
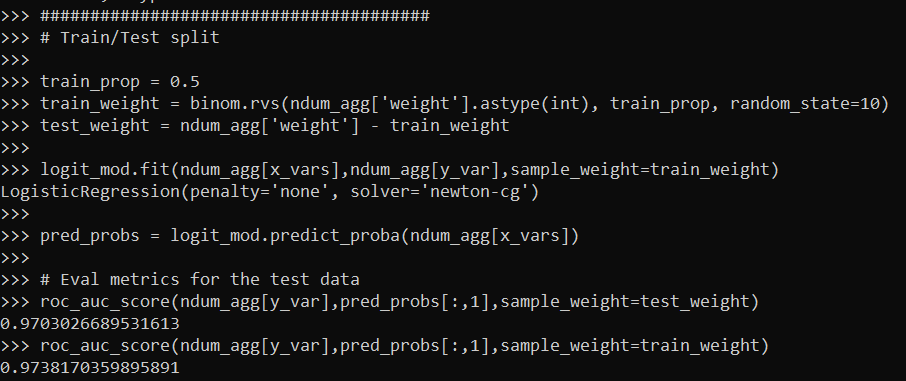
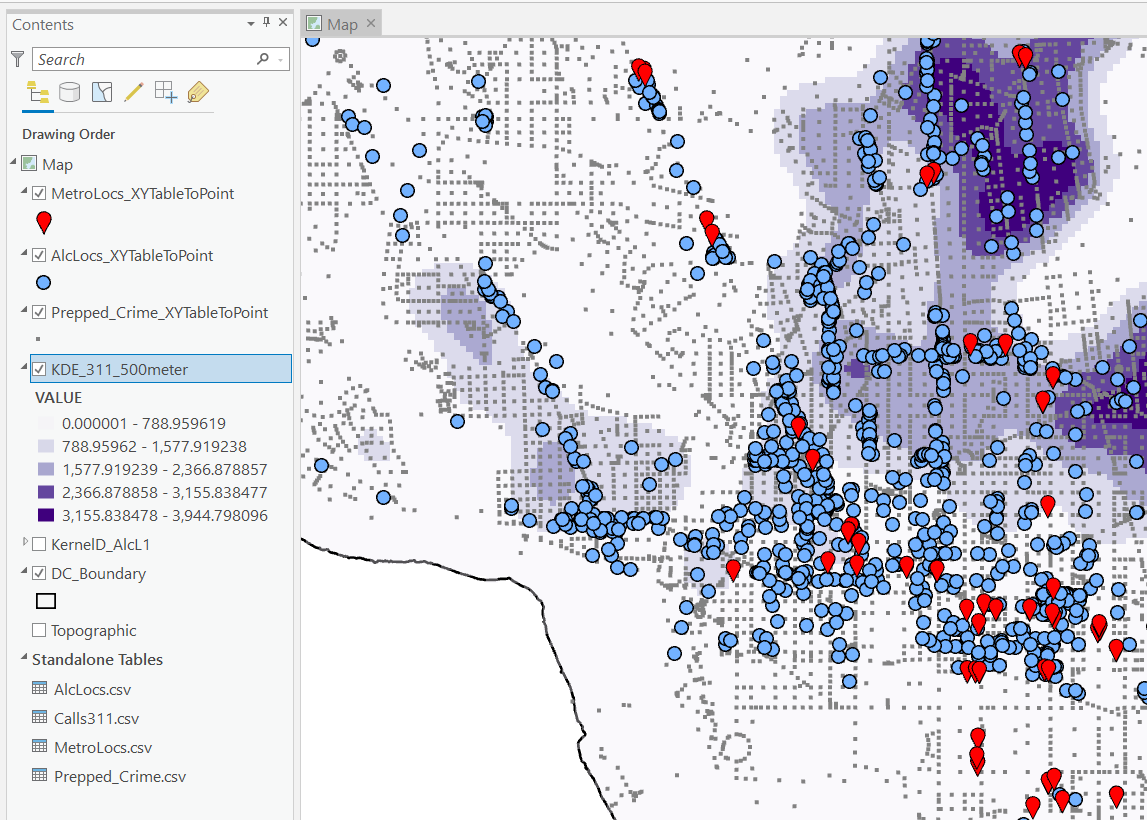
When doing binary prediction models, there are really two plots I want to see. One is the ROC curve (and associated area under the curve stat), and the other is a calibration plot. I have written a few helper functions to make these plots for multiple models and multiple subgroups, so figured I would share, binary plots python code. To illustrate their use, I will use the same Compas recidivism data I have used in the past, (CSV file here). So once you have downloaded those two files you can follow along with my subsequent code.
Front Prep
First, I have downloaded the binary_plots.py file and the PreppedCompas.csv file to a particular folder on my machine, D:\Dropbox\Dropbox\Documents\BLOG\binary_plots. To import these functions, I append that path using sys, and change the working directory using os. The other packages are what I will be using the fit the models.
###############################################
# Front end prep
import pandas as pd
import numpy as np
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
import os
import sys
my_dir = r'D:\Dropbox\Dropbox\Documents\BLOG\binary_plots'
os.chdir(my_dir)
# Can append to path
sys.path.append(my_dir)
import binary_plots
np.random.seed(10) #setting the seed for the random
# split for train/test
###############################################
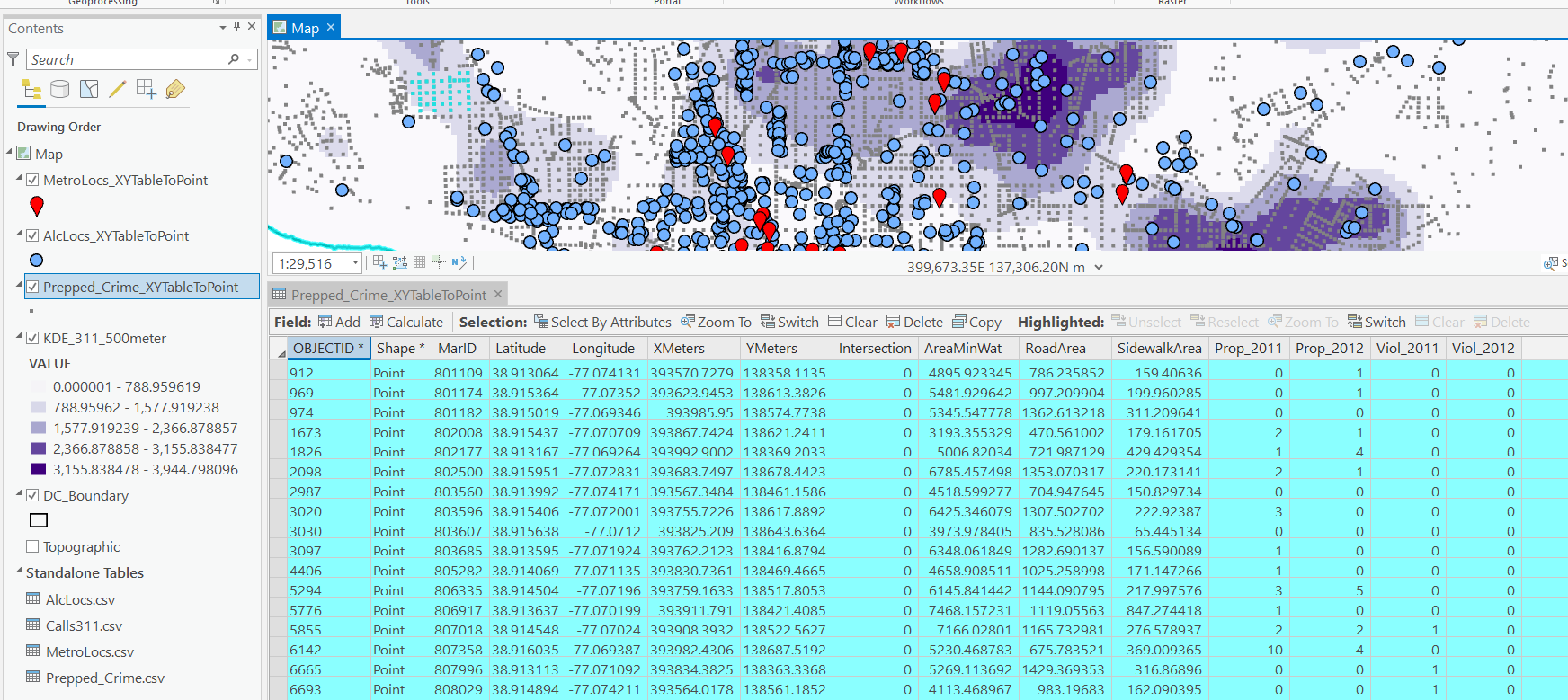
Next up I prepare the data, this is just boring stuff turning categorical variables into various dummies and making a train/test split for the data (which can be done in a variety of ways).
###############################################
# Prepping Compas Data
#For notes on data source, check out
