
Deborah Osborne had a chat with Chris Bruce the other day about general crime analysis, and they discussed the regular reading of reports. I did this as well when I worked at Troy New York as the lone analyst. I would come in and skim the ~50 reports for the prior day.
The chief and mayor wanted a breakdown of particular noteworthy events, so I would place my own notes in a spreadsheet and then make a daily report. My set up was not fully automated but close – I had a pretty detailed HTML template, and once my daily data was inputted, I would run a SPSS script to fill in the HTML. I also did a simple pin map in batch geo (one thing that was not automated about it) and inserted into the report.
I had two other quite regular reports I would work on. One was a weekly command staff report about overall trends and recent upticks, the other was a monthly Compstat meeting going over similar stats. (I also had various other products to release – detective assignments/workload, sending aggregate stats to the Albany Crime Analysis Center.)
If I had to do these again knowing what I know now, I would automate nearly 100% of this work in python. For the reports, I would use jupyter notebooks (I actually do not like coding in these very much, I much prefer plain text IDEs, but they are good for generating nice looking reports I will show.)
Making Reports in Jupyter Notebooks
I have provided the notes to fully automate a simple report here on Github. To replicate, first you need to download the Dallas PD open data and create a local sqlite database (can’t upload that large of file to github).
So first before you start, if you download the .py files, you can run at the command prompt something like:
cd D:\Dropbox\Dropbox\PublicCode_Git\Blog_Code\Python\jupyter_reports
python 00_CreateDB.pyJust replace the cd path to wherever you saved the files on your local machine (and this assumes you have Anaconda installed). Then once that is done, you can replicate the report locally, but it is really meant as a pedogological tool – you can see how I wrote the jupyter notebook to query the local database. For your own case you would write the SQL code and connection to whereever your local crime data is store.
Here is an example of how you can use string substitution in python to create a query that is date aware for when the code is run:
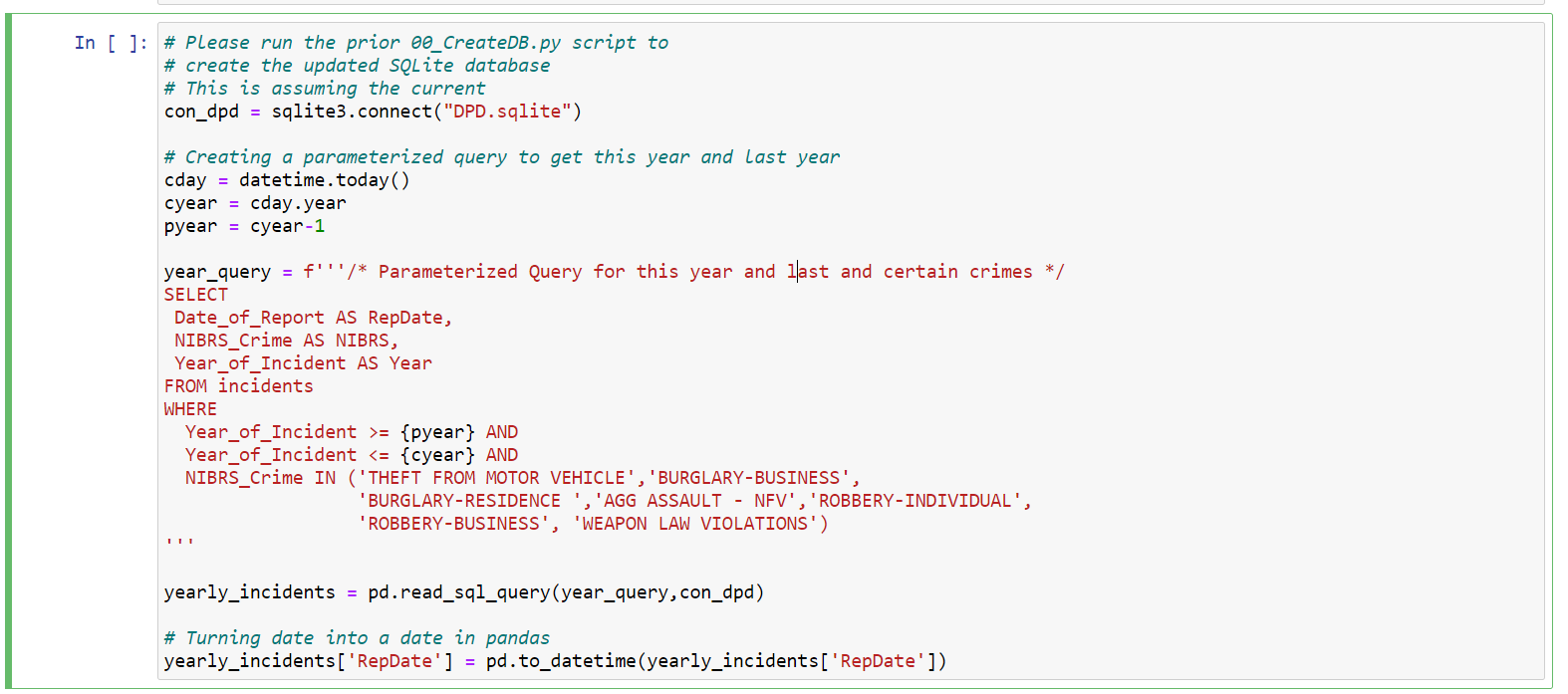
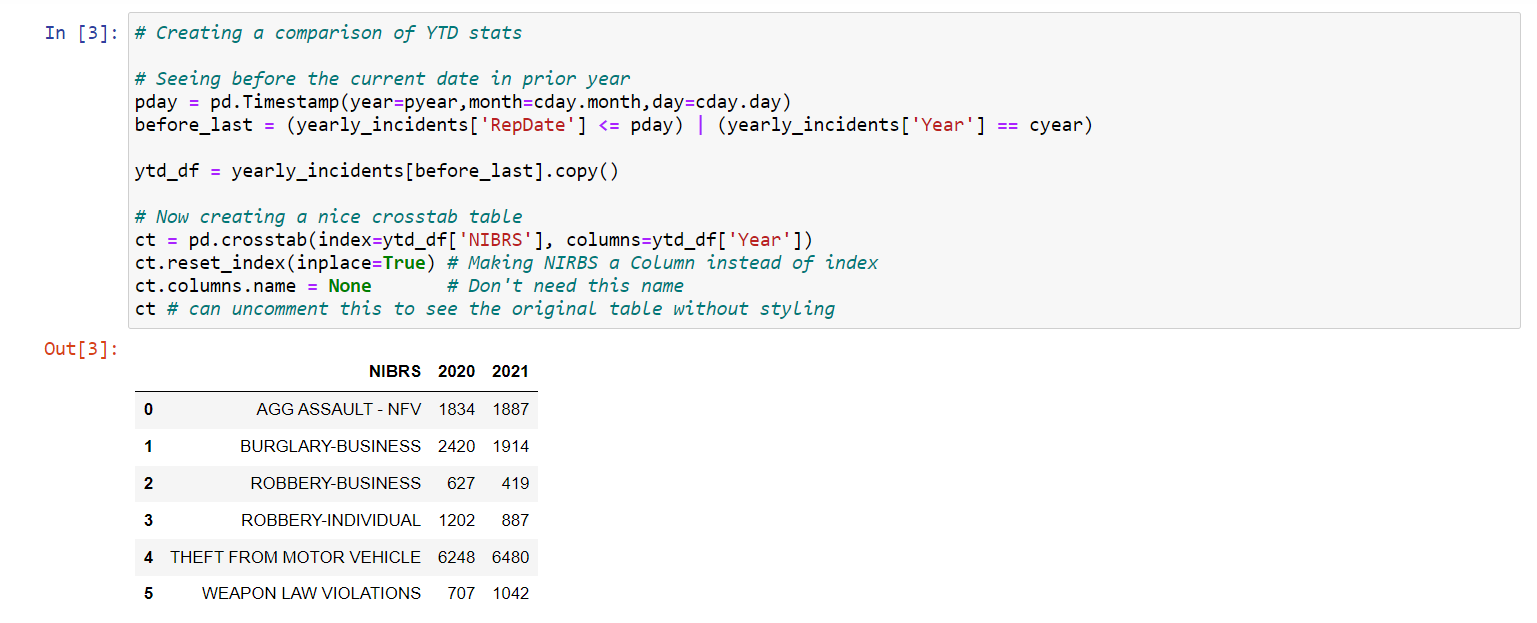
Part of the hardest part of making standardized reports is you can typically make the data formatted how you want, but to get little pieces looking exactly how you want them is hard. So here is a default pivot table exported in a Jupyter notebook for some year to date statistics (note the limitations of this, why I prefer graphs and do not show a percent change).
