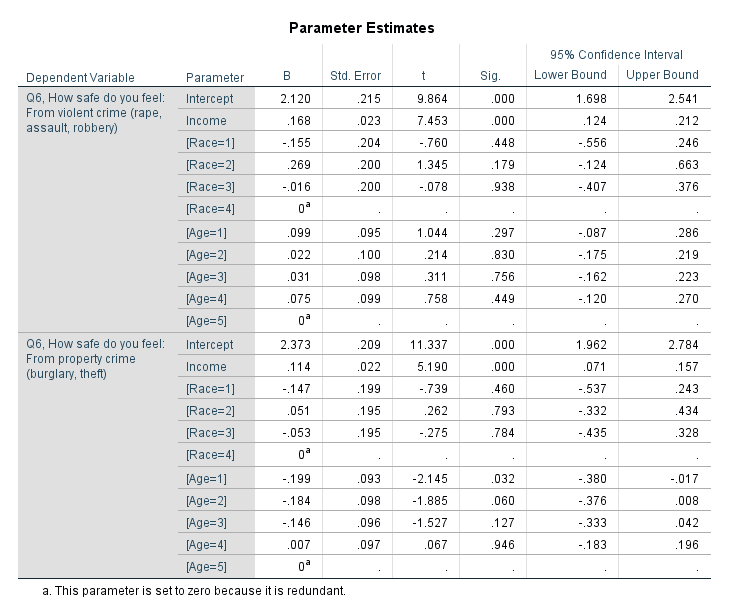
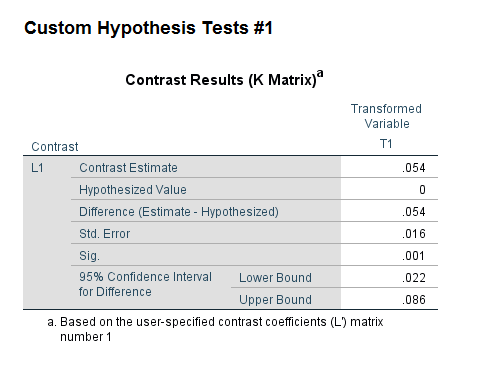
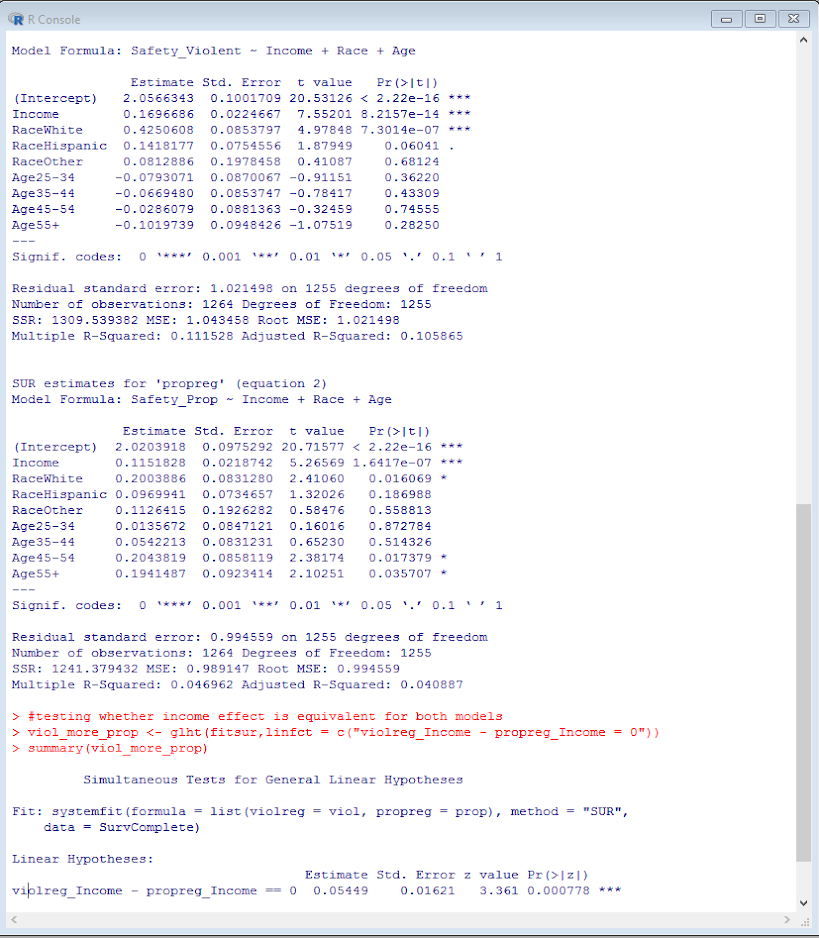
Something that came up for many of my students this last semester in my Seminar in Research class is that many were interested in multiple outcomes. The most common one is examining different types of delinquency for juveniles (often via surveys), but it comes up in quite a few other designs as well (e.g. different crime outcomes for spatial research, different measures of perceptions towards police, different measures of fear of crime, etc.).
