Several recent studies (Johnson et al., 2019; Jetelina et al., 2020) use a similar study design to assess racial bias in officer involved shootings (OIS). In short, critiques of this work by Jon Mummolo (JM) are correct – they make a fundamental error in the analysis that renders the results mostly meaningless (Knox and Mummalo, 2020). JM critiques the work as switching conditional probabilities, this recent OIS work estimates the probability of the race of someone shot by police conditional on other characteristics, e.g. tests the hypothesis P(White | Other Stuff, Being Shot) = P(Minority | Other Stuff, Being Shot). Whereas we want Being Shot on the left hand side, e.g. P(Being Shot | Race), and switching these probabilities results in mostly a meaningless estimate in terms of inferring police behavior. You ultimately need to look at some cases in which folks were not shot to have a meaningful research design.
I’ve been having similar conversations with folks since publishing my work on officer involved shootings (Wheeler et al., 2017). Most folks don’t understand the critique, and unfortunately most folks also don’t take critiques very well. So this post is probably a waste of time, but here it is anyway.
The Road
I’m likely to get some of the timing wrong in how I came to be interested in this area – but here is what I remember. David Klinger and Richard Rosenfeld published a piece in Criminology & Public Policy (CPP) examining the count of OIS’s in neighborhoods in St. Louis, conditional on demographic and violent crime counts in those neighborhoods (Klinger et al., 2016). So in quantoid speak they estimated the expected number of OIS in neighborhoods, E[OIS_n | Demographic_n, Crime_n].
I thought this work was mostly meaningless, mainly because it really only makes sense to look at rates of behavior. You could stick a count of anything police do on the left hand side of this regression and the violent crime coefficient will be the largest positive effect. So you could say estimate the counts of officers helping old ladies cross the street, and you would make the same inferences as you would about OIS. It is basically just saying where officers spend more of their time at (in violent crime areas), and subsequently have more interactions with individuals. It doesn’t say anything fundamentally about police behavior in regards to racial bias.
So sometime in 2016 me and Scott Phillips came up with the study design using when officers draw their firearm as the denominator. (Before I moved to Dallas I knew about their open data.) It was the observational analogue to the shoot/don’t shoot lab experiments Lois James did (James et al., 2014). Also sometime during the time period Roland Fryer came out with his pre-print, in which he used Taser uses as the counter-factual don’t shoot cases (Fryer, 2019). I thought drawing the firearm made more sense as a counterfactual, but both are subject to the same potential selection effect. (Police may be quicker to the draw their firearms with minorities, which I readily admit in my paper.)
Also in that span Justin Nix came out with the birds-eye view CPP paper using the national level crowd sourced data (Nix et al., 2017) to estimate racial bias. They make what to me is a similar conditional probability mistake as the papers that motivated this post. Using the crowdsourced national level data, they estimate the probability of being unarmed, conditional on race (in the sample of just folks who were killed by the police). So they test whether P(Unarmed | White, Shot) = P(Unarmed | Minority, Shot).
Since like I said folks don’t really understand the conditional probability argument, basically at this point I just say folks get causality backwards. The police shooting at someone does not make them armed or unarmed, the same way police shooting at someone does not change their race. You cannot estimate a regression of X ~ beta*Y, then interpret beta as how much X causes Y. The stuff on the right hand side of the conditional probability statement works mostly the same way, we want to say stuff on the right hand side of the condition causes some change in the outcome.
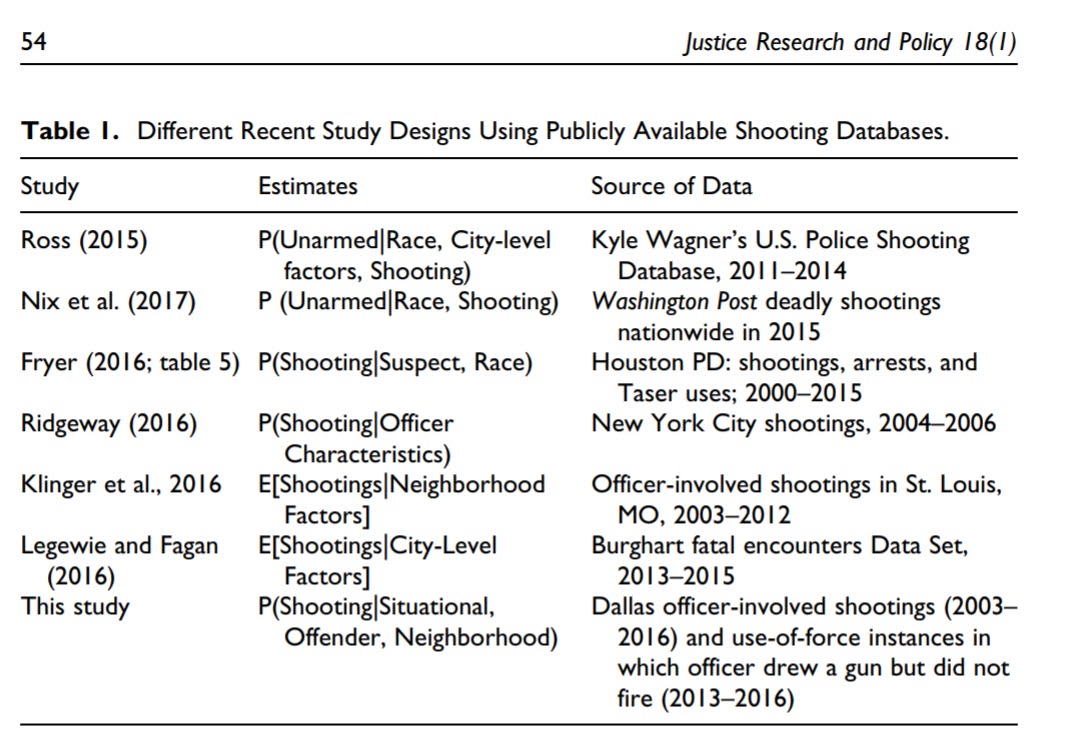
I have this table I made in Wheeler et al. (2017) to illustrate various research designs – you can see the Ross (2015) made the same estimate of P(Unarmed | Race, Shot) as Justin did.
