
A problem I have come across in a few different contexts is the idea of ranking rates. For example, say a police department was interested in increasing contraband recovery and are considering two different streets to conduct additional traffic enforcement on — A and B. Say street A has a current hit rate of 50/1000 for a rate of 5%, and street B has a recovery rate of 1/10 for 10%. If you just ranked by percentages, you would choose street B. But given the small sample size, targeting street B is not a great bet to actually have a 10% hit rate going forward, so it may be better to choose street A.
The idea behind this observation is called shrinkage. Your best guess for the hit rate in either location A or location B in the future is not the observed percentage, but somewhere in between the observed percentage and the overall hit rate. Say the overall hit rate for contraband recovery is only 1%, then you wouldn’t expect street B to have a 10% hit rate going forward, but maybe something closer to 2% given the very small sample size. For street A you would expect shrinkage as well, but given it is a much larger sample size you would expect the shrinkage to be much less, say a 4% hit rate going forward. In what follows I will show how to calculate that shrinking using a technique called empirical Bayesian estimation.
I wanted to apply this problem to a recent ranking of cities based on officer involved shooting rates via federalcharges.com (hat tip to Justin Nix for tweeting that article). The general idea is that you don’t want to highlight cities who have high rates simply by chance due to smaller population baselines. Howard Wainer talks about this problem of ranking resulted in the false idea that smaller schools were better based on small samples of test results. Due to the high variance small schools will be both at the top and the bottom of the distributions, even if all of the schools have the same overall mean rate. Any reasonable ranking needs to take that variance into account to avoid the same mistake.
The same idea can be applied to homicide or other crime rates. Here I provide some simple code (and a spreadsheet) so other analysts can easily replicate this sorting idea for their own problems.
Sorting OIS Shooting Rates
For this analysis I just took the reported rates by the federal changes post already aggregated to city, and added in 2010 census estimates from Wikipedia. I’d note these are not necessarily the correct denominator, some jurisdictions may cover less/more of the pop that these census designated areas. (Also you may consider other non-population denominators as well.) But just as a proof of concept I use the city population (which I suspect is what the original federal charges blog post used.)
The below graph shows the city population on the X axis, and the OIS rate per 100,000 on the Y axis. I also added in the average rate within these cities (properly taking into account that cities are different population sizes), and curves to show the 99% confidence interval funnel. You can see that the distribution is dispersed more than would be expected by the simple binomial proportions around the overall rate of close to 9 per 100,000.
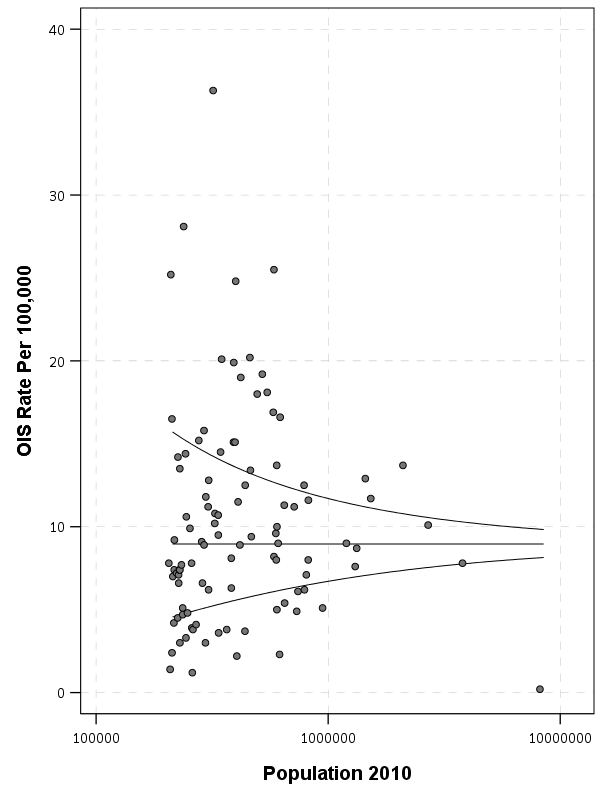
The following section I have some more notes on how I calculated the shrinkage, but here is a plot that shows the original rate, and the empirical Bayes shrunk OIS rate. The arrow points to the shrunk rate, so you can see that places with smaller population proportions and those farther away from the overall rate are shrunk towards the overall OIS rate within this sample.
To see how this changes the rankings, here is a slopegraph of the before/after rankings.
