
Most of the time when we are talking about deep learning, we are discussing really complicated architectures – essentially complicated sets of (mostly linear) equations. A second innovation in the application of deep learning though is the use of back propagation to fit under-determined systems. Basically you can feed these systems fairly complicated loss functions, and they will chug along with no problem. See a prior blog post of mine of creating simple regression weights for example.
Recently in the NIJ challenge, I used pytorch and the non-linear fairness function defined by NIJ. In the end me and Gio used an XGBoost model, because the data actually do not have very large differences in false positive rates between racial groups. I figured I would share my example here though for illustration of using pytorch to learn a complicated loss function that has fairness constraints. And here is a link to the data and code to follow along if you want.
First, in text math the NIJ fairness function was calculated as (1 - BS)*(1 - FP_diff), where BS is the Brier Score and FP_diff is the absolute difference in false positive rates between the two groups. My pytorch code to create this loss function looks like this (see the pytorch_mods.py file):
# brier score loss function with fairness constraint
def brier_fair(pred,obs,minority,thresh=0.5):
bs = ((pred - obs)**2).mean()
over = 1*(pred > thresh)
majority = 1*(minority == 0)
fp = 1*over*(obs == 0)
min_tot = (over*minority).sum().clamp(1)
maj_tot = (over*majority).sum().clamp(1)
min_fp = (fp*minority).sum()
maj_fp = (fp*majority).sum()
min_rate = min_fp/min_tot
maj_rate = maj_fp/maj_tot
diff_rate = torch.abs(min_rate - maj_rate)
fin_score = (1 - bs)*(1 - diff_rate)
return -fin_scoreI have my functions all stashed in different py files. But here is an example of loading up all my functions, and fitting my pytorch model to the training recidivism data. Here I set the threshold to 25% instead of 50% like the NIJ competition. Overall the model is very similar to a linear regression model.
import data_prep as dp
import fairness_funcs as ff
import pytorch_mods as pt
# Get the train/test data
train, test = dp.get_y1_data()
y_var = 'Recidivism_Arrest_Year1'
min_var = 'Race' # 0 is White, 1 is Black
x_vars = list(train)
x_vars.remove(y_var)
# Model learning fair loss function
m2 = pt.pytorchLogit(loss='brier_fair',activate='ident',
minority=min_var,threshold=0.25)
m2.fit(train[x_vars],train[y_var])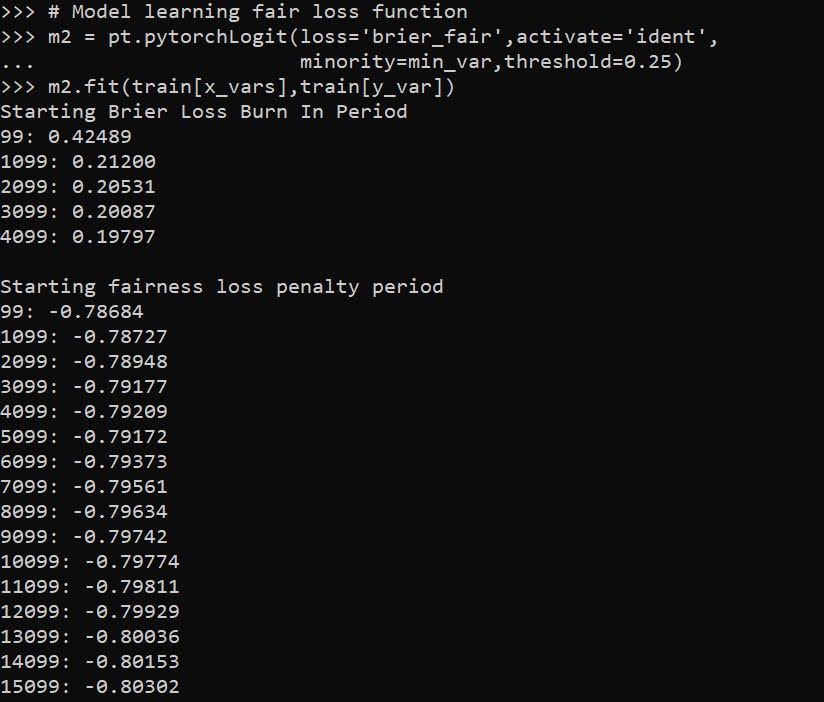
I have a burn in start to get good initial parameter estimates with a more normal loss function before going into the more complicated function. Another approach would be to initialize the weights to the solution for a linear regression equation though. After that burn in though it goes into the NIJ defined fairness loss function.
