So you probably learned about confidence intervals around means in your introductory statistics class. For a refresher, a confidence interval covers a particular statistic at a pre-specified rate. So if I generate 100 90% intervals around a mean, I expect that those confidence intervals would cover the true underlying mean around 90 times out of those 100. So it is a statement about the procedure overall – not any individual test.
This repeated coverage property is often not exactly what we want in statistics. But, I often find examining confidence intervals around samples to be an informative way to quantify uncertainty in estimates. For example, I have a machine learning model serving up predictions to a subsequent auditing process. I expect this to maintain a hit rate above 20%. The past week I only had a hit rate of 30/200 (15%), should I be worried? Probably not, a 95% confidence interval around that proportion is 10% to 21%.
Proportions come up so often that intro stats courses should probably talk more extensively about generating confidence intervals around them. There are many different confidence intervals for proportions, Wikipedia lists 7 different options!
I prefer where possible to use the Clopper-Pearson intervals by default. I will show an examples of generating Clopper-Pearson intervals in Excel and Python. But, another situation I have come across is I want to do these intervals entirely in SQL. For that situation, I will show how to use Agresti–Coull intervals.
Excel Clopper-Pearson
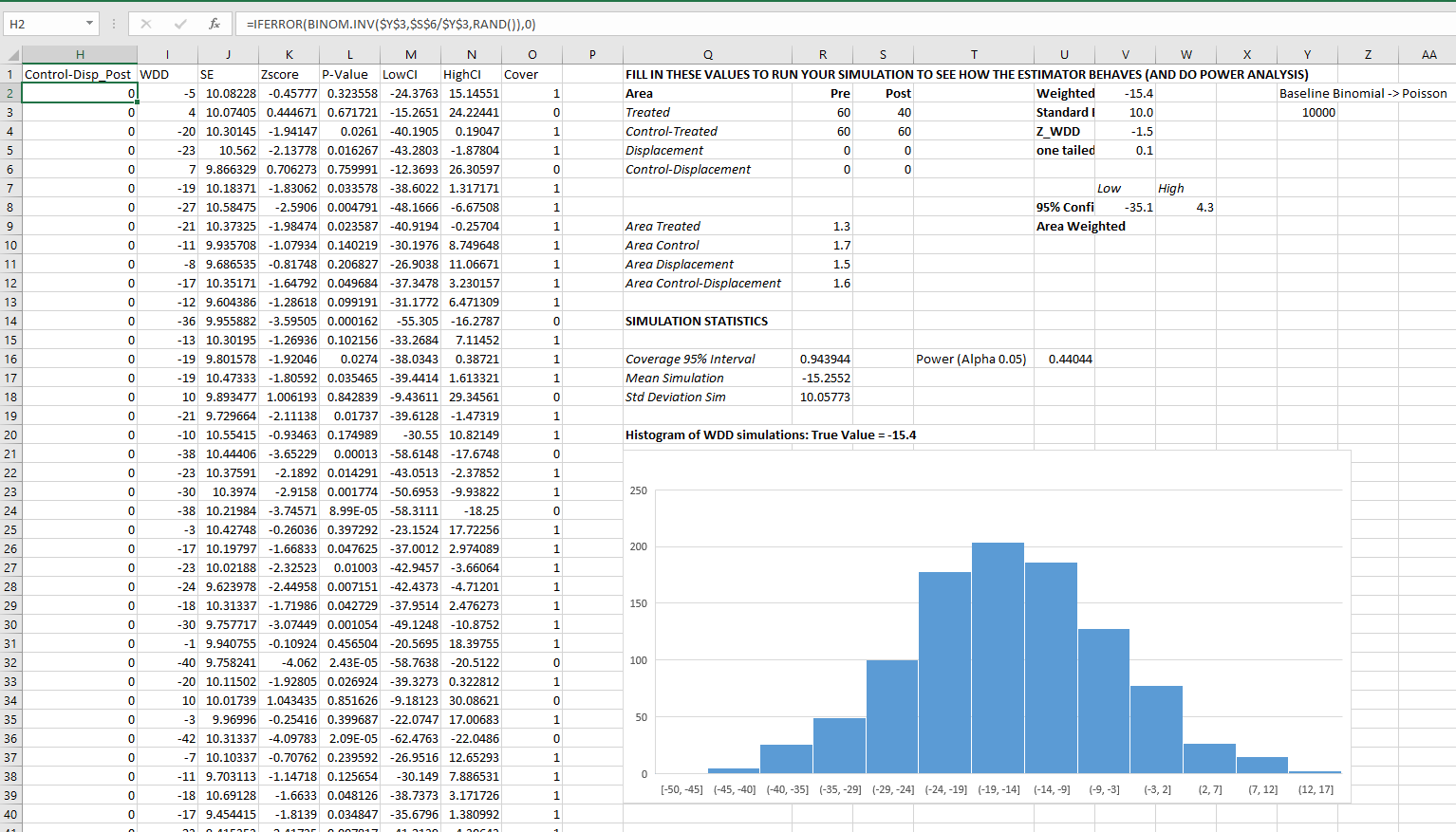
In Excel, if the A column contains the numerator, the B column contains the denominator, and if G1 has the alpha level, this brutish formula gets you the lower bound of your confidence interval;
=IF(A2=0, 0, BETA.INV($G$1/2, A2, B2-A2+1))
A here is your upper bound;
=IF(A2=B2, 1, BETA.INV(1-$G$1/2, A2+1, B2-A2))
And here is a screenshot of the filled in results:
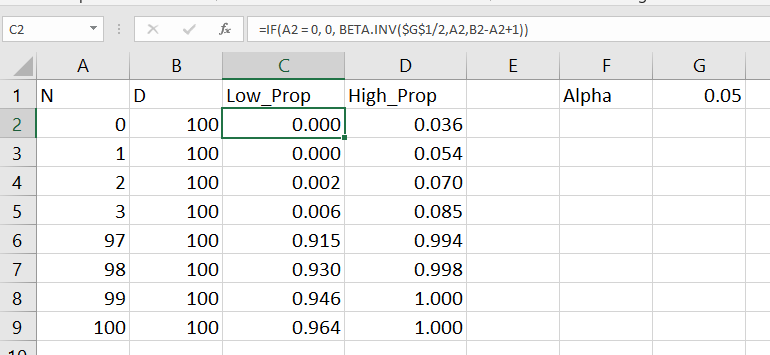
Note for my criminology friends, you can use this for very extreme proportions as well. So say you had a homicide rate of 10 per 100,000, where the observed sample was 30 homicides in a city of 300,000. You can generate a binomial confidence interval around the proportion and then translate back to the rate per 100,000. So in that scenario, it results in a 95% confidence interval of a homicide rate of 6.7 to 14.3.