#https://github.com/apwheele/ResearchDesign/tree/master/Week11_MachineLearning
recid = pd.read_csv('PreppedCompas.csv')
#Preparing the variables I want
recid_prep = recid[['Recid30','CompScore.1','CompScore.2','CompScore.3',
'juv_fel_count','YearsScreening']].copy()
recid_prep['Male'] = 1*(recid['sex'] == "Male")
recid_prep['Fel'] = 1*(recid['c_charge_degree'] == "F")
recid_prep['Mis'] = 1*(recid['c_charge_degree'] == "M")
print( recid['race'].value_counts() )
dum_race = pd.get_dummies(recid['race'])
# White for reference category
for d in list(dum_race):
if d != 'Caucasion':
recid_prep[d] = dum_race[d]
print( recid['marital_status'].value_counts() )
dum_mar = pd.get_dummies(recid['marital_status'])
recid_prep['Single'] = dum_mar['Single']
recid_prep['Married'] = dum_mar['Married'] + dum_mar['Significant Other']
# reference category is separated/unknown/widowed
#Now generating train and test set
recid_prep['Train'] = np.random.binomial(1,0.75,len(recid_prep))
recid_train = recid_prep[recid_prep['Train'] == 1].copy()
recid_test = recid_prep[recid_prep['Train'] == 0].copy()
#Independant variables
ind_vars = ['CompScore.1','CompScore.2','CompScore.3',
'juv_fel_count','YearsScreening','Male','Fel','Mis',
'African-American','Asian','Hispanic','Native American','Other',
'Single','Married']
# Dependent variable
y_var = 'Recid30'
###############################################
Next, the sklearn library makes it quite easy to fit a set of multiple models. Most of the time I start with XGBoost, random forests, and a normal logistic model with no coefficient penalty. I just stuff the base model object in a dictionary, pipe in the same training data, and fit the models. Then I can add in the predicted probabilities from each model into the test dataset. (These plots I show you should only show on the test dataset, of course the data will be calibrated on the training dataset.)
