I have come across several different examples recently where ‘use weights in regression’ was the solution to a particular problem. I will outline four recent examples.
Example 1: Rates in WDD
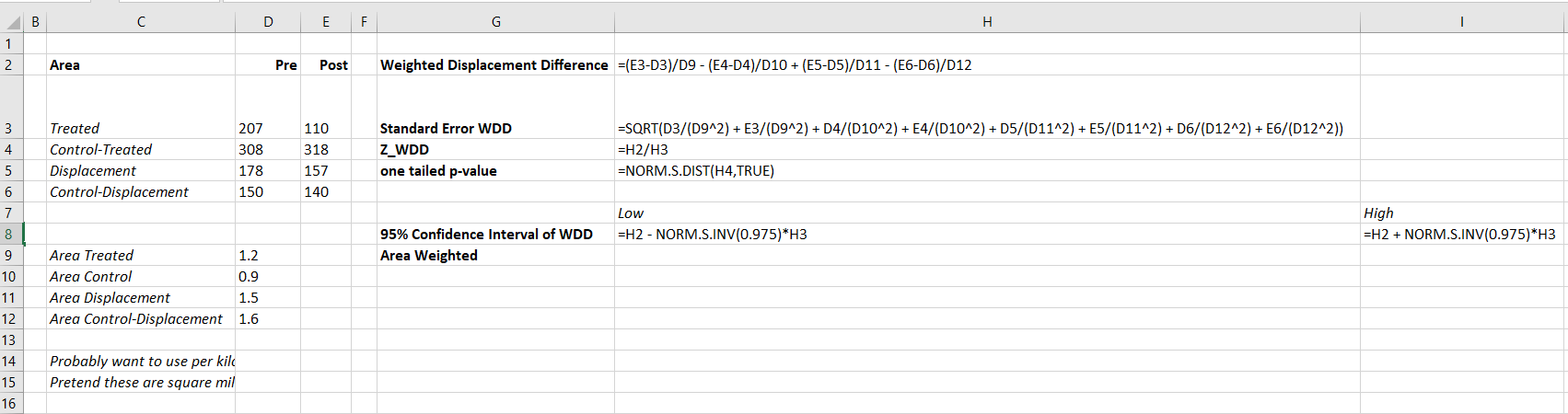
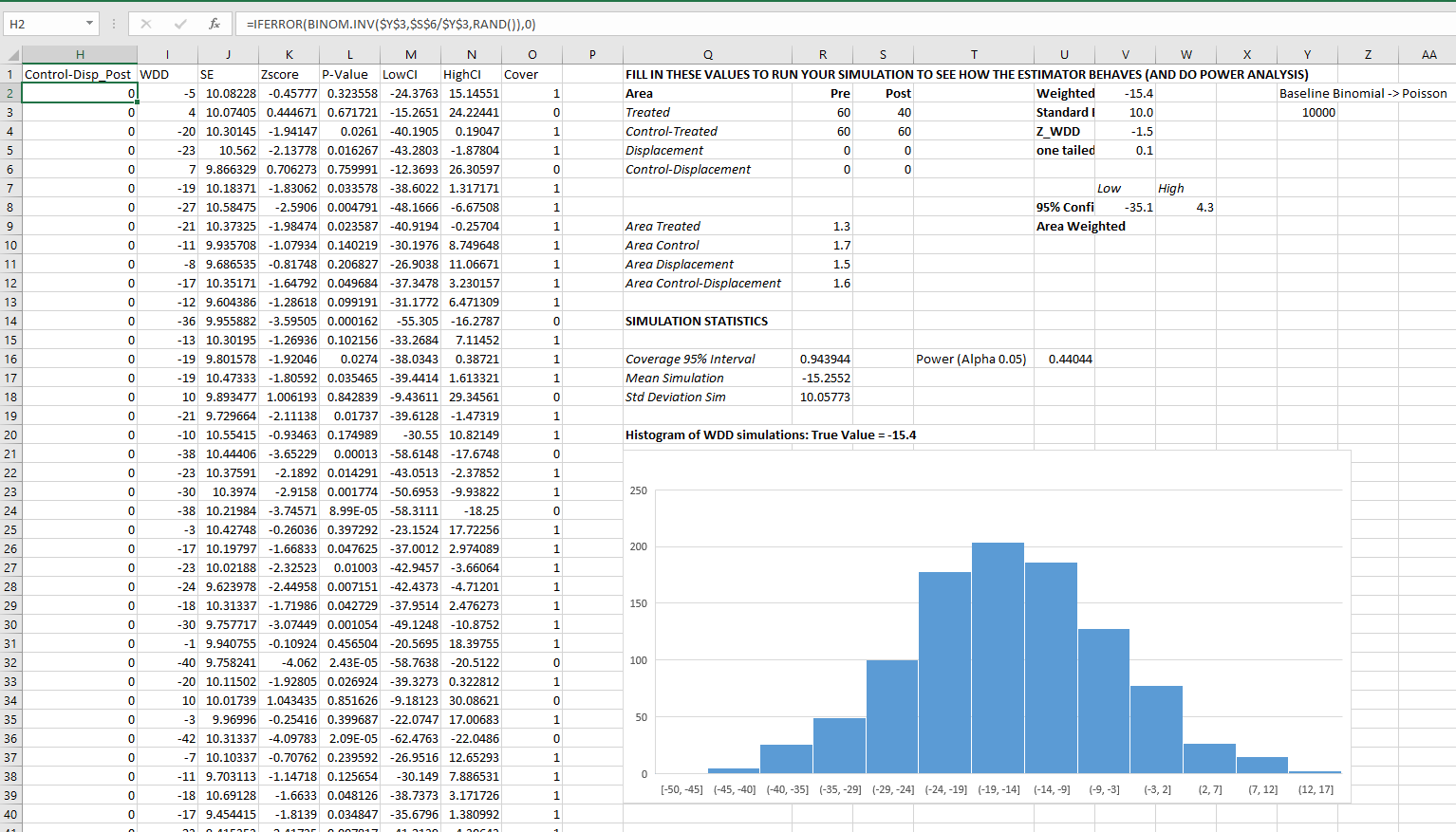
Sophie Curtis-Ham asks whether I can extend my WDD rate example to using the Poisson regression approach I outline. I spent some time and figured out the answer is yes.