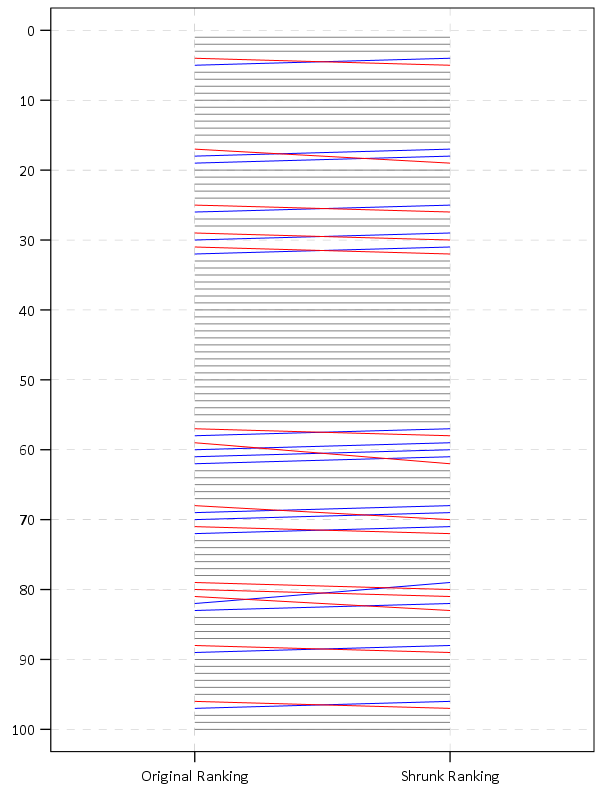
So most of the rankings only change slightly using this technique. But if one incorporated cities with smaller populations though they would change even more.
The federal charges post also calculates differences in the OIS rate versus the homicide rate. That approach suffers from even worse problems in ignoring the variance of smaller population denominators (it compounds two high variance estimates), but I think the idea of adjusting for homicide rates in this context maybe has potential in a random effects binomial model (either as a covariate or a multivariate outcome). Would need to think about it/explore it some more though. Also to note is that the fatal encounters data is multiple years, so don’t be confused that OIS rates by police are larger than yearly homicide rates.
The Mathy Part, Empirical Bayes Shrinkage
There are a few different ways I have seen reported to do empirical Bayes shrinkage. One is estimating the beta distribution for the entire sample, and then creating a shrunk estimate for the observed rates for individual observations using the observed sample Beta estimates as a prior (hence empirical Bayes). David Robinson has a nice little e-book on batting averages and empirical Bayes that can be applied to basically any type of percentage estimate you are interested in.
Another way I have seen it expressed is based on the work of the Luc Anselin and the GeoDa folks using explicit formulas.
Either of these ways you can do in a spreadsheet (a more complicated way is to actually fit a random effects model), but here is a simpler run-down of the GeoDa formula for empirical shrinkage, which is what I use in the above example. (This will not necessarily be the same compared to David Robinson’s approach, see the R code in the zip file of results for comparisons to David’s batting average dataset, but are pretty similar for that example.) So you can think of the shrunk rate as a weighted average between the observed rate for location i as y_i, and the overall rate mu, where the weight is W_i.
Shrunk Rate_i = W_i*y_i + (1 - W_i)*muYou then need to calculate the W_i weight term. Weights closer to 1 (which will happen with bigger population denominators) result in only alittle shrinkage. Weights closer to 0 (when the population denominator is small), result in much larger shrinkage. Below are the formulas and variable definitions to calculate the shrinkage.
i = subscript to denote area i. No subscript means it is a scalar.r_i = total number of incidents (numerator) in area ip_i = total population in area i (denominator)y_i = observed rate in area i = r_i/p_ik = total number of areas in studymu = population mean rate = sum(r_i)/sum(p_i)v = population variance = sum(p_i*[y_i - mu]^2]) / [sum(p_i)] - mu/(sum(p_i)/k)W_i = shrinkage weight = v /[v + (mu/p_i)]
For those using R, here is a formula that takes the numerator and denominator as vectors and returns the smoothed rate based on the above formula:
#R function
shrunkrate <- function(num,den){
sDen <- sum(den)
obsrate <- num/den
k <- length(num)
mu <- sum(num)/sDen
pav <- sDen/k
v <- ( sum( den*(obsrate-mu)^2 ) / sDen ) - (mu/pav)
W <- v / (v + (mu/den))
smoothedrate <- W*obsrate + (1 - W)*mu
return(smoothedrate)
}For those using SPSS I’ve uploaded macro code to do both the funnel chart lines and the shrunk rates.
For either missing values might mess things up, so eliminate them before using the functions. For those who don’t use stat software, I have also included an Excel spreadsheet that shows how to calculate the smoothed rates. It is in this zip file, along with other code and data used to replicate my graphs and results here.
For those interested in other related ideas, see
- Bayesian surprise maps by Michael Correll and Jeffrey Heer
- Xan Gregg’s post on using binomial Z-scores for proportion data and maps those residuals.
- A different approach I have seen suggested besides empirical Bayes shrinkage to the same problem is to take the lower bound on the confidence interval for the proportion and sort based on that lower bound.


1 Comment