
When interpreting regression model coefficients in which the predictions are non-linear in the original variables, such as when you have polynomial terms or interaction effects, it is much simpler to make plots of the predicted values and interpret those than it is to interpret the coefficients directly.
This came up in some discussion of interpreting polynomial terms on the SPSS list-serve recently, and the example I will use came from this CrossValidated question. So I figured a blog post showing how to do it in SPSS was warranted.
So to start off I will make some fake data to work with, note the highly non-linear function Y is of the covariates.
FILE HANDLE save /NAME = "!Your Handle Here!".
INPUT PROGRAM.
LOOP Id = 1 TO 3000.
END CASE.
END LOOP.
END FILE.
END INPUT PROGRAM.
VECTOR X(3).
LOOP #i = 1 TO 3.
COMPUTE X(#i) = RV.NORMAL(0,1).
END LOOP.
COMPUTE Y = 5 + 0.6*(X1) + 0.2*(X2) + -3*(X3) +
0.38*(X1**2) + 0.15*(X2**2) + -0.1*(X3**2) +
0.3*(X1*X2) + -0.1*(X2*X3) + RV.NORMAL(0,1).
COMPUTE X1SQ = X1**2.
COMPUTE X2SQ = X2**2.
COMPUTE X3SQ = X3**2.
COMPUTE X1X2 = X1*X2.
COMPUTE X2X3 = X2*X3.Now I am going to use REGRESSION to estimate the model with all of the terms and save the model to an XML file (at the save handle location defined before I made the fake data). The point of saving the model estimates is to use it later on to score predictions to a new set of data.
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Y
/METHOD=ENTER X1 X2 X3 X1SQ X2SQ X3SQ X1X2 X2X3
/OUTFILE=MODEL('save\LinModel.xml').For illustration of how informative the model coefficients are, below is an image of the table. Given the sample size of 3000 and the small amount of error I added the coefficients are very close the the simulated model.
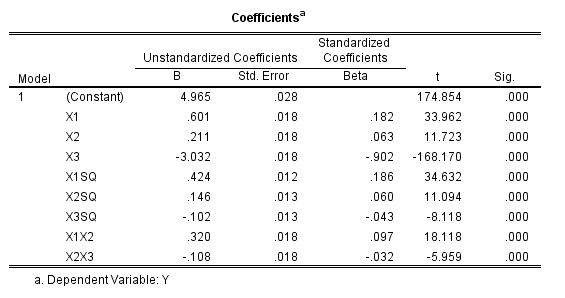
Now tell me based on the table if X1 takes a value of -1 and X3 takes a value of 0, does a change in X2 from -1 to 0 result in a positive change to the outcome or a negative change in the outcome? If you can figure out the direction of the change how large is the effect? This information is not impossible to cull from the table, but do your readers a favor and spare them these mental calculus gymnastics and plot the effects!
To do that I am going to make a new set of data in regular intervals over the explanatory values of interest.
*Now making a new set of variables to score the model.
DATASET CLOSE ALL.
INPUT PROGRAM.
COMPUTE #dens = 10.
COMPUTE #min = -2.
COMPUTE #max = 2.
COMPUTE #step = (#max - #min)/#dens.
LOOP #x1 = 0 TO #dens.
LOOP #x2 = 0 TO #dens.
LOOP #x3 = 0 TO #dens.
COMPUTE Id = #x2.
COMPUTE X1 = #min + #step*#x1.
COMPUTE X2 = #min + #step*#x2.
COMPUTE X3 = #min + #step*#x3.
END CASE.
END LOOP.
END LOOP.
END LOOP.
END FILE.
END INPUT PROGRAM.
COMPUTE X1SQ = X1**2.
COMPUTE X2SQ = X2**2.
COMPUTE X3SQ = X3**2.
COMPUTE X1X2 = X1*X2.
COMPUTE X2X3 = X2*X3.
EXECUTE.Here I used the INPUT MODEL and loops to control the sampling of where the independent variables are located at. Now you can score the model using the MODEL HANDLE and the subsequent APPLYMODEL statements available for computation.
*Score the model.
MODEL HANDLE NAME=LinModel FILE='save\LinModel.xml'
/OPTIONS MISSING=SUBSTITUTE.
COMPUTE StandardError=APPLYMODEL(LinModel, 'STDDEV').
COMPUTE PredictedValue=APPLYMODEL(LinModel, 'PREDICT').
EXECUTE.
MODEL CLOSE NAME=LinModel.
FORMATS X1 X2 X3 X1SQ X2SQ X3SQ X1X2 X2X3 (F3.1)
PredictedValue (F2.0).Now we have a set of predictions and standard errors for our model. Given the three way set of interactions what I do is make a plot that has X1 on the X axis, varying values of X2 as a set of individual lines (with the color of the line a continuous color ramp) and panelled by values of X3.
