
So I am a big fan of using splines in regression equations to model non-linear effects. But a limitation of these is that you need to upfront say how many knots you want, as well as where the knots are. So I have explored a bit on fitting models that can identify the changepoints themselves. It was a tricky road, I tried building some in deep learning using pytorch, then tried variational auto-encoders in pyro, then pystan (marginalizing the changepoint out), and then pymc3 (using different samplers). All of my attempts failed! But when I used the R mcp library (Lindeløv, 2020), it was able to find my changepoint using simulated data. (It uses JAGS under the hood, no idea why JAGS behaved better than my other attempts.)
Usecase: Dropoff effect of CCTV on clearance rates
So in spatial criminology, a popular hypothesis is estimating distance decay effects. Ratcliffe (2012) was the first example of using a changepoint regression model to do this, showing a changepoint in the effect of bars on the spatial density of crime nearby. This has been replicated in Xu & Griffiths (2017), and in my work using machine learning and partial dependence plots I show similar changepoint patterns as well (Wheeler & Steenbeek, 2020).
One example use case though I want to mention is not in terms of estimating the spatial density of crime, but with the characteristics of the crime events themselves. Sometimes people I think mistakenly think since I have spatial data, I need to aggregate it to some areal unit, and then do analysis of that areal unit data. That approach is not per-se wrong, but is sometimes a step removed from what you want, and can result in some tricky inferences.
Take for example a recent paper looking at clearances and using RTM by Kennedy et al. (2020). What they do is spatially aggregate homicides cleared and homicides not cleared, and run RTM on each. You might be tempted to interpret if a factor is selected for both models that it does not impact clearances, but it also depends on the size of the effect. So for example, in Brooklyn for drug markets they report a rate ratio of 3.1 and 2.4 (both at the same spatial distance). To translate this into a clearance rate, you need to add the two density estimates for all cases, and then take the cleared cases as the numerator.
# Example R code
clear <- exp(-0.1 + log(3.1))
nonclear <- exp(-0.1 + log(2.4))
prop <- clear/(clear + nonclear)
prop #0.5636364Here I am treating -0.1 as the intercept. So here this is lower, but close to the overall clearance in Brooklyn, 58%. This 56% will be the estimate iff the intercept for each equation is the same, if they are not though it could change the clearance rate estimate either way. Since the Kennedy paper did not report this, we cannot know. So for instance, if we change the intercept estimates so clearances are higher and non-clearances are lower, we get an estimate that drug markets increase clearances slightly, not decrease them:
clear <- exp(-0.05 + log(3.1))
nonclear <- exp(-0.2 + log(2.4))
prop <- clear/(clear + nonclear)
prop #0.6001124In this example it probably won’t push them too far either way, but takes a bit of work going from the aggregate data analysis to the estimate we want, how those spatial risk factors impact the clearance rate. There is an easier way though – just incorporate your spatial features, such as the distance the nearest crime generator factor, and estimate a model on the micro level incident data. This is what Kennedy et al. (2020) do later in the paper when incorporating the RTM predictions – I just think they should have done the RTM machinery directly on this problem, instead of the two-step approach.
Examples of my work I have done this approach in the past (incorporating spatial data into the micro level incidents) is with fatalities from gun shot wounds (Circo & Wheeler, 2020). We actually investigated non-linear effects though of distance/drive-time, and did not find evidence of that. Going back to the crime clearance example though, another pre-print I examine the effects of CCTV cameras and find a diminishing effect of case clearances given the distance to the camera (Jung & Wheeler, 2019).