###############################################
# Training three different models, Logit,
# Random Forest, and XGBoost
final_models = {}
final_models['XGB'] = XGBClassifier(n_estimators=100, max_depth=5)
final_models['RF'] = RandomForestClassifier(n_estimators=1000, max_depth=10, min_samples_split=50)
final_models['Logit'] = LogisticRegression(penalty='none', solver='newton-cg')
# Iterating over each model and fitting on train
for nm, mod in final_models.items():
mod.fit(recid_train[ind_vars], recid_train[y_var])
# Adding predicted probabilities back into test dataset
for nm, mod in final_models.items():
# Predicted probs out of sample
recid_test[nm] = mod.predict_proba(recid_test[ind_vars])[:,1]
###############################################
This is fairly tiny data, so I don’t need to worry about how long this takes or run out of memory. I’d note you can do the same model, but different hyperparameters in this approach. Such as tinkering with the depth for tree based models is one I by default limit quite a bit.
AUC Plots
First, my goto metric to see the utility of a particular binary prediction model is the AUC stat. This has one interpretation in terms of the concordance stat, an AUC of 0.7 means if you randomly picked a 0 case and a 1 case, the 1 case would have a higher value 70% of the time. So AUC is all about how well your prediction discriminates between the two classes.
So with my binary_plots function, you can generate an ROC curve for the test data for a single column of predictions as so:
# A single column
binary_plots.auc_plot(recid_test, y_var, ['Logit'], save_plot='AUC1.png')

