
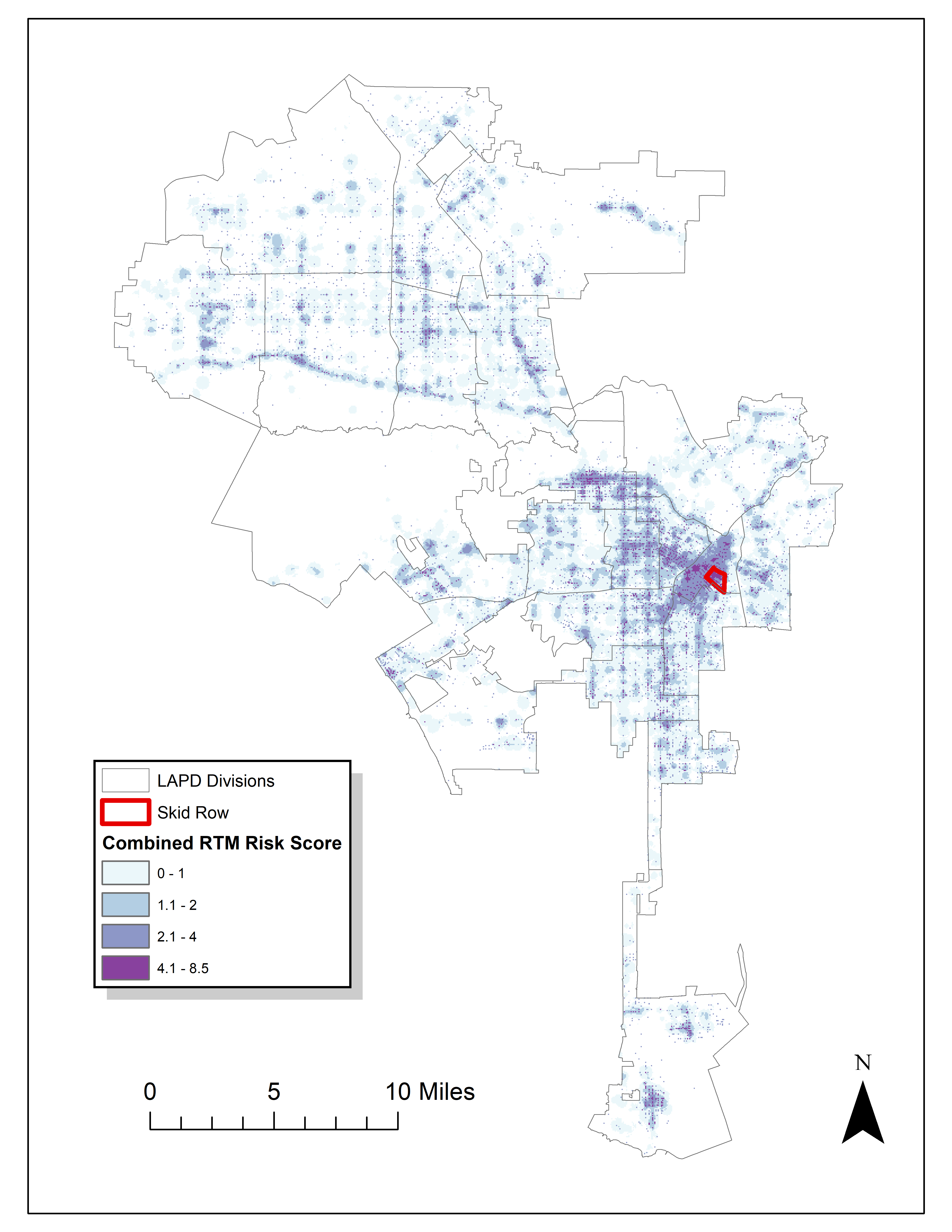
Read an article by Tim Hart the other day (part of a special issue I will have an article in as well here soon). In it he evaluated hot spot methods not only by how well they forecast crime, but also by the clumpiness of the hot spot method. Some hot spot methods, such as risk terrain modeling (Caplan et al., 2020; Fox et al., 2021), machine learning models (Wheeler & Steenbeek, 2020), or self-exciting point process models (Mohler et al., 2018) can by their nature produce discontinuous hot spots. Here is an example of a RTM map I made in Yoo & Wheeler (2019) for homeless related crime in Los Angeles, and you can see this is quite spotty in the ups/downs in the high risk areas:
Other hot spot methods, like hierarchical clustering (Wheeler & Reuter, 2020) or kernel density maps however this is not as big an issue. Here is an example kernel density map also from Yoo & Wheeler (2019) based on the same data:

So you can see how the hot spots in the kernel density map are spatially contiguous, whereas the RTM example can be little hot spots all over the jurisdiction. So it is obviously easier to patrol a single contiguous area than many islands over the entire jurisdiction. So it may make sense to trade off a contiguous area that captures somewhat fewer crimes than speckled areas that are all over the map.
Adepeju et al. (2016) was the first to use a particular statistic, the clumpiness index, to evaluate different hot spot methods. Their figure below is a pretty good depiction of the idea – count up the number of internal edges to a hot spot (when a hot spot grid-cell neighbors another hot spot), and the number of external edges. Then it is just a particular formula to make the index range from -1 to 1 given different sized hot spots.

So here I flip this idea on its head abit – instead of using a particular hot spot technique and see its clumpiness, I formulate a linear program given a prediction to trade off a smaller number of predicted crimes in the hot spot vs making the hot spot areas more clumpy. I illustrate my clumpy hot spots using just prior data to predict future data, in particular thefts from motor vehicles in Raleigh North Carolina.
I have posted the data/code on github here. It is a bit too long to embed the code directly in the blog post, but just see the 00_PrepData.py file. The crime data and Raleigh border I downloaded from the Raleigh open data website.
A Linear Program to Clump Hot Spots
So for some quick and dirty math in text, the linear program I formulate is:
Maximize { Sum[ theta*S_i*Crime_i + (1 - theta)*E_i ] }
Subject To:
1) Sum( S_i ) = k
2) E_i <= Sum(S_n for n in neighbors(i) ) for each i
3) E_i <= S_i for each i
4) S_i element of {0,1}, E_i >= 0 (and can be continuous)The idea behind this is that if theta=1, this is the same as just taking whatever your input areas are and ranking them to pick the top k areas. So if you have 10000 500 by 500 foot grid cells as your spatial units of analysis, and you wanted the top 1% of the city, that is 100 grid cells. So you would choose k=100 in that scenario. Crime_i here I use as prior counts of crime in the grid cell, but it could be the predicted value from whatever model as well. That is the first constraint in this model approach – you need to choose the total area you want. S_i are the decision variables for the final selected hot spot areas.
The second and third constraints determine the values for the second set of decision variables, E_i. These are the decision variables that encode the interconnected links when a selected grid cell touches another grid cell. Constraint 2 sets E_i to the total number of neighbors of i that are selected, except constraint 3 says if S_i is 0 E_i needs to be 0 as well.