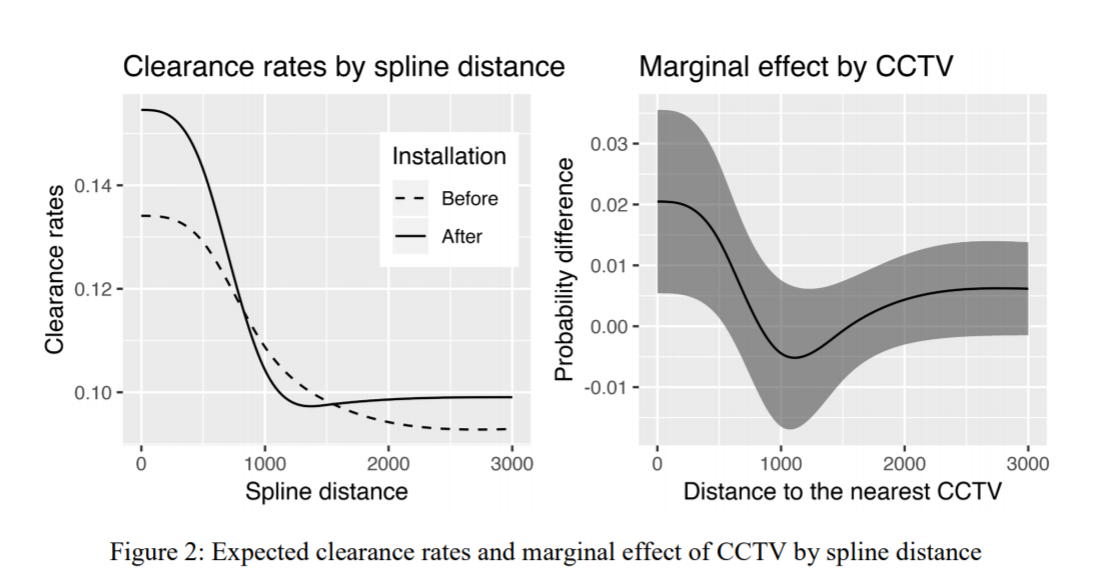
So here we use a pre-post design to show there are some selection effects, and we do further analysis to show this camera bump in clearances is only limited to thefts. But we set the splines at 500, 1000, and 1500 feet pre-emptively for the analysis. A reviewer critique of this is that those three locations are arbitrary (which is correct), so here I will see if I do a changepoint model that allows us to find the knot locations if it will show the same ones.
The idea behind this analysis is that CCTV are often used in investigations. Yeondae is an officer in Korea, same as here in the states first things detectives do is to go and grab CCTV footage. Analysis of cameras are often aggregated to their viewsheds, but I think estimating distance decay effects make as much sense. So events closer to the cameras presumably will provide more clear evidence than events at the border of the viewshed. A second point is that even if the event takes place off-camera, there may be evidence cross by the camera viewshed. Detectives will often try to follow individuals across multiple cameras. So both of those factors suggest a distance decay effect both within a cameras viewshed and a decaying effect even outside of the viewshed. (In addition to this, geo coordinates of crime locations are not perfectly accurate measures either, so that could cause effects outside of the viewshed as well.)
Here I am just limiting the data to the post camera data within 3000 feet for thefts, which still is over 26,000 observations. I’ve posted the data/code to follow along here.
Analysis using mcp in R
Again given my hardship in coding this up myself in python, I created a simulated data example and checked the results using mcp (which you can check in my code). Since mcp recovered my simulated changepoint, (and my python attempts did not), going to go ahead with the mcp library! First, we will import my clearance data and get rid of a few missing cases.
#################
library(mcp)
library(ggplot2)
set.seed(10)
#can see I planned on doing this in pytorch at first!
setwd('D:\\Dropbox\\Dropbox\\Documents\\BLOG\\changepoint_pytorch\\Analysis')
theft_clear <- read.csv('PostTheft_CCTV.csv')