Most of the time students default to estimating separate equations for each of these outcomes, but in most circumstances I was telling the students they should pool these outcomes into one model. I think that is the better default for the majority of situations. So say we have a situation with two outcomes, violent crimes and property crimes, and we have one independent variable we are interested in, say whether an individual was subjected to a particular treatment. We might then estimate two separate equations:
E[# Violent Crimes] = B0v + B1v*(Treatment)
E[# Property Crimes] = B0p + B1p*(Treatment)By saying that I think by default we should think about pooling is basically saying that B1v is going to be close to equal to B1p in the two equations. Pooling the models together both lets us test that assertion, as well as get a better estimate of the overall treatment effect. So to pool the models we would stack the outcomes together, and then estimate something like:
E[# Crimes (by type)] = B0 + B1*(Treatment) + B2*(Outcome = Violent) + B3(Treatment*Outcome = Violent)Here the B3 coefficient tests whether the treatment effect is different for the violent crime outcome as opposed to the property crime, and the dummy variable B2 effect controls for any differences in the levels of the two overall (that is, you would expect violent incidents to be less common than property crime incidents).
Because you will have multiple measures per individual, you can correct for that (by clustering the standard errors). But in the case you have many outcomes you might also want to consider a multi-level model, and actually estimate random effects for individuals and outcomes. So say instead of just violent and property crimes, but had a survey listing for 20 different types of delinquency. In that case you might want to do a model that looks like:
Prob(Delinquency_ij) = f[B0 + B1*(Treatment_j) + d_j + g_i]Where one is estimating a multi-level logistic regression equation for delinquency type i within individual j, and the g_i and d_j are the random effects for delinquency types and individuals respectively. In the case you do not have many outcomes (say only 10), the random effect distribution might be hard to estimate. In that case I would just use fixed effects for the outcome dummy variables. But I can imagine the random effects for persons are of interest in many different study designs. And this way you get one model — instead of having to interpret 20+ models.
Also you can still estimate differential treatment effects across the different items if you want to, such as by looking at the interaction of the outcome types and the treatment. But in most cases in criminology I have come across treatments are general. That is, we would expect them to decrease/increase all crime types, not just some specific violent or property crime types. So to default pooling the treatment effect estimate makes sense.
To go a bit farther — juvenile delinquency is not my bag, but offhand I don’t understand why those who examine surveys of delinquency items use that multi-level model more often. Often times people aggregate the measures altogether into one overall scale, such as saying someone checked yes to 2 out of 10 violent crime outcomes, and checked yes to 5 out of 10 property crime outcomes. Analyzing those aggregated outcomes is another type of pooling, but one I don’t think is appropriate, mainly because it ignores the overall prevalence for the different items. For example, you might have an item such as "steal a car", and another that is "steal a candy bar". The latter is much more serious and subsequently less likely to occur. Going with my prior examples, pooling items together like this would force the random effects for the individual delinquency types, g_i, to all equal zero. Just looking at the data one can obviously tell that is not a good assumption.
