I’ve suggested to folks a few times in the past that a popular analysis in CJ, called conjunctive analysis (Drawve et al., 2019; Miethe et al., 2008; Hart & Miethe, 2015), could be automated in a fashion using a popular machine learning technique called association rules. So I figured a blog post illustrating it would be good.
I was motivated by some recent work by Nix et al. (2019) examining officer involved injuries in NIBRS data. So I will be doing a relevant analysis (although not as detailed as Justin’s) to illustrate the technique.
This ended up being quite a bit of work. NIBRS is complicated, and I had to do some rewrites of finding frequent itemsets to not run out of memory. I’ve posted the python code on GitHub here. So this blog post will be just a bit of a nicer walkthrough. I also have a book chapter illustrating geospatial association rules in SPSS (Wheeler, 2017).
A Brief Description of Conjunctive Analysis
Conjunctive analysis is more of an exploratory technique examining high cardinality categorical sets. Or in other words, you search though a database of cases that have many categories to find “interesting” patterns. It is probably easier to see an example than for me to describe it. Here is an example from Miethe et al. (2008):

You can see that here they are looking at characteristics of drug offenders, and then trying to identify particular sets of characteristics that influence the probability of a prison sentence. So this is easy to do in one dimension, it gets very difficult in multiple dimensions though.
Association rules were created for a very different type of problem – identifying common sets of items that shoppers buy together at the same time. But you can borrow that work to aid in conducting conjunctive analysis.
Data Prep for NIBRS
So here I am using 2012 NIBRS data to conduct analysis. Like I mentioned, I was motivated by the Nix and company paper examining officer injuries. They were interested in specifically examining officer involved injuries, and whether the perception that domestic violence cases were more dangerous for officers was justified.
For brevity I only ended up examining five different variable sets in NIBRS (Justin has quite a few more in his paper):
- assault (or injury) type
V4023
- victim/off relationship
V4032
- ucr type
V2006
- drug use
V2009 (also includes computer use!)
- weapon
V2017
All of these variables have three different item sets in the NIBRS codes, and many categories. You will have to dig into the python code, 00_AssocRules.py in the GitHub page to see how I recoded these variables.
Also maybe of interest I have some functions to do one-hot encoding of wide data. So a benefit of NIBRS is that you can have multiple crimes in one incident. So e.g. you can have one incident in which an assault and a burglary occurs. I do the analysis in a way that if you have common co-crimes they would pop out.
Don’t take this as very formal though. Justin’s paper which used 2016 NIBRS data only had 1 million observations, whereas here I have over 5 million (so somewhere along the way me and Justin are using different units of analysis). Also Justin’s incorporates dozens of other different variables into the analysis I don’t here.
It ends up being that with just these four variables (and the reduced sets of codes I created), there still end up being 34 different categories in the data.
Analysis of Frequent Item Sets
The first part of conjunctive analysis (or association rules) is to identify common item sets. So the work of Hart/Miethe is always pretty vague about how you do this. Association rules has the simple approach that you find any item sets, categories in which a particular itemset meets an arbitrary threshold.
So the way you represent the data is exactly how the prior Miethe et al. (2008) data showed, you create a series of dummy 0/1 variables. Then in association rules you look for sets in which for different cases all of the dummy variables take the value of 1.
The code 01_AssocRules.py on GitHub shows this going from the already created dummy variable data. I ended up writing my own function to do this, as I kept getting out of memory errors using the mlextend library. (I don’t know if this is due to my data is large N but smaller number of columns.) You can see my freq_sets function to do this.
Typically in association rules you identify item sets that meet a particular support threshold. Support here just means the proportion of cases that those items co-occur. E.g. if 20% of cases of assault also have a weapon of fists listed. Instead though I wrote the code to have a minimum N, which I choose here to be 1000 cases. (So out of 5 million cases, this is a support of 1/5000.)