theft_clear <- theft_clear[complete.cases(theft_clear),]
#################So first for a reference, if I assume there is a linear changepoint at 1000 feet, here are what my results look like. Note here that this is not aggregated data to spatial locations, each row in this dataset is a theft offense, whether it was cleared, and the distance to the nearest CCTV camera.
#################
#What are the coefficients if assume a changepoint of 1000 feet
theft_clear$x_dif <- (theft_clear$CAM.DIST - 1000)*(theft_clear$CAM.DIST > 1000)
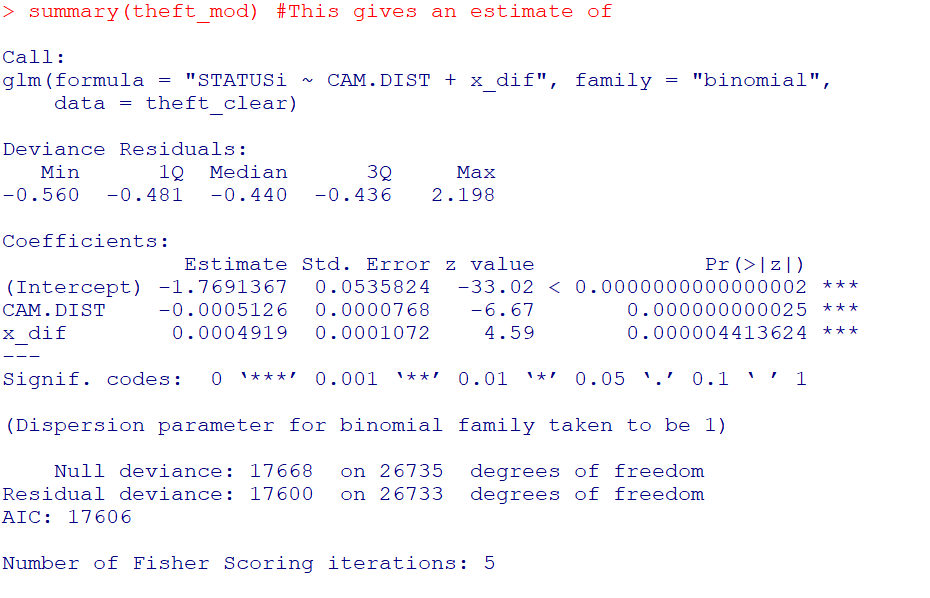
theft_mod <- glm(formula = 'STATUSi ~ CAM.DIST + x_dif', family = "binomial", data = theft_clear)
summary(theft_mod) #This gives an estimate of
#################
And here you can visualize the results alittle easier than trying to back out probabilities for the regression equation:
#################
pred_mod <- predict(theft_mod,type='response')
plot(theft_clear$CAM.DIST,pred_mod, main="Changepoint at 1000 ft",
xlab="Distance from Camera (ft)", ylab="Probability Clearance")
#################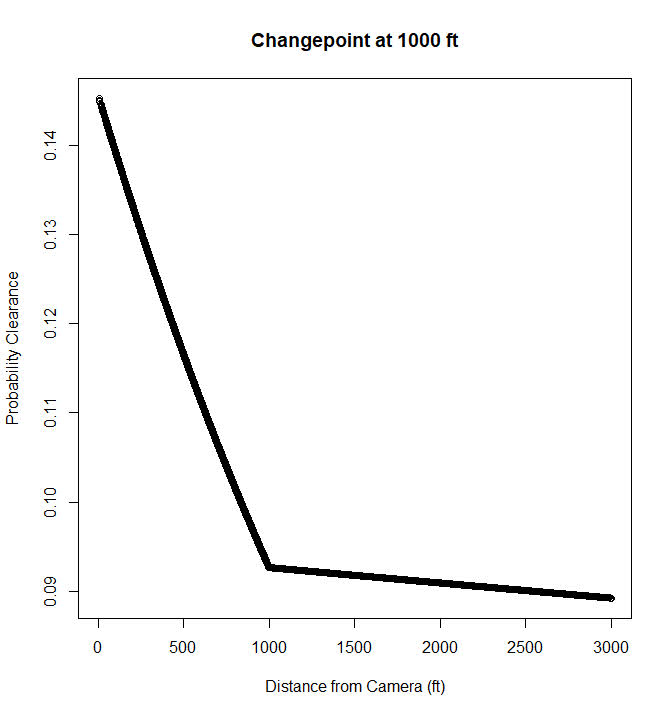
So this shows clearances nearby cameras in Dallas are around 15%, and they trail off to around 9% at 1000 feet. After that they continue to tail off, but are nearly flat. But again that is assuming a change point at 1000 feet. But the mcp package lets us actual estimate the changepoint itself using Bayesian regression. Here is the set up that is equivalent to my formulation earlier, in that the changepoint cannot be discontinuous.
#################
theft_clear$x <- theft_clear$CAM.DIST
model = list(
STATUSi | trials(const) ~ 1 + x,
~ 0 + x #joined changing rate
)
fit = mcp(model, data = theft_clear, family = binomial(), iter = 3000, adapt = 500)
#################And then if you are following along you can go ahead and take a nap (maybe took 2 hours on my machine?), and when we get back summary(fit) gives us:

So we have very similar coefficients to the manual changepoint model earlier, but the changepoint is around 1600 feet, not 1000. (Although note these are Bayesian credible intervals, not frequentist confidence intervals.) And now to make a nice plot of the fitted model.