First, if you install my R package ptools, we can use the same example in that blog post showing rates (or as per area, e.g. density) in my internal wdd function using R code (Wheeler & Ratcliffe, 2018):
library(ptools)
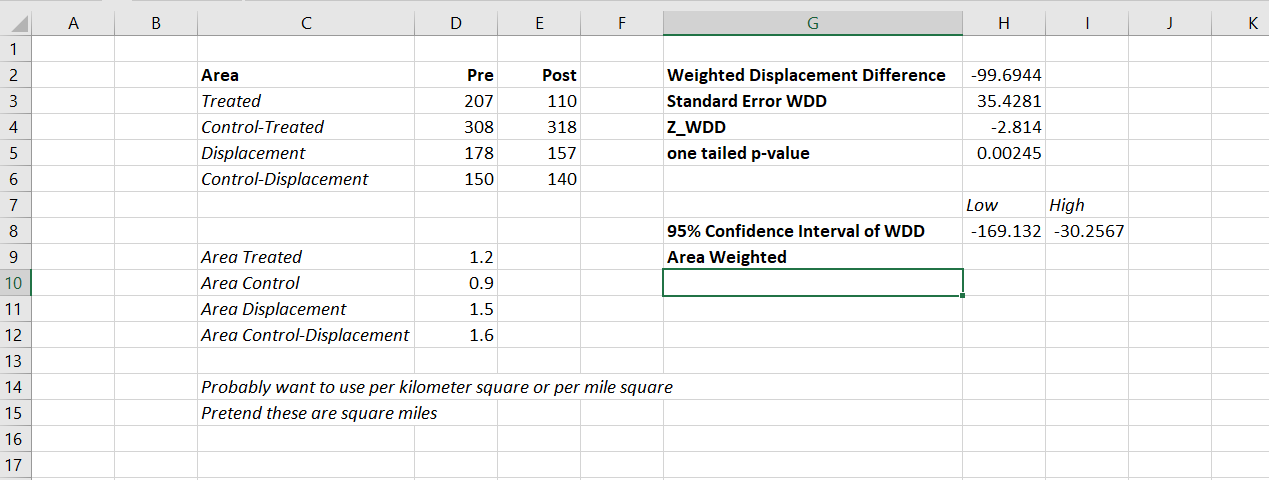
crime <- c(207,308,178,150,110,318,157,140)
type <- c('t','ct','d','cd','t','ct','d','cd')
ti <- c(0,0,0,0,1,1,1,1)
ar <- c(1.2,0.9,1.5,1.6,1.2,0.9,1.5,1.6)
df <- data.frame(crime,type,ti,ar)