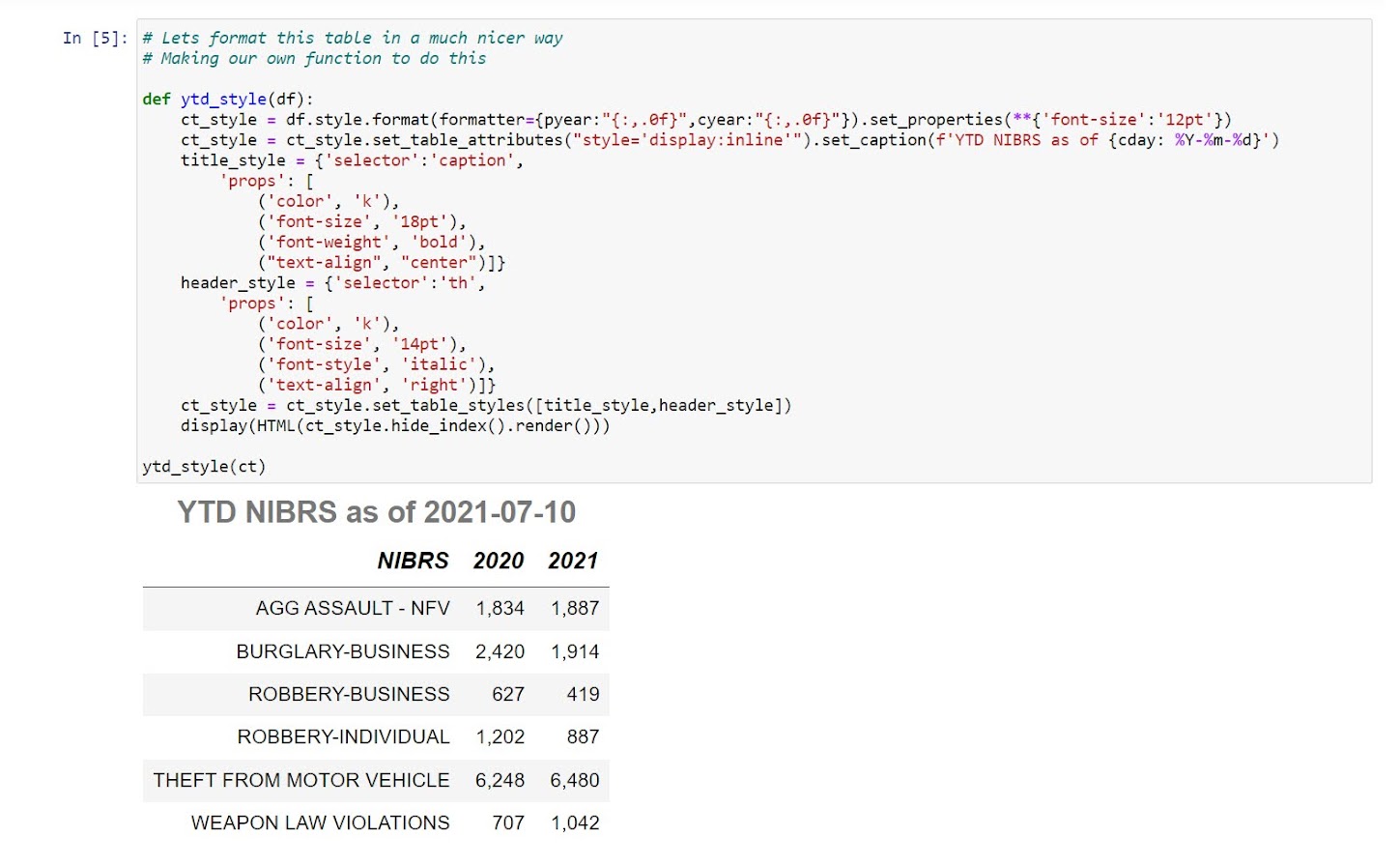
And here is code I wrote to change font sizes and insert a title. A bit of work, but once you figure it out once you are golden.