At this point you typically get a series of different retorts to the “you estimated the wrong conditional probability complaint”. The ones I’ve repeatedly seen are:
- No data is perfect. We should work with what we have.
- We ask a different research question.
- Our analysis are just descriptive, not causal.
- Our findings are consistent with a bunch of other work.
For (3) I would be OK if the results are described correctly, pretty much all of these articles are clearly interested in making inferences about police behavior though (which you cannot do with just looking at these negative encounters). It isn’t just a slip of mistaking conditional probabilities (like a common p-value mishap that doesn’t really impact the overall conclusions), the articles are directly motivated to make inferences about police behavior they cannot with this study design.
For (2) it is useful to consider how might the descriptive conditional probabilities be actually interpreted in a reasonable manner. So if we estimate P(Offender Race | Shot), you can think of a game where if you see a news headline about an OIS, and you want to guess the race of the person shot by police, what would be your best guess. Ditto for P(Unarmed | Shot), what is the probability of someone being unarmed conditional on them being shot. This game is clearly a superficial type of thing to estimate, those probabilities don’t say anything though about behavior in terms of things police officers can control, they are all just a function of how often police get in interactions with those different races (or armed status) of individuals.
Consider a different hypothetical, the probability a human is shot by police versus an animal. P(Human | Shot) is waay larger than P(Animal | Shot), are police biased against humans? No, the police just don’t deal with animals they need to shoot on a regular basis.
For (1) I will follow up below with some examples of how I think using this OIS data could actually be effective for shaping police behavior in practice, but suffice to say just collecting OIS you can’t really say anything about racial bias in terms of officer decision making.
I will say that a bunch of the individuals I am critiquing here I consider friends. Steve Bishopp was one of the co-authors on my OIS work with Dallas data. If I go to a conference Justin is one of the people I would prefer to sit down and have a drink with. I’ve been schmoozing up folks with good R programming skills to come to Dallas to work for Jenn Reingle-Gonzalez. They have all done other work I think is good. See Tregel et al. (2019) or Jetelina et al. (2017) or Cesario et al. (2019) for other examples I think are more legitimate research articles amongst the same people who I am critiquing here.
So in response to (4) I think you all made the wrong mistake – the conditional probability mistake is an easy one to make. So sorry to my friends whom I think are wrong about this. That being said, most of the vitriol in public forums, often accusing people of ad-hominem attacks on their motivations, is pretty much always out of line. I think basically everyone on Twitter is being a jerk to be frank. I’ve seen it all around on both sides in the most recent Twitter back and forth (both folks calling Jenn racist and JM biased against the police). None of them are racist or biased for/against the police. I suppose to expect any different though is setting myself up for dissapointment. I was called racist by academic reviewers for Wheeler et al. (2017) (it took 4 rejects for my OIS paper before it was published). I’ve seen Justin get critiques on Twitter for being white in the past when doing work in this area.
I think CJ folks questioning JM’s motivation miss the point of his critique though. He isn’t saying police are biased and these papers are wrong, he is just saying these research papers are wrong because they can’t tell whether police are biased one way or another.
Who gives a shit
So while I think better research could be conducted in this area – JM has his work on bounding estimates (Knox et al., 2019), and I imagine someone can come up with a reasonable instrumental variable strategy to address the selection bias in the same vein as my shoot/don’t shoot (say officer instruments, or exogenous incidents that make officers more on edge and more likely to draw their firearm). But I think the question of whether “the police” are racially biased is a facile question. Globally labelling all police (or a single department) as racist is mostly a waste of time. Good for academic papers and to get people riled up in Twitter, not so much for anything else.