# The order of my arguments is different than the
# dataframe setup, hence the c() selections
weight_wdd <- wdd(control=crime[c(2,6)],
treated=crime[c(1,5)],
disp_control=crime[c(4,8)],
disp_treated=crime[c(3,7)],
area_weights=ar[c(2,1,4,3)])
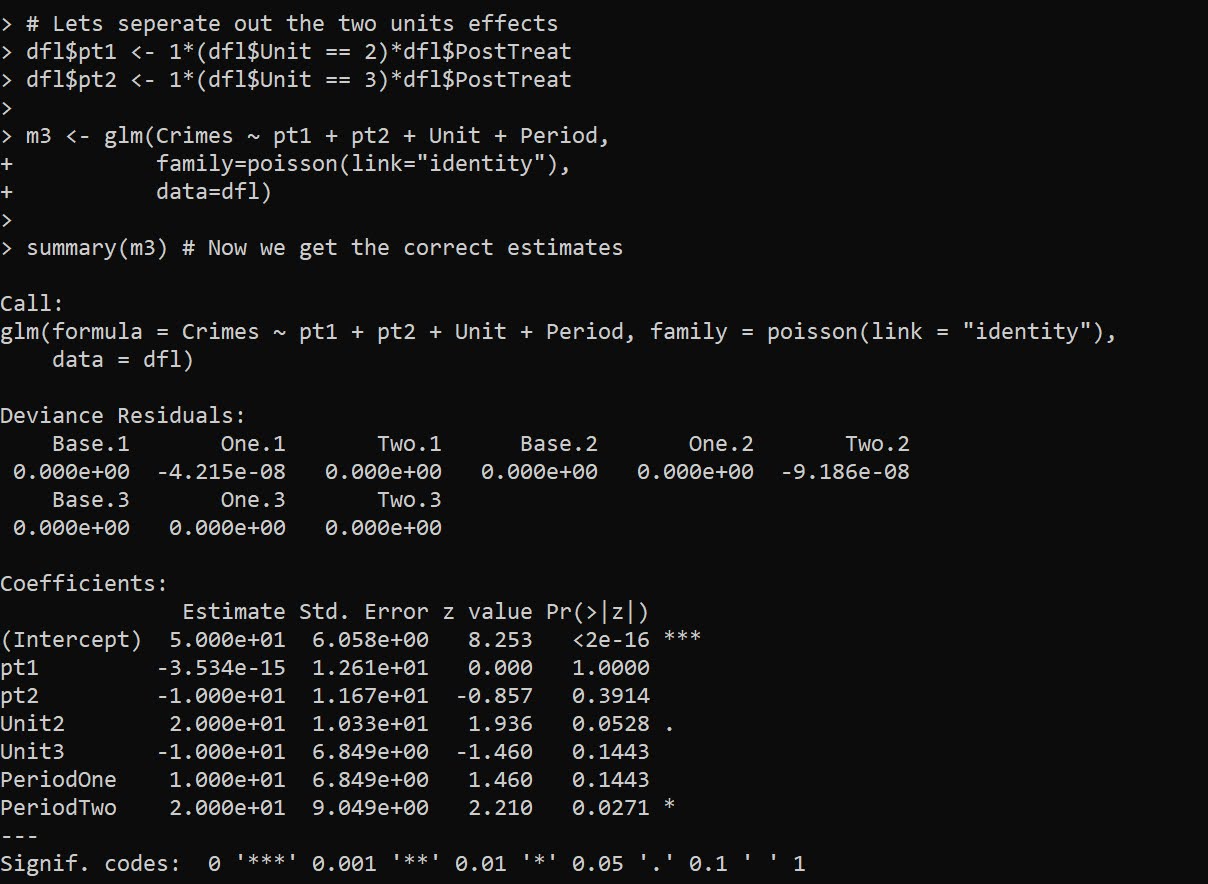
# Estimate -91.9 (31.5) for localSo here the ar vector is a set of areas (imagine square miles or square kilometers) for treated/control/displacement/displacementcontrol areas. But it would work the same if you wanted to do person per-capita rates as well.