In this formulation, S_i need to be integer variables, but the E_i are defined by the sum of S_i, so they can be continuous. In this formulation if you have N grid cells (or whatever spatial units of analysis), this results in 2*N decision variables, and 2*N + 1 constraints. You could maybe save a few constraints here by working with an undirected graph instead of a directed one (in essence this double counts, a-b and b-a would count as two links). But this will just make it 1.5*N constraints instead of 2*N. So not a big deal probably. I did have some issues solving this using pulps default coin/GLPK solver. But CPLEX solved it no problem. (My example is a total of 20,986 500 by 500 foot grid cells, and I use rook contiguity like the Adepeju article as well. And using CPLEX it solves the models in just a few seconds.)
In this formulation you can think of theta as trading off crimes in the hot spot vs interior edges. So imagine you had theta=0.9, and you had a solution with 200 crimes and 100 interior edges. The objective function in that scenario would be 0.9*200 + 0.1*100 = 190. Now imagine you had an alternative scenario with 190 crimes, but 200 internal edges, the objective function would be 0.9*190 + 0.1*200 = 191. So you are saying, it is ok to have hot spots capture a smaller number of crimes, if they are more connected.
Normal Hotspots vs Clumpy Ones in Raleigh
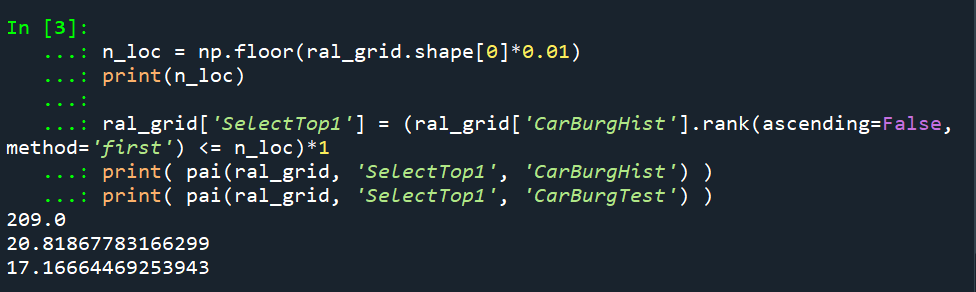
The open data I use for Raleigh, North Carolina for the NIBRS dataset goes back to June 2014, and has data updated in the beginning of March 2021. I pull out larcenies from motor vehicles, and for the historical train dataset use car larcenies from 2014 through 2019 (n = 17,681). For the test dataset I use car larcenies in 2020 and what is available so far in 2021 (n = 3,376). Again these are grid cells generated over the city boundaries at 500 by 500 foot intervals. For illustration I grab out the top 1% of the city (209 grid cells). I use a train/test dataset as out of sample test data will typically result in reduced predictions. Here are the PAI stats for train vs test when selecting the top 1%.
For all subsequent selections I always use the historical training data to select the hot spots, and the test dataset to evaluate the PAI.
If we do the typical approach of just taking the highest crime grid cells based on the historical data, here are the results both for the PAI and the CI (clumpy index). For those not familiar, PAI is % Crime Capture/% Area, so if the denominator is 1%, and the PAI (for the test data) is 17, that means the hot spots capture 17% of the total thefts from vehicles. The CI ranges from -1 (spread apart) to 1 (entirely clustered). Here it is just over 0, suggesting these are basically randomly distributed in terms of clustering.