Here I will provide an example via simulation to demonstrate this in Stata. First I generate an example dataset that has 1,000 individuals and 20 yes/no outcomes. They way the data are simulated is that each individual has a specific amount of self_control that decreases the probability of an outcome (with a coefficient of -0.5), they are nested within a particular group (imagine a different school) that affect whether the outcome occurs or not. In addition to this, each individual has a random intercept (drawn from a normal distribution), and each question has a fixed different prevalence.
*Stata simulation
clear
set more off
set seed 10
set obs 1000
generate caseid = _n
generate group = ceil(caseid/100)
generate self_control = rnormal(0,1)
generate rand_int = rnormal(0,1)
*generating 20 outcomes that just have a varying intercept for each
forval i = 1/20 {
generate logit_`i' = -0.4 -0.5*self_control -0.1*group + 0.1*(`i'-10) + rand_int
generate prob_`i' = 1/(1 + exp(-1*logit_`i'))
generate outcome_`i' = rbinomial(1,prob_`i')
}
drop logit_* prob_* rand_int
summarize prob_*And here is that final output:
. summarize prob_*
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
prob_1 | 1,000 .1744795 .1516094 .0031003 .9194385
prob_2 | 1,000 .1868849 .157952 .0034252 .9265418
prob_3 | 1,000 .199886 .1642414 .0037841 .9330643
prob_4 | 1,000 .21348 .1704442 .0041804 .9390459
prob_5 | 1,000 .2276601 .1765258 .004618 .9445246
-------------+---------------------------------------------------------
prob_6 | 1,000 .242416 .1824513 .0051012 .9495374
prob_7 | 1,000 .2577337 .1881855 .0056347 .9541193
prob_8 | 1,000 .2735951 .1936933 .0062236 .9583033
prob_9 | 1,000 .289978 .1989401 .0068736 .962121
prob_10 | 1,000 .3068564 .2038919 .007591 .9656016
-------------+---------------------------------------------------------
prob_11 | 1,000 .3242004 .2085164 .0083827 .9687729
prob_12 | 1,000 .3419763 .2127823 .0092562 .9716603
prob_13 | 1,000 .3601469 .2166605 .0102197 .9742879
prob_14 | 1,000 .3786715 .2201237 .0112824 .9766776
prob_15 | 1,000 .3975066 .2231474 .0124542 .9788501
-------------+---------------------------------------------------------
prob_16 | 1,000 .4166057 .2257093 .013746 .9808242
prob_17 | 1,000 .4359203 .2277906 .0151697 .9826173
prob_18 | 1,000 .4554 .2293751 .0167384 .9842454
prob_19 | 1,000 .474993 .2304504 .0184663 .9857233
prob_20 | 1,000 .4946465 .2310073 .0203689 .9870643You can see from this list that each prob* variable then has a different overall prevalence, from around 17% for prob_1, climbing to around 50% for prob_20.
Now if you wanted to pool the items into one overall delinquency scale, you might estimate a binomial regression model (note this is not a negative binomial model!) like below (see Britt et al., 2017 for discussion).