This is actually the reason I like defaulting to Clopper-Pearson. The other approximations can fail very badly for extreme tail events like this.
Python Clopper-Pearson
Here is a simple function in python to return the Clopper-Pearson intervals. This works for vectorized inputs as well (e.g. numpy arrays or pandas series).
import numpy as np
from scipy.stats import beta
def binom_int(num,den, confint=0.95):
quant = (1 - confint)/ 2.
low = beta.ppf(quant, num, den - num + 1)
high = beta.ppf(1 - quant, num + 1, den - num)
return (np.nan_to_num(low), np.where(np.isnan(high), 1, high))
And here is an example use:
hits = np.array([0, 1, 2, 3, 97, 98, 99, 100])
tries = np.array([100]*len(hits))
lowCI, highCI = binom_int(hits, tries)
Check out my prior blog post on making smoothed scatterplots on how to plot those proportion spikes in matplotlib.
SQL Agresti–Coull
So as I mentioned previously, I prefer the Clopper-Pearson intervals. This however relies on the availability of a function for the inverse beta distribution. One common situation is I just have all my tables in SQL, and I want to make a dashboard connected to a view of my tables. So the proportion of some event broken downs by days/weeks/months etc.
In that case exporting the data to python and re-uploading to the database can be a bit of a hassle, whereas creating a view is much less work. So here is an example query to calculate the proportion intervals entirely in SQL. So the initial table is a micro level table of events with 0/1 for a particular group. (This screenshot is for Access, but this should work in various databases.)
And then it is a groupby to get the original numerator, denominator, and proportion. Then a few rows calculating the adjusted proportion (add 2 to the numerator and 2*2 to the denominator), then finally this can still produce lower than 0 and higher than 1 intervals, so I cap those off.
/* This is for Access, for others may want to use SQRT() instead of SQR()
Also may want to use CASE WHEN instead of IIF */
SELECT
GroupID,
SUM(Outcome) AS Num,
COUNT(Outcome) AS Den,
Num/Den AS Prop,
Num + 2 AS nadj,
Den + 2*2 as dadj,
nadj/dadj as padj,
2*SQR((padj/nadj)*(1 - padj)) AS zadj,
IIF( padj < zadj, 0, padj - zadj) AS LowCI,
IIF( (1 - padj) < zadj, 1, padj + zadj) AS HighCI
FROM ExampleData
GROUP BY GroupID;
This produces a 95% confidence interval for the final two columns. If you wanted to generate say a 99% confidence interval, you would replace the 2’s in the above table with 2.6. (In R you can do qnorm(1 - a/2), where a is 1 - confidence_level, to figure out this constant.)

What you shouldn’t use these intervals for
While I believe many applications of dashboards are well suited to including confidence intervals, confidence intervals (like p-values) are apt to be misinterpreted. One common one is that for a single 95% confidence interval, that does not mean the interval covers the true estimate with a 95% probability. This is an inference for an individual sample that is not possible in frequentist statistics – that summary would be akin to a posterior credible interval in Bayesian statistics. Confidence intervals are about the procedure, if we do this procedure over and over again, in the long run it will cover the true statistic (which we do not observe for any individual sample), according to the level we set.
Another common mistake with confidence intervals is when comparing two different intervals, them overlapping is sometimes interpreted as no difference. But this is a very conservative test (e.g. will fail to reject the null of no differences too often).
So say we were monitoring a process over time, and in October the process was 20% (40/200) and in November it was 28% (168/600). October’s confidence interval is 15% to 26%, and November’s confidence interval is 24% to 32%. So since those intervals overlap, we should conclude there are no differences correct? Not exactly, if we do a direct test for the differences in proportions (akin to a t-test of mean differences), we get a confidence interval of the difference as -14% to -1% (in R prop.test(c(40,168), c(200,600))). So in that direct hypothesis test, we would conclude October’s percent is lower than Novembers percent.
Geoff Cumming suggests that when going from individual confidence intervals to comparisons between groups, one confidence interval needs to cover the point estimate for the other group to conclude the two groups are different.
But that being said, I believe many dashboards would be improved if incorporating such confidence intervals. So although they may not always provide the test of interest, they are a good way to prevent yourself from over-interpreting noisy trends in smaller samples. In the case of comparing two intervals, for most situations I deal with, being conservative in saying this process is not showing differences is a better approach than worrying about minor fluctuations (although just depends on the use case whether that default behavior makes sense.)
So please, when reporting proportions with small samples, provide a confidence interval around those proportions!