Note that the note says the estimate for the local effect, in the glm I will show I am just estimating the local, not the displacement effect. At first I tried using an offset, and that did not change the estimate at all:
# Lets do a simpler example with no displacement
df_nod <- df[c(1,2,5,6),]
df_nod['treat'] <- c(1,0,1,0)
df_nod['post'] <- df_nod['ti']
# Attempt 1, using offset
m1 <- glm(crime ~ post + treat + post*treat + offset(log(ar)),
data=df_nod,
family=poisson(link="identity"))
summary(m1) # estimate is -107 (30.7), same as no weights WDDMaybe to get the correct estimate via the offset approach you need to do some post-hoc weighting, I don’t know. But we can use weights and estimate the rate on the left hand side.
# Attempt 2, estimate rate and use weights
# suppressWarnings is for non-integer notes
df_nod['rate'] <- df_nod['crime']/df_nod['ar']
m2 <- suppressWarnings(glm(rate ~ post + treat + post*treat,
data=df_nod,
weights=ar,
family=poisson(link="identity")))
summary(m2) # estimate is same as no weights WDD, -91.9 (31.5)The motivation again for the regression approach is to extend the WDD test to scenarios more complicated than simple pre/post, and using rates (e.g. per population or per area) seems to be a pretty simple thing people may want to do!
Example 2: Clustering of Observations
Had a bit of a disagreement at work the other day – statistical models used for inference of coefficients on the right hand side often make the “IID” assumption – independent and identically distributed residuals (or independent observations conditional on the model). This is almost entirely focused on standard errors for right hand side coefficients, when using machine learning models for purely prediction it may not matter at all.
Even if interested in inference, it may be the solution is to simply weight the regression. Consider the most extreme case, we simply double count (or here repeat count observations 100 times over):
# Simulating simple Poisson model
# but replicating data
set.seed(10)
n <- 600
repn <- 100
id <- 1:n
x <- runif(n)
l <- 0.5 + 0.3*x
y <- rpois(n,l)
small_df <- data.frame(y,x,id)
big_df <- data.frame(y=rep(y,repn),x=rep(x,repn),id=rep(id,repn))
# With small data
mpc <- glm(y ~ x, data=small_df, family=poisson)
summary(mpc)
# Note same coefficients, just SE are too small
mpa <- glm(y ~ x, data=big_df, family=poisson)
vcov(mpc)/vcov(mpa) # ~ 100 times too smallSo as expected, the standard errors are 100 times too small. Again this does not cause bias in the equation (and so will not cause bias if the equation is used for predictions). But if you are making inferences for coefficients on the right hand side, this suggests you have way more precision in your estimates than you do in reality. One solution is to simply weight the observations inverse the number of repeats they have:
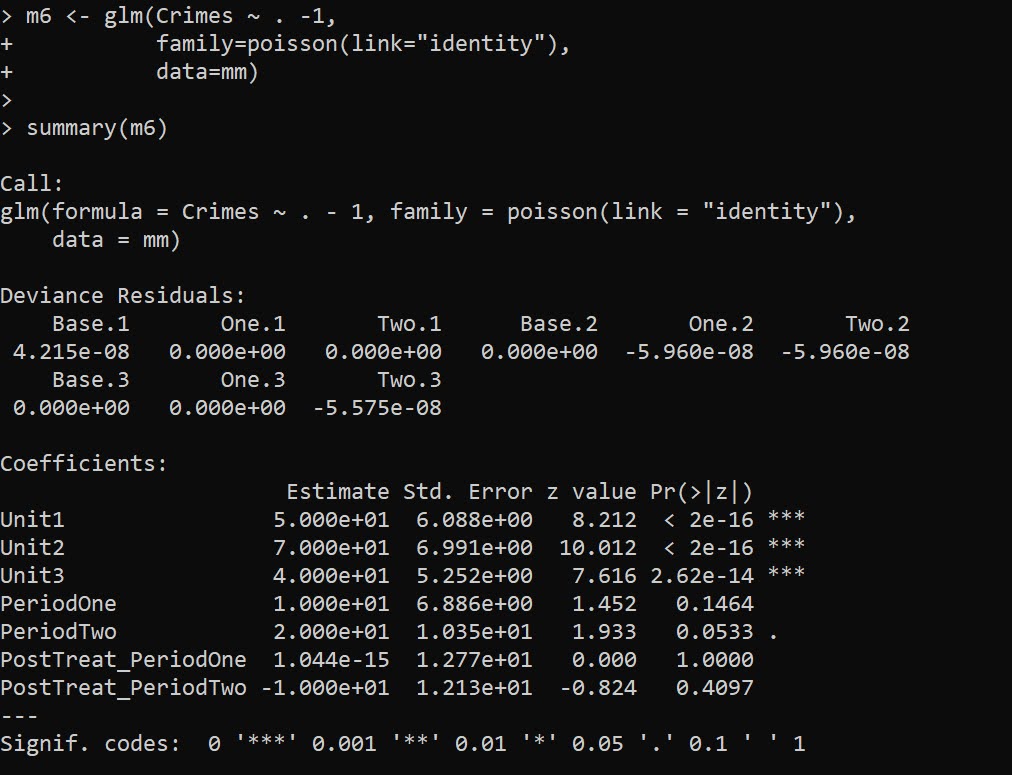
big_df$w <- 1/repn
mpw <- glm(y ~ x, weight=w, data=big_df, family=poisson)
summary(mpw)
vcov(mpc)/vcov(mpw) # correct covariance estimatesAnd this will be conservative in many circumstances, if you don’t have perfect replication across observations. Another approach though is to cluster your standard errors, which uses data to estimate the residual autocorrelation inside of your groups.
library(sandwich)
adj_mpa <- vcovCL(mpa,cluster=~id,type="HC2")
vcov(mpc)/adj_mpa # much closer, still *slightly* too smallI use HC2 here as it uses small sample degree of freedom corrections (Long & Ervin, 2000). There are quite a few different types of cluster corrections. In my simulations HC2 tends to be the “right” choice (likely due to the degree of freedom correction), but I don’t know if that should generally be the default for clustered data, so caveat emptor.
Note again though that the cluster standard error adjustments don’t change the point estimates at all – they simply adjust the covariance matrix estimates for the coefficients on the right hand side.
Example 3: What estimate do you want?
So in the above example, I exactly repeated everyone 100 times. You may have scenarios where you have some observations repeated more times than others. So above if I had one observation repeated 10 times, and another repeated 2 times, the correct weights in that scenario would be 1/10 and 1/2 for each row inside the clusters/repeats. Here is another scenario though where we want to weight up repeat observations though – it just depends on the exact estimate you want.
A questioner wrote in with an example of a discrete choice type set up, but some respondents are repeated in the data (e.g. chose multiple responses). So imagine we have data:
Person,Choice
1 A
1 B
1 C
2 A
3 B
4 B If you want to know the estimate in this data, “pick a random person-choice, what is the probability of choosing A/B/C?”, the answer is:
A - 2/6
B - 3/6
C - 1/6But that may not be what you really want, it may be you want “pick a random person, what is the probability that they choose A/B/C?”, so in that scenario the correct estimate would be:
A - 2/4
B - 3/4
C - 1/4To get this estimate, we should weight up responses! So typically each row would get a weight of 1/nrows, but here we want the weight to be 1/npersons and constant across the dataset.
