
So I have previously written about two plots post binary prediction models – calibration plots and ROC curves. One addition to these I am going to show are kernel density estimate plots, broken down by the observed value vs predicted value. One thing in particular I wanted to make these for is to showcase the distribution of the predicted probabilities themselves, which can be read off of the calibration chart, but is not as easy.
I have written about this some before – transforming KDE estimates from logistic to probability scale in R. I will be showing some of these plots in python using the seaborn library. It will be easier instead of transforming the KDE to use edge weighting statistics to get unbiased estimates near the borders for the way the seaborn library is set up.
To follow along, you can download the data I will be using here. It is the predicted probabilities from the test set in the calibration plot blog post, predicting recidivism using several different models.
First to start, I load my python libraries and set my matplotlib theme (which is also inherited by seaborn charts).
Then I load in my data. To make it easier I am just working with the test set and several predicted probabilities from different models.
import pandas as pd
from scipy.stats import norm
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
#####################
# My theme
andy_theme = {'axes.grid': True,
'grid.linestyle': '--',
'legend.framealpha': 1,
'legend.facecolor': 'white',
'legend.shadow': True,
'legend.fontsize': 14,
'legend.title_fontsize': 16,
'xtick.labelsize': 14,
'ytick.labelsize': 14,
'axes.labelsize': 16,
'axes.titlesize': 20,
'figure.dpi': 100}
matplotlib.rcParams.update(andy_theme)
#####################And here I am reading in the data (just have the CSV file in my directory where I started python).
################################################################
# Reading in the data with predicted probabilites
# Test from https://andrewpwheeler.com/2021/05/12/roc-and-calibration-plots-for-binary-predictions-in-python/
# https://www.dropbox.com/s/h9de3xxy1vy6xlk/PredProbs_TestCompas.csv?dl=0
pp_data = pd.read_csv(r'PredProbs_TestCompas.csv',index_col=0)
print(pp_data.head())
print(pp_data.describe())
################################################################
So you can see this data has the observed outcome Recid30 – recidivism after 30 days (although again this is the test dataset). And then it also has the predicted probability for three different models (XGBoost, RandomForest, and Logit), and then demographic breakdowns for sex and race.
The plot I am interested in seeing is a KDE estimate for the probabilities, broken down by the observed 0/1 for recidivism. Here is the default graph using seaborn:
# Original KDE plot by 0/1
sns.kdeplot(data=pp_data, x="Logit", hue="Recid30",
common_norm=False, bw_method=0.15)
One problem you can see with this plot though is that the KDE estimates are smoothed beyond the data. You cannot have a predicted probability below 0 or above 1. Because we are using a gaussian kernel, we can just reweight observations that are close to the edge, and then clip the KDE estimate. So a predicted probability of 0 would get a weight of 1/0.5 – so it gets double the weight. Note to do this correctly, you need to set the bandwidth the same for the seaborn kdeplot as well as the weights calculation – here 0.15.
# Weighting and clipping
# Amount of density below 0 & above 1
below0 = norm.cdf(x=0,loc=pp_data['Logit'],scale=0.15)
above1 = 1- norm.cdf(x=1,loc=pp_data['Logit'],scale=0.15)
pp_data['edgeweight'] = 1/ (1 - below0 - above1)
sns.kdeplot(data=pp_data, x="Logit", hue="Recid30",
common_norm=False, bw_method=0.15,
clip=(0,1), weights='edgeweight')
This results in quite a dramatic difference, showing the model does a bit better than the original graph. The 0’s were well discriminated, so have many very low probabilities that were smoothed outside the legitimate range.
Another cool plot you can do that again shows calibration is to use seaborn’s fill option:
cum_plot = sns.kdeplot(data=pp_data, x="Logit", hue="Recid30",
common_norm=False, bw_method=0.15,
clip=(0,1), weights='edgeweight',
multiple="fill", legend=True)
cum_plot.legend_._set_loc(4) #via https://stackoverflow.com/a/64687202/604456
As expected this shows an approximate straight line in the graph, e.g. 0.2 on the X axis should be around 0.2 for the orange area in the chart.