*first I will show the binomial model in Britt
egen delin_total = rowtotal(outcome_*)
*Model 1
glm delin_total self_control i.group, family(binomial 20) link(logit)Which shows for the results (note that the effect of self-control is too small, it should be around -0.5):
. glm delin_total self_control i.group, family(binomial 20) link(logit)
Iteration 0: log likelihood = -3536.491
Iteration 1: log likelihood = -3502.3107
Iteration 2: log likelihood = -3502.2502
Iteration 3: log likelihood = -3502.2502
Generalized linear models No. of obs = 1,000
Optimization : ML Residual df = 989
Scale parameter = 1
Deviance = 4072.410767 (1/df) Deviance = 4.117706
Pearson = 3825.491931 (1/df) Pearson = 3.86804
Variance function: V(u) = u*(1-u/20) [Binomial]
Link function : g(u) = ln(u/(20-u)) [Logit]
AIC = 7.0265
Log likelihood = -3502.250161 BIC = -2759.359
------------------------------------------------------------------------------
| OIM
delin_total | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
self_control | -.3683605 .0156401 -23.55 0.000 -.3990146 -.3377065
|
group |
2 | -.059046 .0666497 -0.89 0.376 -.1896769 .071585
3 | -.0475712 .0665572 -0.71 0.475 -.178021 .0828785
4 | .0522331 .0661806 0.79 0.430 -.0774786 .1819448
5 | -.1266052 .0672107 -1.88 0.060 -.2583357 .0051254
6 | -.391597 .0695105 -5.63 0.000 -.527835 -.2553589
7 | -.2997012 .0677883 -4.42 0.000 -.4325639 -.1668386
8 | -.267207 .0680807 -3.92 0.000 -.4006427 -.1337713
9 | -.4340516 .0698711 -6.21 0.000 -.5709964 -.2971069
10 | -.5695204 .070026 -8.13 0.000 -.7067689 -.432272
|
_cons | -.5584345 .0470275 -11.87 0.000 -.6506067 -.4662623
------------------------------------------------------------------------------One of the things I wish the Britt paper mentioned was that the above binomial model is equivalent to the a logistic regression model on the individual outcomes — but one that forces the predictions for each item to be the same across a person. So if you reshape the data from wide to long you can estimate that same binomial model as a logistic regression on the 0/1 outcomes.
*reshape wide to long
reshape long outcome_, i(caseid) j(question)
*see each person now has 20 questions each
*tab caseid
*regression model with the individual level data, should be equivalent to the aggregate binomial model
*Model 2
glm outcome_ self_control i.group, family(binomial) link(logit)And here are the results:
. glm outcome_ self_control i.group, family(binomial) link(logit)
Iteration 0: log likelihood = -12204.638
Iteration 1: log likelihood = -12188.762
Iteration 2: log likelihood = -12188.755
Iteration 3: log likelihood = -12188.755
Generalized linear models No. of obs = 20,000
Optimization : ML Residual df = 19,989
Scale parameter = 1
Deviance = 24377.50934 (1/df) Deviance = 1.219546
Pearson = 19949.19243 (1/df) Pearson = .9980085
Variance function: V(u) = u*(1-u) [Bernoulli]
Link function : g(u) = ln(u/(1-u)) [Logit]
AIC = 1.219975
Log likelihood = -12188.75467 BIC = -173583.3
------------------------------------------------------------------------------
| OIM
outcome_ | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
self_control | -.3683605 .0156401 -23.55 0.000 -.3990146 -.3377065
|
group |
2 | -.059046 .0666497 -0.89 0.376 -.1896769 .071585
3 | -.0475712 .0665572 -0.71 0.475 -.178021 .0828785
4 | .0522331 .0661806 0.79 0.430 -.0774786 .1819448
5 | -.1266052 .0672107 -1.88 0.060 -.2583357 .0051254
6 | -.391597 .0695105 -5.63 0.000 -.527835 -.2553589
7 | -.2997012 .0677883 -4.42 0.000 -.4325639 -.1668386
8 | -.267207 .0680807 -3.92 0.000 -.4006427 -.1337713
9 | -.4340516 .0698711 -6.21 0.000 -.5709964 -.2971069
10 | -.5695204 .070026 -8.13 0.000 -.7067689 -.432272
|
_cons | -.5584345 .0470275 -11.87 0.000 -.6506067 -.4662623
------------------------------------------------------------------------------So you can see that Model 1 and Model 2 are exactly the same (in terms of estimates for the regression coefficients).