Person,Choice,OriginalWeight,UpdateWeight
1 A 1/6 1/4
1 B 1/6 1/4
1 C 1/6 1/4
2 A 1/6 1/4
3 B 1/6 1/4
4 B 1/6 1/4And this extends to whatever regression model if you want to model the choices as a function of additional covariates. So here technically person 1 gets triple the weight of persons 2/3/4, but that is the intended behavior if we want the estimate to be “pick a random person”.
Depending on the scenario you could do two models – one to estimate the number of choices and another to estimate the probability of a specific choice, but most people I imagine are not using such models for predictions so much as they are for inferences on the right hand side (e.g. what influences your choices).
Example 4: Cross-classified data
The last example has to do with observations that are nested within multiple hierarchical groups. One example that comes up in spatial criminology – we want to do analysis of some crime reduction/increase in a buffer around a point of interest, but multiple buffers overlap. A solution is to weight observations by the number of groups they overlap.
For example consider converting incandescent street lamps to LED (Kaplan & Chalfin, 2021). Imagine that we have four street lamps, {c1,c2,t1,t2}. The figure below display these four street lamps; the t street lamps are treated, and the c street lamps are controls. Red plus symbols denote crime locations, and each street lamp has a buffer of 1000 feet. The two not treated circle street lamps overlap, and subsequently a simple buffer would double-count crimes that fall within both of their boundaries.

If one estimated a treatment effect based on these buffer counts, with the naive count within buffer approach, one would have:
c1 = 3 t1 = 1
c2 = 4 t2 = 0Subsequently an average control would then be 3.5, and the average treated would be 0.5. Subsequently one would have an average treatment effect of 3. This however would be an overestimate due to the overlapping buffers for the control locations. Similar to example 3 it depends on how exactly you want to define the average treatment effect – I think a reasonable definition is simply the global estimate of crimes reduced divided by the total number of treated areas.
To account for this, you can weight individual crimes. Those crimes that are assigned to multiple street lamps only get partial weight – if they overlap two street lamps, the crimes are only given a weight of 0.5, if they overlap three street lamps within a buffer area those crimes are given a weight of 1/3, etc. With such updated weighted crime estimates, one would then have:
c1 = 2 t1 = 1
c2 = 3 t2 = 0And then one would have an average of 2.5 crimes in the control street lamps, and subsequently would have a treatment effect reduction per average street lamp of 2 crimes overall.
This idea I first saw in Snijders & Bosker (2011), in which they called this cross-classified data. I additionally used this technique with survey data in Wheeler et al. (2020), in which I nested responses in census tracts. Because responses were mapped to intersections, they technically could be inside multiple census tracts (or more specifically I did not know 100% what tract they were in). I talk about this issue in my dissertation a bit with crime data, see pages 90-92 (Wheeler, 2015). In my dissertation using D.C. data, if you aggregated that data to block groups/tracts the misallocation error is likely ~5% in the best case scenario (and depending on data and grouping, could be closer to 50%).
But again I think a reasonable solution is to weight observations, which is not much different to Hipp & Boessan’s (2013) egohoods.
References
- Hipp, J. R., & Boessen, A. (2013). Egohoods as waves washing across the city: A new measure of “neighborhoods”. Criminology, 51(2), 287-327.
- Kaplan, J., & Chalfin, A. (2021). Ambient lighting, use of outdoor spaces and perceptions of public safety: evidence from a survey experiment. Security Journal, Online First.
- Long, J. S., & Ervin, L. H. (2000). Using heteroscedasticity consistent standard errors in the linear regression model. The American Statistician, 54(3), 217-224.
- Snijders, T. A., & Bosker, R. J. (2011). Multilevel analysis: An introduction to basic and advanced multilevel modeling. Sage.
- Wheeler, A.P. (2015). What we can learn from small units of analysis. Dissertation, SUNY Albany.
- Wheeler, A.P., & Ratcliffe, J.H. (2018). A simple weighted displacement difference test to evaluate place based crime interventions. Crime Science, 7(1).
- Wheeler, A. P., Silver, J. R., Worden, R. E., & Mclean, S. J. (2020). Mapping attitudes towards the police at micro places. Journal of Quantitative Criminology, 36(4), 877-906.