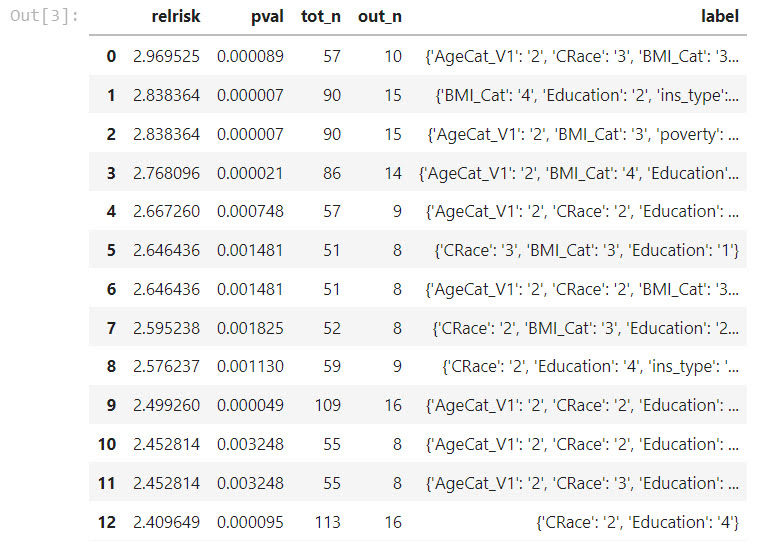
I end up finding a total of 411 frequent item sets in the data that have at least 1000 cases (out of the over 5 million). Here are a few examples, with the frequencies to the left. So there are over 2000 cases in the 2012 NIBRS data that had a known relationship between victim/offender, resulted in assault, the weapon used was fists (or kicking), and involved computer use in some way. I only end up finding two itemsets that have 5 categories and that is it, there are no higher sets of categories that have at least 1000 cases in this dataset.
3509 {'rel_Known', 'ucr_Assault', 'weap_Fists', 'ucr_Drug'}
2660 {'rel_Known', 'ucr_Assault', 'weap_Firearm', 'ucr_WeaponViol'}
2321 {'rel_Known', 'ucr_Assault', 'weap_Fists', 'drug_ComputerUse'}
1132 {'rel_Known', 'ucr_Assault', 'weap_Fists', 'weap_Knife'}
1127 {'ucr_Assault', 'weap_Firearm', 'weap_Fists', 'ucr_WeaponViol'}
1332 {'rel_Known', 'ass_Argument', 'rel_Family', 'ucr_Assault', 'weap_Fists'}
1416 {'rel_Known', 'rel_Family', 'ucr_Assault', 'weap_Fists', 'ucr_Vandalism'}
Like I said I was interested in using NIBRS because of the Nix example. One way we can then examine what variables are potentially related to officer involved injuries during a commission of a crime would be to just pull out any itemsets which include the variable of interest, here ass_LEO_Assault.
4039 {'ass_LEO_Assault'}
1232 {'rel_Known', 'ass_LEO_Assault'}
4029 {'ucr_Assault', 'ass_LEO_Assault'}
1856 {'ass_LEO_Assault', 'weap_Fists'}
1231 {'rel_Known', 'ucr_Assault', 'ass_LEO_Assault'}
1856 {'ucr_Assault', 'ass_LEO_Assault', 'weap_Fists'}
So we see there are a total of just over 4000 officer assaults in the dataset. Unsurprisingly almost all of these also had an UCR offense of assault listed (4029 out of 4039).
Analysis of Association Rules
Sometimes just identifying the common item sets is what is of main interest in conjunctive analysis (see Hart & Miethe, 2015 for an example of examining the geographic characteristics of crime events).
But the apriori algorithm is one way to find particular rules that are of the form if A occurs then B occurs quite often, but swap out more complicated itemsets in the antecedent (A) and consequent (B) in the prior statement, and different ways of quantifying ‘quite often’.
I prefer conditional probability notation to the more typical association rule one, but for typical rules we have (here I use A for antecedent and B for consequent):
- confidence:
P(A & B) / P(B). So if the itemset of just B occurs 20% of the time, and the itemset of A and B together occurs 10% of the time, the confidence would be 50%. (Or more simply the probability of B conditional on A, P(B | A)).
- lift:
confidence(A,B) / P(B). This is a ratio of the baseline a category occurs for the denominator, and the numerator is the prior confidence category. So if you have a baseline B occurring 25% of the time, and the confidence of A & B is 50%, you would then have a lift of 2.
There are other rules as well that folks use, but those are the most common two I am interested in.