Model 2 though should show the limitations of using the binomial model — it predicts the same probability for each delinquency item, even though prob_1 is less likely to occur than prob_20. So for example, if we generate the predictions of this model, we can see that each question has the same predicted value.
predict prob_mod2, mu
sort question
by question: summarize outcome_ prob_mod2And here are the results for the first four questions:
. by question: summarize outcome_ prob_mod2
-------------------------------------------------------------------------------------------------------------------------------------------------------
-> question = 1
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
outcome_ | 1,000 .183 .38686 0 1
prob_mod2 | 1,000 .32305 .0924081 .1049203 .6537998
-------------------------------------------------------------------------------------------------------------------------------------------------------
-> question = 2
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
outcome_ | 1,000 .205 .4039036 0 1
prob_mod2 | 1,000 .32305 .0924081 .1049203 .6537998
-------------------------------------------------------------------------------------------------------------------------------------------------------
-> question = 3
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
outcome_ | 1,000 .208 .4060799 0 1
prob_mod2 | 1,000 .32305 .0924081 .1049203 .6537998
-------------------------------------------------------------------------------------------------------------------------------------------------------
-> question = 4
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
outcome_ | 1,000 .202 .4016931 0 1
prob_mod2 | 1,000 .32305 .0924081 .1049203 .6537998By construction, the binomial model on the aggregated totals is a bad fit to the data. It predicts that each question should have a probability of around 32% of occurring. Although you can’t fit the zero-inflated model discussed by Britt via the individual level logit approach (that I am aware of), that approach has the same limitation as the generic binomial model approach. Modeling the individual items just makes more sense when you have the individual items. It is hard to think of examples where such a restriction would be reasonable for delinquency items.
So here a simple update is to include a dummy variable for each item. Here I also cluster according to whether the item is nested within an individual caseid.
*Model 3
glm outcome_ self_control i.group i.question, family(binomial) link(logit) cluster(caseid)And here are the results:
. glm outcome_ self_control i.group i.question, family(binomial) link(logit) cluster(caseid)
Iteration 0: log pseudolikelihood = -11748.056
Iteration 1: log pseudolikelihood = -11740.418
Iteration 2: log pseudolikelihood = -11740.417
Iteration 3: log pseudolikelihood = -11740.417
Generalized linear models No. of obs = 20,000
Optimization : ML Residual df = 19,970
Scale parameter = 1
Deviance = 23480.83406 (1/df) Deviance = 1.175805
Pearson = 19949.15609 (1/df) Pearson = .9989562
Variance function: V(u) = u*(1-u) [Bernoulli]
Link function : g(u) = ln(u/(1-u)) [Logit]
AIC = 1.177042
Log pseudolikelihood = -11740.41703 BIC = -174291.8
(Std. Err. adjusted for 1,000 clusters in caseid)
------------------------------------------------------------------------------
| Robust
outcome_ | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
self_control | -.3858319 .0334536 -11.53 0.000 -.4513996 -.3202641
|
group |
2 | -.0620222 .1350231 -0.46 0.646 -.3266626 .2026182
3 | -.049852 .1340801 -0.37 0.710 -.3126442 .2129403
4 | .0549271 .1383412 0.40 0.691 -.2162167 .3260709
5 | -.1329942 .1374758 -0.97 0.333 -.4024419 .1364535