Next seaborn has another good function here, violin plots. Unfortunately you cannot pass a weight function here. But another option is to simply resample your data a large number of times, using the weights you provided earlier.
n = 1000000 #larger n will result in more accurate KDE
resamp_pp = pp_data.sample(n=n,replace=True, weights='edgeweight',random_state=10)
viol_sex = sns.violinplot(x="Sex", y="XGB", hue="Recid30",
data=resamp_pp, split=True, cut=0,
bw=0.15, inner=None,
scale='count', scale_hue=False)
viol_sex.legend_.set_bbox_to_anchor((0.65, 0.95))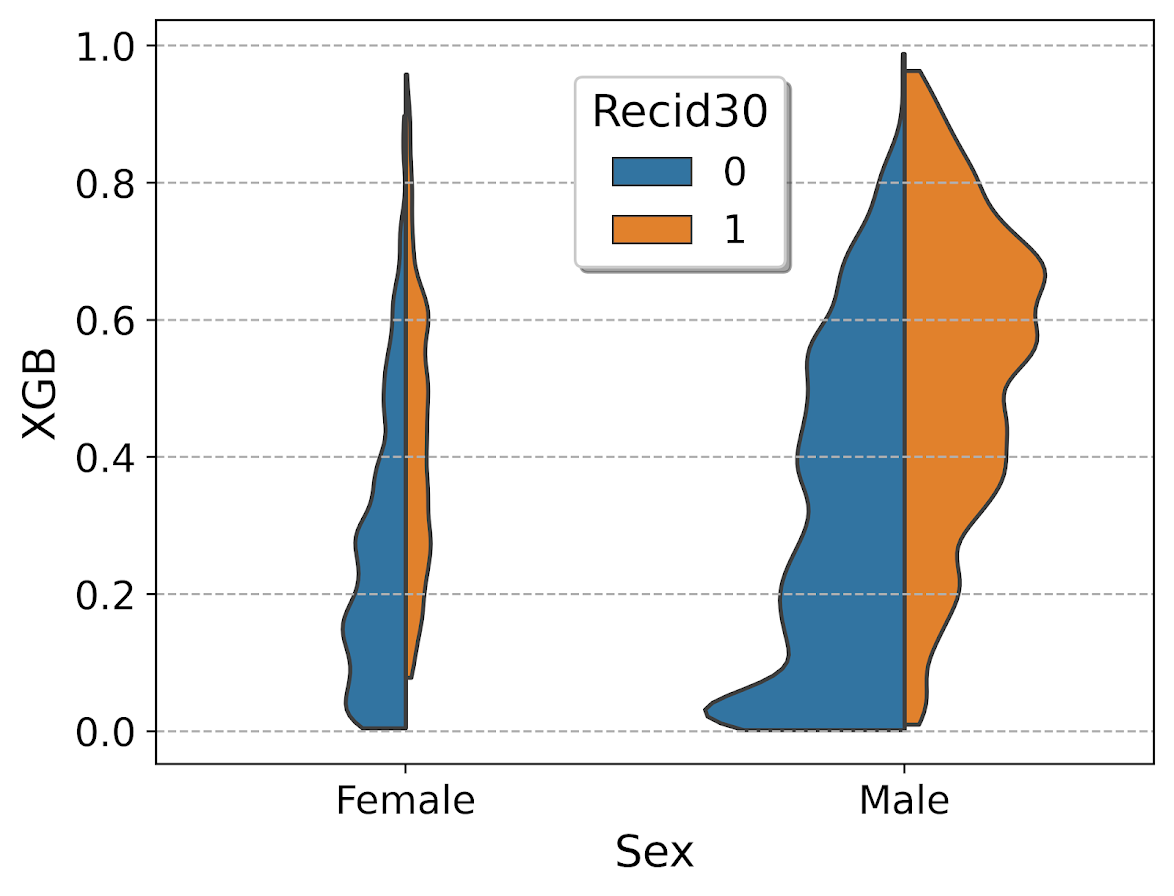
So here you can see we have more males in the sample, and they have a larger high risk blob that was correctly identified. Females have a risk profile more spread out, although there is a small clump of basically 0 risk that the model identifies.
You can also generate the graph so the areas for the violin KDE’s are normalized, so in both the original and resampled data we have fewer females, and more black individuals.
# Values for Sex for orig/resampled
print(pp_data['Sex'].value_counts(normalize=True))
print(resamp_pp['Sex'].value_counts(normalize=True))
# Values for Race orig/resampled
print(pp_data['Race'].value_counts(normalize=True))
print(resamp_pp['Race'].value_counts(normalize=True))
But if we set scale='area' in the chart the violins are the same size:
viol_race = sns.violinplot(x="Race", y="XGB", hue="Recid30",
data=resamp_pp, split=True, cut=0,
bw=0.15, inner=None,
scale='area', scale_hue=True)
viol_race.legend_.set_bbox_to_anchor((0.81, 0.95))
I will have to see if I can make some time to contribute to seaborn to make it so you can pass in weights to the violinplot function.