#Fitted values for new data
newdat <- data.frame(x = (0:300)*10)
newdat$const <- 1
newdat$CAM.DIST <- newdat$x
res <- fitted(fit, newdata = newdat)
p_pred <- ggplot(data=res) +
geom_line(size=1.2, color='black', aes(x = x, y = fitted)) +
geom_ribbon(alpha=0.5, fill='black', aes(x = x, ymin=Q2.5 , ymax=Q97.5)) +
scale_x_continuous(name="Feet from Camera",breaks=seq(0,3000,500),minor_breaks=NULL) +
scale_y_continuous(name="P(Clearance)",breaks=seq(0.06,0.16,0.02),minor_breaks=NULL) +
theme_bw() + theme(panel.grid.major = element_line(colour = 'grey', linetype = 'dashed', size=0.1)) +
theme(text = element_text(size=20))
p_pred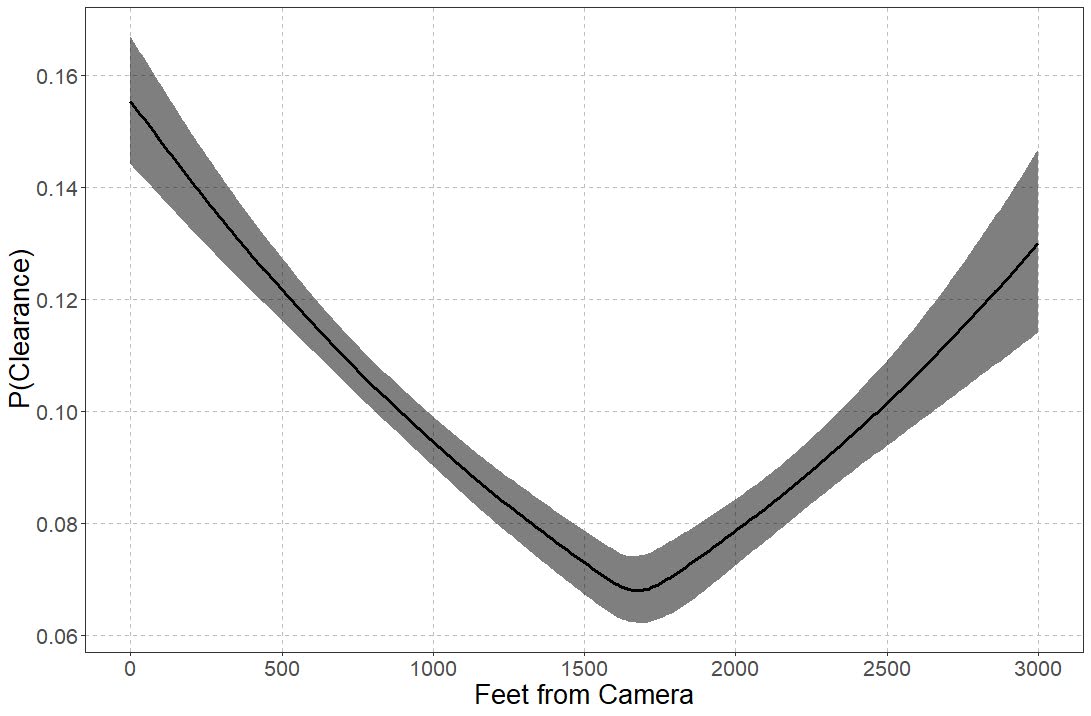
So you can see that here it is a nearly linear drop off until 1600 feet, and then starts to climb back up. The climb up I think is likely due to selection effects, but we can’t 100% rule out displacement effects. Displacement effects could occur with cameras if detectives prioritize events around cameras and de-prioritize other events not nearby cameras. Skeptical that applies to thefts in Dallas though, as they very rarely will be assigned a detective at all.
Wrap Up
So this ended up taking me for a few different turns. One of the things I wanted to be able to test multiple changepoints, maybe if I can ever get pymc3 to give me a reasonable fit, this example is a good illustration. That should also maybe say if you should have no changepoint as well. I think maybe it is much harder to fit those models with binomial data though than with continuous (maybe good for another blog post as well, did simulations at first with 1000 observations and that was a bad idea).
One thing that would be good for evaluating whether change points are reasonable are out of sample predictive comparisons. So say estimate a no changepoint model, a linear changepoint model, and then a model with fixed spline locations. Then see which of those better fits the out of sample data. But since this is a blog post, will leave it as is. But this is a simple illustration to extend prior spatial analysis of changepoints in distance decay effects to one example – crime clearances and CCTV cameras – that I think makes alot of sense.
References
- Circo, G. M., & Wheeler, A. P. (2020). Trauma Center Drive Time Distances and Fatal Outcomes among Gunshot Wound Victims. Applied Spatial Analysis and Policy, Online First.
- Kennedy, L. W., Caplan, J. M., Piza, E. L., & Thomas, A. L. (2020). Environmental Factors Influencing Urban Homicide Clearance Rates: A Spatial Analysis of New York City. Homicide Studies, Online First.
- Lindeløv, J. K. (2020). mcp: An R Package for Regression With Multiple Change Points. Preprint, OSF.
- Jung, Y., & Wheeler, A. (2019). The effect of public surveillance cameras on crime clearance rates. Preprint, OSF.
- Ratcliffe, J. H. (2012). The spatial extent of criminogenic places: a changepoint regression of violence around bars. Geographical Analysis, 44(4), 302-320.
- Wheeler, A. P., & Steenbeek, W. (2020). Mapping the risk terrain for crime using machine learning. Journal of Quantitative Criminology, Online First.
- Xu, J., & Griffiths, E. (2017). Shooting on the street: Measuring the spatial influence of physical features on gun violence in a bounded street network. Journal of Quantitative Criminology, 33(2), 237-253.


2 Comments