6 | -.4103578 .1401212 -2.93 0.003 -.6849904 -.1357253
7 | -.3145033 .1452201 -2.17 0.030 -.5991296 -.0298771
8 | -.2803599 .1367913 -2.05 0.040 -.5484659 -.012254
9 | -.4543686 .1431314 -3.17 0.002 -.7349011 -.1738362
10 | -.5962359 .1457941 -4.09 0.000 -.8819872 -.3104847
|
question |
2 | .1453902 .1074383 1.35 0.176 -.0651851 .3559654
3 | .1643203 .1094113 1.50 0.133 -.050122 .3787625
4 | .1262597 .1077915 1.17 0.241 -.0850078 .3375272
5 | .1830563 .105033 1.74 0.081 -.0228047 .3889173
6 | .3609468 .1051123 3.43 0.001 .1549304 .5669633
7 | .524749 .100128 5.24 0.000 .3285017 .7209963
8 | .5768412 .1000354 5.77 0.000 .3807754 .772907
9 | .7318797 .1021592 7.16 0.000 .5316513 .9321081
10 | .571682 .1028169 5.56 0.000 .3701646 .7731994
11 | .874362 .0998021 8.76 0.000 .6787535 1.06997
12 | .8928982 .0998285 8.94 0.000 .6972379 1.088559
13 | .8882734 .1023888 8.68 0.000 .687595 1.088952
14 | .9887095 .0989047 10.00 0.000 .7948599 1.182559
15 | 1.165517 .0977542 11.92 0.000 .9739222 1.357111
16 | 1.230355 .0981687 12.53 0.000 1.037948 1.422762
17 | 1.260403 .0977022 12.90 0.000 1.06891 1.451896
18 | 1.286065 .098823 13.01 0.000 1.092376 1.479755
19 | 1.388013 .0987902 14.05 0.000 1.194388 1.581638
20 | 1.623689 .0999775 16.24 0.000 1.427737 1.819642
|
_cons | -1.336376 .1231097 -10.86 0.000 -1.577666 -1.095085
------------------------------------------------------------------------------You can now see that the predicted values for each individual item are much more reasonable. In fact they are a near perfect fit.
predict prob_mod3, mu
by question: summarize outcome_ prob_mod2 prob_mod3And the results:
. by question: summarize outcome_ prob_mod2 prob_mod3
-------------------------------------------------------------------------------------------------------------------------------------------------------
-> question = 1
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
outcome_ | 1,000 .183 .38686 0 1
prob_mod2 | 1,000 .32305 .0924081 .1049203 .6537998
prob_mod3 | 1,000 .183 .0672242 .0475809 .4785903
-------------------------------------------------------------------------------------------------------------------------------------------------------
-> question = 2
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
outcome_ | 1,000 .205 .4039036 0 1
prob_mod2 | 1,000 .32305 .0924081 .1049203 .6537998
prob_mod3 | 1,000 .205 .0729937 .0546202 .5149203
-------------------------------------------------------------------------------------------------------------------------------------------------------
-> question = 3
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
outcome_ | 1,000 .208 .4060799 0 1
prob_mod2 | 1,000 .32305 .0924081 .1049203 .6537998
prob_mod3 | 1,000 .208 .0737455 .055606 .5196471
-------------------------------------------------------------------------------------------------------------------------------------------------------
-> question = 4
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
outcome_ | 1,000 .202 .4016931 0 1
prob_mod2 | 1,000 .32305 .0924081 .1049203 .6537998
prob_mod3 | 1,000 .202 .0722336 .0536408 .5101407If you want, you can also test whether any "treatment" effect (or here the level of a persons self control), has differential effects across the different delinquency items.
*Model 4
glm outcome_ self_control i.group i.question (c.self_control#i.question), family(binomial) link(logit) cluster(caseid)
*can do a test of all the interactions equal to zero at once
testparm c.self_control#i.questionI’ve omitted this output, but here of course the effect of self control is simulated to be the same across the different items, so one would fail to reject the null that any of the interaction terms are non-zero.