Now I have functions to see how the different model metrics in whatever sample. Here you can see the model is quite balanced in terms of false positive rates in the training sample:
# Seeing training sample fairness
m2pp = m2.predict_proba(train[x_vars])[:,1]
ff.fairness_metric(m2pp,train[y_var],train[min_var],thresh=0.25)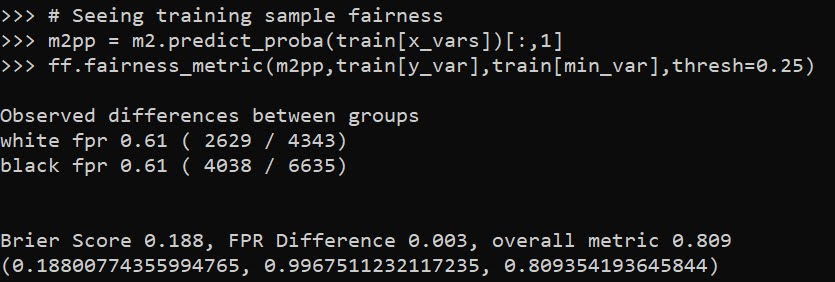
But of course in the out of sample test data it is not perfectly balanced. In general you won’t be able to ensure perfect balance in whatever fairness metrics out of sample.
# Seeing test sample fairness
m2pp = m2.predict_proba(test[x_vars])[:,1]
ff.fairness_metric(m2pp,test[y_var],test[min_var],thresh=0.25)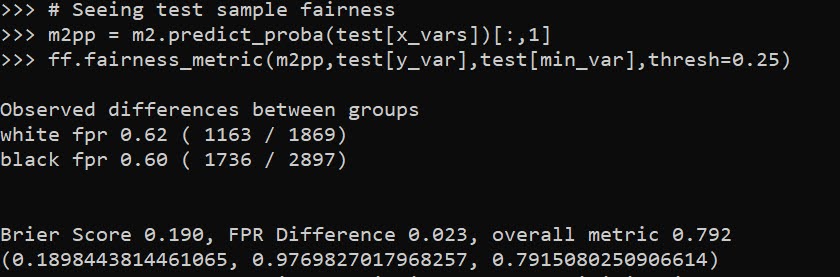
It actually ends up that the difference in false positive rates between the two racial groups, even in models that do not incorporate the fairness constraint in the loss function, are quite similar. Here is a model using the same architecture but just the usual Brier Score loss. (Code not shown, see the m1 model in the 01_AnalysisFair.py file in the shared dropbox link earlier.)
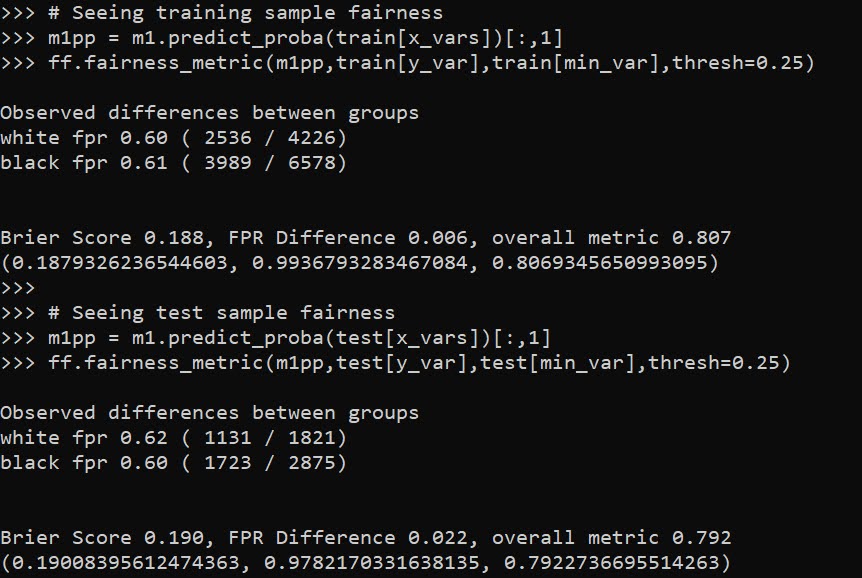
You can read mine and Gio’s paper (or George Mohler and Mike Porter’s paper) about why this particular fairness function is not the greatest. In general it probably makes more sense to use an additive fairness loss instead of multiplicative, but in this dataset it won’t matter very much no matter how you slice it in terms of false positive rates. (It appears in retrospect the Compas data that started the whole false positive thing is somewhat idiosyncratic.)
There are other potential oddities that can occur with such fair loss functions. For example if you had the choice between false positive rates for (white,black) of (0.62,0.60) vs (0.62,0.62), the latter is more fair, but the minority class is worse off. It may make more sense to have an error metric that sets the max false positive rate you want, and then just has weights for different groups to push them down to that set threshold.
These aren’t damning critiques of fair loss functions (these can be amended/changed to behave better), but in the end defining fair loss functions will be very tricky. Both for empirical reasons as well as for ethical ones – they will ultimately involve quite a few trade-offs.