You may think that almost spatial randomness in terms of clumping seems at odds with that crime clusters! But it is not really – a consistent relationship with crime hot spots is that they are intensely localized, and often you can go down the street and be in a low crime area (Harries, 2006). The same idea when people say high crime neighborhoods often are spotty interior – they tend to have mostly low crime areas and just a few specific hot spots.
OK, so now to show off my linear program. So what happens if we use theta=0.9?

The total crime numbers are here for the historical data, and it ends up capturing the exact same number of crimes as the select top 1% does (3,664). But, it switches the selection of one of the areas. So what happens here is that we have ties – even with basically little weight assigned to the interior connections, it will prioritize tied crime areas to be connected to other chosen hot spots (whereas before the ties are just random in the way I chose the top 1%). So if you have many ties at the threshold for your hot spot, this is a great way to prioritize particular tied areas.
What happens if we turn down theta to 0.5? So this is saying you would trade off one for one – one interior edge is equal to one crime.

You can see that it changed the selections slightly more here, traded off 24 areas compared to the original just rank solution. Lets check out the map and the CI:

The CI value is now 0.17 (up from 0.08). You can see some larger blobs, but it is still pretty spread apart. But the reduction in the total number of crimes captured is pretty small, going from a PAI of 17 to now a PAI of 16. How about if we crank down theta even more to 0.2?
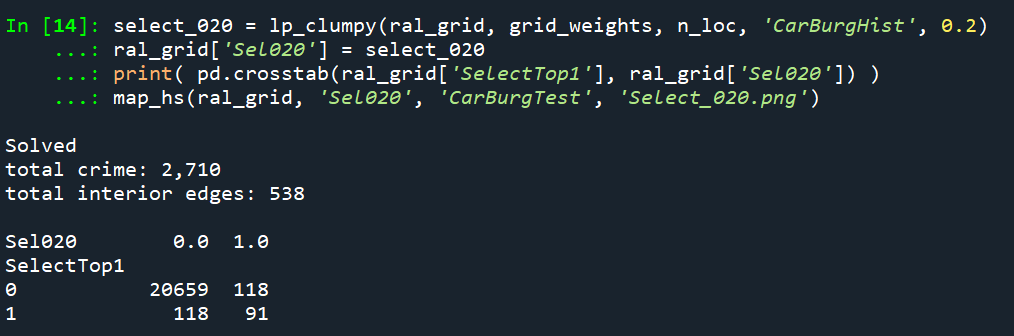
This trades off a much larger number of areas and total amount of crime – over half of the chosen grid cells are flipped in this scenario. In the subsequent map you can see the hot spots are much more clumpy now, and have a CI of 0.64.

The PAI of 12.6 is a bit of a hit as well, but is not too shabby still. I typically take a PAI of 10 to be the ballpark of what is reasonable based on Weisburd’s Law of Crime Concentration – 5% of the areas contain 50% of the crime (which is a PAI of 10).
So this shows one linear programming approach to trade off clumpy chosen areas vs disconnected speckles over the map. It may be the case though that other approaches are more reasonable, such as using some type of clustering to begin with. E.g. I could use DBSCAN on the gridded predicted values (Wheeler & Reuter, 2020) as see how clumpy those hot spots are. This approach is nice though if you have a fixed area you want to cover though.
Why Raleigh?
For a bit of personal news, I will be moving to the Raleigh area here shortly. I recently negotiated to be 100% remote at my job – so I will still be at HMS (or since we were recently purchased I might be employed by Gainwell I guess by the time I move). So looking forward to the new adventure back on the east coast but still in more temperate climates than PA or NY!
References
- Adepeju, M., Rosser, G., & Cheng, T. (2016). Novel evaluation metrics for sparse spatio-temporal point process hotspot predictions-a crime case study. International Journal of Geographical Information Science, 30(11), 2133-2154.
- Caplan, J. M., Neudecker, C. H., Kennedy, L. W., Barnum, J. D., & Drawve, G. (2020). Tracking Risk for Crime Throughout the Day: An Examination of Jersey City Robberies. Criminal Justice Review, Online First.
- Fox, B., Trolard, A., Simmons, M., Meyers, J. E., & Vogel, M. (2021). Assessing the Differential Impact of Vacancy on Criminal Violence in the City of St. Louis, MO. Criminal Justice Review, Online First.
- Harries, K. (2006). Extreme spatial variations in crime density in Baltimore County, MD. Geoforum, 37(3), 404-416.
- Hart, T. C. (2021). Investigating Crime Pattern Stability at Micro-Temporal Intervals: Implications for Crime Analysis and Hotspot Policing Strategies. Criminal Justice Review, Online First.
- Mohler, G., Raje, R., Carter, J., Valasik, M., & Brantingham, J. (2018). A penalized likelihood method for balancing accuracy and fairness in predictive policing. In 2018 IEEE international conference on systems, man, and cybernetics (SMC) (pp. 2454-2459). IEEE.
- Wheeler, A. P. (2020). Allocating police resources while limiting racial inequality. Justice Quarterly, 37(5), 842-868.
- Wheeler, A. P., & Reuter, S. (2020). Redrawing hot spots of crime in Dallas, Texas. Police Quarterly, Online First.
- Wheeler, A. P., & Steenbeek, W. (2020). Mapping the risk terrain for crime using machine learning. Journal of Quantitative Criminology, Online First.
- Yoo, Y., & Wheeler, A. P. (2019). Using risk terrain modeling to predict homeless related crime in Los Angeles, California. Applied Geography, 109, 102039.


1 Comment