Given the way I simulated the data, the actual correct model is a random effects one. You should notice in each of the prior models the effect of self control is too small. One way to estimate that model in Stata is to below:
*Model 5
melogit outcome_ self_control i.group i.question || caseid:And here are the results:
. melogit outcome_ self_control i.group i.question || caseid:
Fitting fixed-effects model:
Iteration 0: log likelihood = -11748.056
Iteration 1: log likelihood = -11740.418
Iteration 2: log likelihood = -11740.417
Iteration 3: log likelihood = -11740.417
Refining starting values:
Grid node 0: log likelihood = -10870.54
Fitting full model:
Iteration 0: log likelihood = -10870.54
Iteration 1: log likelihood = -10846.176
Iteration 2: log likelihood = -10845.969
Iteration 3: log likelihood = -10845.969
Mixed-effects logistic regression Number of obs = 20,000
Group variable: caseid Number of groups = 1,000
Obs per group:
min = 20
avg = 20.0
max = 20
Integration method: mvaghermite Integration pts. = 7
Wald chi2(29) = 1155.07
Log likelihood = -10845.969 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
outcome_ | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
self_control | -.4744173 .0372779 -12.73 0.000 -.5474807 -.401354
|
group |
2 | -.0648018 .1642767 -0.39 0.693 -.3867783 .2571746
3 | -.0740465 .1647471 -0.45 0.653 -.3969449 .2488519
4 | .036207 .1646275 0.22 0.826 -.286457 .358871
5 | -.1305605 .1645812 -0.79 0.428 -.4531337 .1920126
6 | -.5072909 .1671902 -3.03 0.002 -.8349776 -.1796042
7 | -.3732567 .165486 -2.26 0.024 -.6976032 -.0489102
8 | -.3495889 .1657804 -2.11 0.035 -.6745126 -.0246653
9 | -.5593725 .1675276 -3.34 0.001 -.8877205 -.2310245
10 | -.7329717 .1673639 -4.38 0.000 -1.060999 -.4049445
|
question |
2 | .1690546 .1240697 1.36 0.173 -.0741177 .4122268
3 | .191157 .1237894 1.54 0.123 -.0514657 .4337797
4 | .1467393 .1243586 1.18 0.238 -.0969991 .3904776
5 | .2130531 .1235171 1.72 0.085 -.029036 .4551422
6 | .4219282 .1211838 3.48 0.000 .1844123 .6594441
7 | .6157484 .1194133 5.16 0.000 .3817027 .8497941
8 | .6776651 .1189213 5.70 0.000 .4445837 .9107465
9 | .8626735 .1176486 7.33 0.000 .6320865 1.093261
10 | .6715272 .1189685 5.64 0.000 .4383532 .9047012
11 | 1.033571 .1167196 8.86 0.000 .8048051 1.262338
12 | 1.05586 .116615 9.05 0.000 .8272985 1.284421
13 | 1.050297 .1166407 9.00 0.000 .8216858 1.278909
14 | 1.171248 .1161319 10.09 0.000 .9436331 1.398862
15 | 1.384883 .1154872 11.99 0.000 1.158532 1.611234
16 | 1.463414 .1153286 12.69 0.000 1.237375 1.689454
17 | 1.499836 .1152689 13.01 0.000 1.273913 1.725759
18 | 1.530954 .1152248 13.29 0.000 1.305117 1.75679
19 | 1.654674 .1151121 14.37 0.000 1.429058 1.880289
20 | 1.941035 .1152276 16.85 0.000 1.715193 2.166877
|
_cons | -1.591796 .1459216 -10.91 0.000 -1.877797 -1.305795
-------------+----------------------------------------------------------------
caseid |
var(_cons)| 1.052621 .0676116 .9281064 1.19384
------------------------------------------------------------------------------
LR test vs. logistic model: chibar2(01) = 1788.90 Prob >= chibar2 = 0.0000In that model it is the closest to estimating the correct effect of self control (-0.5). It is still small (at -0.47), but the estimate is within one standard error of the true value. (Another way to estimate this model is to use xtlogit, but with melogit you can actually extract the random effects. That will have to wait until another blog post though.)
Another way to think about this model is related to item-response theory, where individuals can have a latent estimate of how smart they are, and questions can have a latent easiness/hardness. In Stata you might fit that by the code below, but a warning it takes awhile to converge. (Not sure why, the fixed effects for questions are symmetric, so assuming a random effect distribution should not be too far off. If you have any thoughts as to why let me know!)
*Model 6
melogit outcome_ self_control i.group || caseid: || question:For an academic reference to this approach see Osgood et al.,(2002). Long story short, model the individual items, but pool them together in one model!