*Make predicted graph.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=X1 PredictedValue X2 X3 Id
MISSING=LISTWISE REPORTMISSING=NO
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
PAGE: begin(scale(800px,600px))
SOURCE: s=userSource(id("graphdataset"))
DATA: X1=col(source(s), name("X1"))
DATA: PredictedValue=col(source(s), name("PredictedValue"))
DATA: X2=col(source(s), name("X2"))
DATA: X3=col(source(s), name("X3"), unit.category())
DATA: Id=col(source(s), name("Id"), unit.category())
COORD: rect(dim(1,2), wrap())
GUIDE: axis(dim(1), label("X1"))
GUIDE: axis(dim(2), label("PredictedValue"))
GUIDE: axis(dim(3), label("X3"), opposite())
GUIDE: legend(aesthetic(aesthetic.color.interior), label("X2"))
SCALE: linear(aesthetic(aesthetic.color.interior), aestheticMinimum(color.green),
aestheticMaximum(color.purple))
ELEMENT: line(position(X1*PredictedValue*X3), color.interior(X2), split(Id),
transparency(transparency."0.3"))
PAGE: end()
END GPL.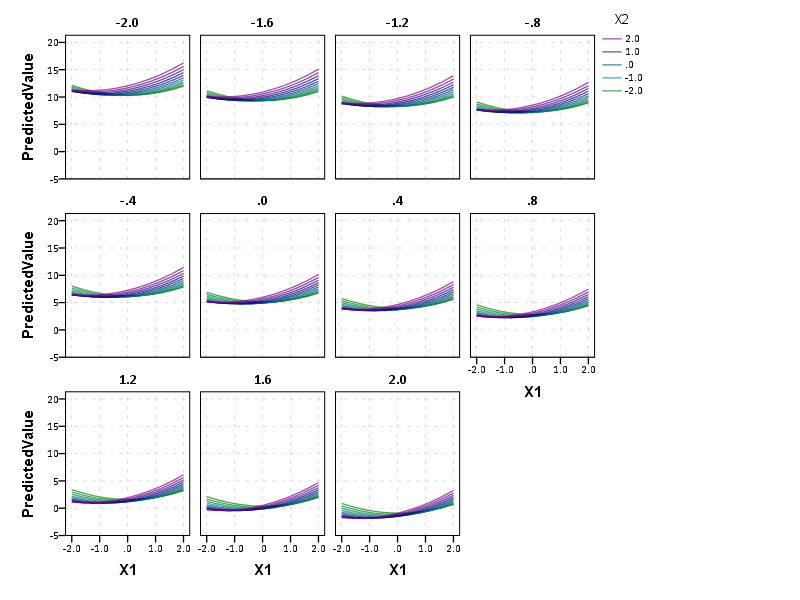
So lets try to answer my original question now: if X1 takes a value of -1 and X3 takes a value of 0, does a change in X2 from -1 to 0 result in a positive change to the outcome or a negative change in the outcome?
Answer: The predicted value of Y at the covariate values of X1 = -1 and X3 = 0 can be seen in the middle row of panels, second in from the left. The predicted values appear to range between 5 and 6 for the given values of X2. Going up in value for X2 (from green to purple) results in a slight decrease in the predicted value, probably less than 1 in total.
Interpreting the equation more generally though, the values of X3 mainly serve as a change in intercept of the predicted values. The shape of the slopes only changes slightly between panels – but X3 acts a moderator – bringing the slopes closer together. X2 acts a moderator on X1 in most circumstances. The green lines tend to be lower than the purple lines when both X1 and X2 take positive values, but that isn’t the whole story. Describing X2 in terms of mediating or moderating X1 is insufficient here, as you can see when both take negative values the relationship is switched and causes decreases in values of Y. When both are positive, the relationship is moderated, and a smaller change in X1 results in a larger change in the predicted value.
Now, linear OLS regression models typically don’t have so many complicated interaction and polynomial terms. But other regression models that have a link functions (e.g. Logistic, Poisson) are non-linear in the parameters when taking the inverse of the function. So even if they don’t have interaction terms they are prime candidates for similar plots of predicted values with a set of different lines and panels for various values of other explanatory variables in the model. My generic experience is looking at odds ratios (or incident rate ratios) tends to give an overly dramatic representation of effects compared to these types of plots.
When interpreting different effects of changing the explanatory variables these graphs are definitely easier to see the marginal changes of interest than the original regression coefficients. Imagine if Y in this example are physical fitness test scores, and the X’s are time spent in various exercise routines. If you are a Phys. Ed. teacher, you may want to spend more time in one activity, but since time is zero-sum you have to take time away from another. In that case, looking at the original coefficients can be slightly misleading, as you can’t increase X1 by 1 without decreasing X2 or X3 by an equivalent amount.
In this situation, the optimal scenario would be having X3 as low as possible and X1 and X2 as high as possible. For scenarios in which X3 is positive though the predictions dip in the middle, so you are better off having more extreme values of X1 and X2 then you are of having them around 0 in those circumstances.


1 Comment