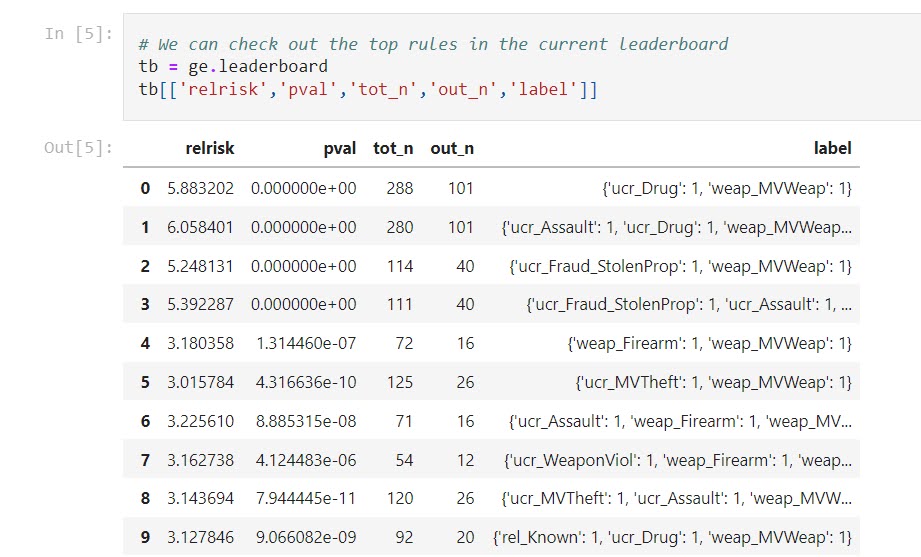
So for example in this data if I draw out rules that have a lift of over 2, I find rules like {'ucr_Vandalism', 'rel_Family'} -> {'ass_Argument'} produces a lift of over 6. (I can use the mlextend implementation here in this code, it was only the frequent itemsets code that was giving me problems.) So it ends up being arguments are listed in the injury codes around 1.6% of the time, but when you have a ucr crime of vandalism, and the relationship between victim/offender are family members, injury type of argument happens around 10.5% of the time (so 10.5/1.6 ~= 6).
The original use case for this is recommender systems/market analysis (so say if you see someone buy A, give them a coupon for B). So this ends up being not so interesting in this NIBRS example when you have you have more clear cause-effect type relationships criminologists would be interested in. But I describe in the next section some further potential machine learning models that may be more relevant, or how I might in the future amend the apriori algorithm for examining specific outcomes.
Further Notes
If you have a particular outcome you are interested in a specific outcome from the get go (so not so much totally exploratory analysis as here), there are a few different options that may make more sense than association rules.
One is the RuleFit algorithm, which basically just uses a regularized regression to find simple models and low order interactions. An example of this idea using police stop data is in Goel et al. (2016). These are very similar in the end to simple decision trees, you can also have continuous covariates in the analysis and it splits them into binary above/below rules. So you could say do RTM distance analysis, and still have it output a rule if < 1000 ft predict high risk. But they are fit in a way that tend to behave better out of sample than doing simple decision trees.
Another is fitting a more complicated model, say random forests, and then having reduced form summaries to describe those models. I have some examples of using shapely values for spatial crime prediction in Wheeler & Steenbeek (2020), but for a more if-then type sets of rules you could look at Scoped Rules.
I may need to dig into the association rules code some more though, and try to update the code to take the sample sizes and statistical significance into account for a particular outcome variable. So if you find higher lift in a four set predicting a particular outcome, you search the tree for more sets with a smaller support in the distribution. (I should probably also work on some cool network viz. to look at all the different rules.)
References
- Drawve, G., Grubb, J., Steinman, H., & Belongie, M. (2019). Enhancing data-driven law enforcement efforts: exploring how risk terrain modeling and conjunctive analysis fit in a crime and traffic safety framework. American Journal of Criminal Justice, 44(1), 106-124.
- Goel, S., Rao, J. M., & Shroff, R. (2016). Precinct or prejudice? Understanding racial disparities in New York City’s stop-and-frisk policy. The Annals of Applied Statistics, 10(1), 365-394.
- Hart, T. C., & Miethe, T. D. (2015). Configural behavior settings of crime event locations: Toward an alternative conceptualization of criminogenic microenvironments. Journal of Research in Crime and Delinquency, 52(3), 373-402.
- Nix, J., Richards, T. N., Pinchevsky, G. M., & Wright, E. M. (2019). Are Domestic Incidents Really More Dangerous to Police? Findings from the 2016 National Incident Based Reporting System. Justice Quarterly Online First.
- Miethe, T. D., Hart, T. C., & Regoeczi, W. C. (2008). The conjunctive analysis of case configurations: An exploratory method for discrete multivariate analyses of crime data. Journal of Quantitative Criminology, 24(2), 227-241.
- Wheeler, A.P. (2017). Geospatial Analytics. In SPSS Statistics for Data Analysis and Visualization, e.d. McCormick, K. & Salecedo, J. Wiley.
- Wheeler, A. P., & Steenbeek, W. (2020). Mapping the risk terrain for crime using machine learning. Journal of Quantitative Criminology Online First.