The police are simply a cross section of the general public. So in terms of whether some officers are racist this is true (as it is for the general public). Or maybe even we are all a little racist (ala the implicit bias hypothesis). We can only observe behavior, we cannot peer into the hearts and minds of men. But suffice to say racism is still a part of our society in some capacity I believe is a pretty tame statement.
Subsequently if you gather enough data you will be able to get some estimate of the police being racist (the null is for sure wrong). But if people can’t reasonably understand conditional probabilities, imagine trying to have a conversation about what is a reasonable amount of racial bias for monitoring purposes (inferiority bounds). Or that this racial bias estimate is not for all police, but some mixture of police officers and actions. Hard pass on either of those from me.
Subsequently this work has no bearing on actual police practice (including my own). They are of very limited utility – at best a stick or shield in civil litigation. They don’t help police departments change behavior in response to discovering (or not discovering) racial bias. And OIS are basically so rare they are worthless for all but the biggest police departments in terms of a useful monitoring metric (it won’t be sensitive enough to say whether a police department as a whole is doing good or doing bad).
So what do I think is potentially useful way to use this data? I’ve used the term “monitoring metric” a few times – what I mean by that is using the information to actually inform some response. Internally for police departments, shootings should be part of an early intervention system used to monitor individual officers for problematic behavior. From a state or federal government perspective, they could actively monitor overall levels of force used to identify outlier agencies (see this blog post example of mine). For the latter think proactively identifying problematic departments, instead of the typical current approach of wait for some major incident and then the Department of Justice assigns a federal monitor.
In either of those strategies just looking at shootings won’t be enough, they would need to use all levels of use of force to effectively identify either bad individual cops or problematic departments as a whole. Hence why I suggested adding all levels of force to say NIBRS, rather than having a stand alone national level OIS database. And individual agencies already have all the data they need to do an effective early intervention system.
I’m not totally oppossed to having a national level OIS database just based on normative arguments – e.g. you think it is a travesty we can’t say how many folks were killed by police in the prior year. It is not a totally hollow gesture, as making people record the information does provide a level of oversight, so may make a small difference. But that data won’t be able to say anything about the racial bias in individual police officer decision making.
References
Cesario, J., Johnson, D. J., & Terrill, W. (2019). Is there evidence of racial disparity in police use of deadly force? Analyses of officer-involved fatal shootings in 2015–2016. Social psychological and personality science, 10(5), 586-595.
Fryer Jr, R. G. (2019). An empirical analysis of racial differences in police use of force. Journal of Political Economy, 127(3), 1210-1261.
Klinger, D., Rosenfeld, R., Isom, D., & Deckard, M. (2016). Race, crime, and the micro-ecology of deadly force. Criminology & Public Policy, 15(1), 193-222.
Knox, D., Lowe, W., & Mummolo, J. (2019). The bias is built in: How administrative records mask racially biased policing. Available at SSRN.
Knox, D., & Mummolo, J. (2020). Making inferences about racial disparities in police violence. Proceedings of the National Academy of Sciences, 117(3), 1261-1262.
James, L., Klinger, D., & Vila, B. (2014). Racial and ethnic bias in decisions to shoot seen through a stronger lens: Experimental results from high-fidelity laboratory simulations. Journal of Experimental Criminology, 10(3), 323-340.
Jetelina, K. K., Bishopp, S. A., Wiegand, J. G., & Gonzalez, J. M. R. (2020). Race/ethnicity composition of police officers in officer-involved shootings. Policing: An International Journal.
Jetelina, K. K., Jennings, W. G., Bishopp, S. A., Piquero, A. R., & Reingle Gonzalez, J. M. (2017). Dissecting the complexities of the relationship between police officer–civilian race/ethnicity dyads and less-than-lethal use of force. American journal of public health, 107(7), 1164-1170.
Johnson, D. J., Tress, T., Burkel, N., Taylor, C., & Cesario, J. (2019). Officer characteristics and racial disparities in fatal officer-involved shootings. Proceedings of the National Academy of Sciences, 116(32), 15877-15882.
Nix, J., Campbell, B. A., Byers, E. H., & Alpert, G. P. (2017). A bird’s eye view of civilians killed by police in 2015: Further evidence of implicit bias. Criminology & Public Policy, 16(1), 309-340.
Ross, C. T. (2015). A multi-level Bayesian analysis of racial bias in police shootings at the county-level in the United States, 2011–2014. PloS one, 10(11).
Tregle, B., Nix, J., & Alpert, G. P. (2019). Disparity does not mean bias: Making sense of observed racial disparities in fatal officer-involved shootings with multiple benchmarks. Journal of crime and justice, 42(1), 18-31.
Wheeler, A. P., Phillips, S. W., Worrall, J. L., & Bishopp, S. A. (2017). What factors influence an officer’s decision to shoot? The promise and limitations of using public data. Justice Research and Policy, 18(1), 48-76.