
So I recently participated in the Decoding Maternal Morbidity Data Challenge. I did not win, but will share my work anyway. I created a genetic algorithm in python to identify sets of association rules that result in high relative risks, genrules. Here I intentionally used a genetic algorithm, with the idea I wanted not just one final model, but a host of different potential rules with the goal of exploratory data analysis.
You can go see how it works by checking out the notebook using the nuMoM2b data (which you have to request, I cannot upload that to github). Here are rules I found to predict high relative risk for infections:
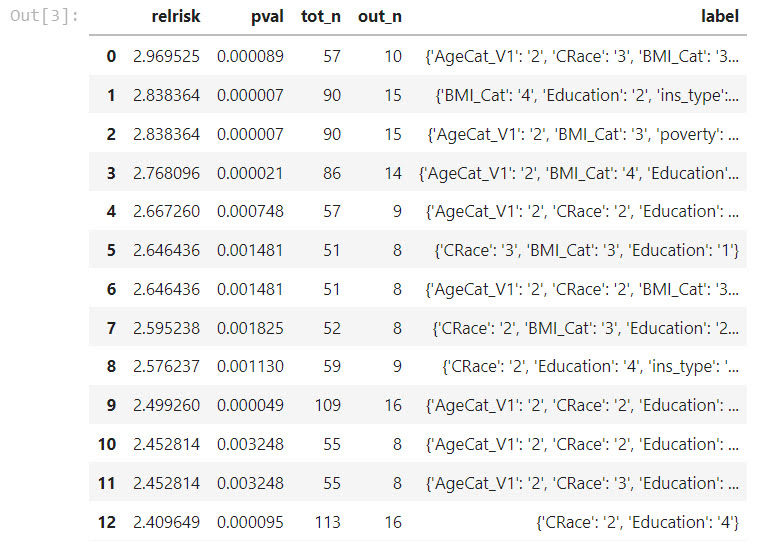
And I have other code to summarize these, it happens to govt insurance is very commonly in the set of rules found.
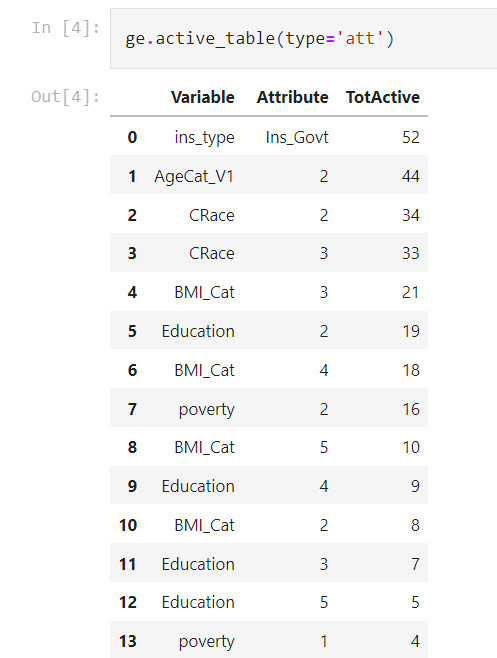
I actually like it better just as a convenient tool (that can take weights), and go through every possible permutation of a set of categorical data. I uploaded a second notebook showing off NIBRS and predicting officer assaults (see my prior blog post on this).
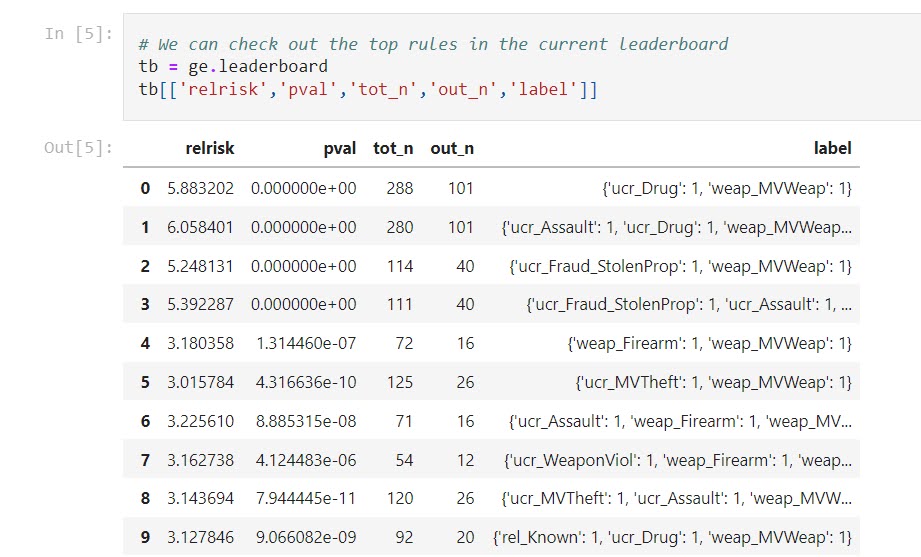
So here one of the rules is stolen property, and the assailant using their motor vehicle as a weapon. So perhaps people running with stolen property in a vehicle? (While I built quite a bit of machinery to look through higher level rules, why bother with higher sets than 3 variables in the vast majority of circumstances.)
This shows the risk of competing in challenges, so a few weekends lost with no reward. This was a fuzzy competition, and something that appears I misread was in the various notes the challenge asked for the creation of novel algorithms. It appears from the titles of the winners people just used typical machine learning approaches and did a deep dive into the data. I did the opposite, created a general tool that could be used by many (who are better experts on the topical material than me).
Also note this approach is very data mining. While I use p-values as a mechanism to penalize too complicated of outcomes in the genetic algorithm, I wouldn’t take those at face value. With large datasets you will always mine some sets that are ultimately confounded.