As I have generated predictions for multiple models, I have also generated a similar graph, but stuff the AUC stats in the matplotlib legend:
# Multiple columns to show different models
pred_prob_cols = list(final_models.keys()) #variable names
binary_plots.auc_plot(recid_test, y_var, pred_prob_cols, save_plot='AUC2.png')

It is also the case you want to do these plots for different subgroups of data. In recidivism research, we are often interested in sex and racial breakdowns. Here is the Logit model AUC broken down by Males (1) and Females (0).
# By subgroups in the data
binary_plots.auc_plot_long(recid_test, y_var, 'Logit', group='Male', save_plot='AUC3.png')

So this pulls the labels from the data, but you can pass in strings to get nicer labels. And finally, I show how to put both of these together, both by models and by subgroups in the data. Subgroups are different panels, and you can pass in a fontsize moniker to make the legends smaller for each subplot, and a size for each subplot (they are squares).
# Lets make nicer variable names for Male/Females and Racial Groups
recid_test['Sex'] = recid_test['Male'].replace({0: 'Female', 1:'Male'})
recid_test['Race'] = recid[recid_prep['Train'] == 0]['race']
recid_test['Race'] = recid_test['Race'].replace({'Hispanic': 'Other', 'Asian':'Other', 'Native American':'Other', 'African-American':'Black', 'Caucasian':'White'})
# Now can do AUC plot by gender and model type
binary_plots.auc_plot_wide_group(recid_test, y_var, pred_prob_cols, 'Sex', size=4, leg_size='x-small', save_plot='AUC4.png')

The plots have a wrap function (default wrap at 3 columns), so you can plot as many subgroups as you want. Here is an example combing the sex and race categories:

One limitation to note in these plots, ROC plots are normalized in a way that the thresholds for each subgroup may not be at the same area of the plot (e.g. a FPR of 0.1 for one subgroup implies a predicted probability of 30%, whereas for another subgroup it implies a predicted probability of 40%).
ROC/AUC is definitely not a perfect stat, most of the time we are only interested in the far left hand side of the ROC curve (how well we can identify high risk cases without a ton of false positives). That is why I think drawing the curves are important – one model may have a higher AUC, but it is in an area of the curve not relevant for how you will use the predictions in practice. (For tree based models with limited depth and limited variables, it can produce flat areas in the ROC curve for example.)
But I find the ROC curve/AUC metric the most useful default for both absolute comparisons (how well is this model doing overall), as well as relative model comparisons (is Model A better than Model B).
Most models I work with I can get an AUC of 0.7 without much work, and once I get an AUC of 0.9 I am in the clearly diminishing returns category to tinkering with my model (this is true for both criminology related models I work with, as well as healthcare related models in my new job).
This is of course data dependent, and even an AUC of 0.9 is not necessarily good enough to use in practice (you need to do a cost-benefit type analysis given how you will use the predictions to figure that out).
Calibration Charts
For those with a stat background, these calibration charts I show are a graphical equivalent of the Hosmer-Lemeshow test. I don’t bother conducting the Chi-square test, but visually I find them informative to not only see if an individual model is calibrated, but also to see the range of the predictions (my experience XGBoost will be more aggressive in the range of predicted probabilities, but is not always well calibrated).
So we have the same three types of set ups as with the ROC plots, a single predicted model:
# For single model
binary_plots.cal_data('XGB', y_var, recid_test, bins=60, plot=True, save_plot='Cal1.png')

For multiple models, I always do these on separate subplots, they would be too busy to superimpose. And because it is a single legend, I just build the data and use seaborn to do a nice small multiple. (All of these functions return the dataframe I use to build the final plot in long format.) The original plot was slightly noisy with 60 bins, so I reduce it to 30 bins here, but it is still slightly noisy (but each model is pretty well calibrated). XGBoost has a wider range of probabilities, random forests lowest bin is around 0.1 and max is below 0.8. Logit has lower probabilities but none above 0.8.
# For multiple models
binary_plots.cal_data_wide(pred_prob_cols, y_var, recid_test, bins=30, plot=True, save_plot='Cal2.png')

For a single model, but by subgroups in the data. The smaller other race group is more noisy, but again each model appears to be approximately calibrated.
# For subgroups and one model
binary_plots.cal_data_group('XGB', y_var, 'Race', recid_test, bins=20, plot=True, save_plot='Cal3.png')

And a combo of subgroup data and multiple models. Again the smaller subgroup Females appear more noisy, but all three models appear to be doing OK in this quick example.
# For subgroups and multiple models
binary_plots.cal_data_wide_group(pred_prob_cols, y_var, 'Sex', recid_test, bins=20, plot=True, save_plot='Cal4.png')

Sometimes people don’t bin the data (Peter Austin likes to do a smoothed plot), but I find the binned data easier to follow and identify deviations above/below predicted probabilities. In real life you often have some fallout/dropoff if there is feedback between the model and how other people respond to the model (e.g. the observed is always 5% below the predicted).