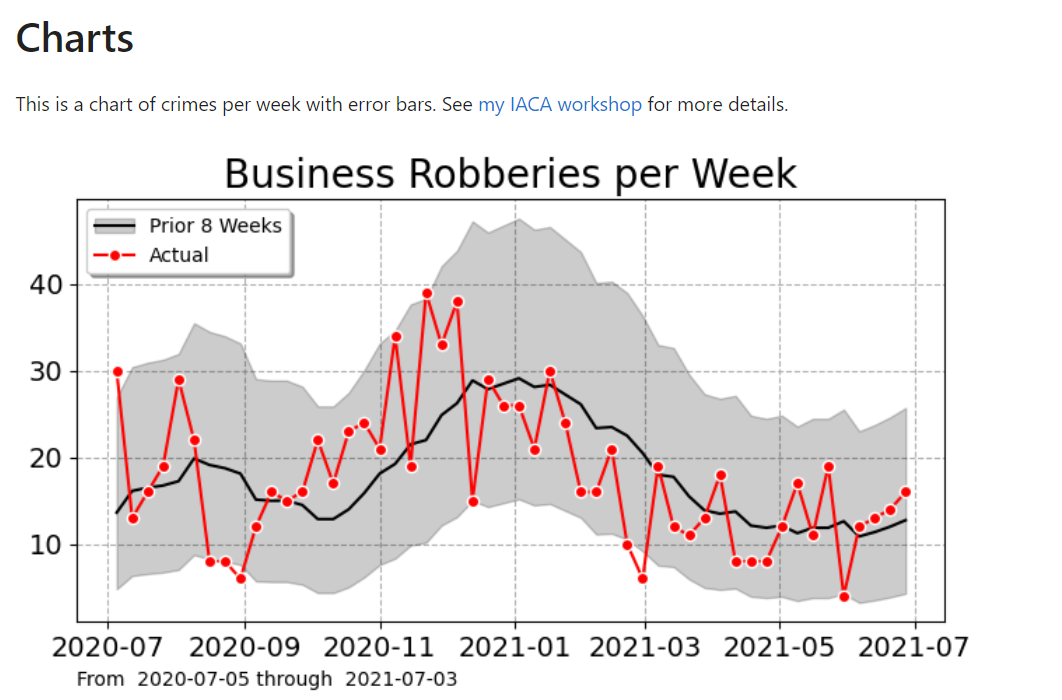
You can go look at the notebook itself, but I also have an example of generating a weekly error bar chart (much preferred over the Compstat YTD tables):
Final note, to compile the notebook without showing any code (the police chief does not want to see your python code!), it looks like this from the command line.
jupyter nbconvert --execute example_report.ipynb --no-input --to htmlI have further notes in the github page on automating this fully via bat files for windows, renaming files to make them update to the current date, etc.
Why Automate?
I know some analysts are reading this and thinking to themselves – I can generate these reports in 30 minutes using Excel and Powerpoint – why spend time to learn something new to make it 100% automated? There are a few reasons. One is pure time savings in the end. Say for the weekly report you spend 1 hour, and it takes you three work days (24 hours) to fully automate. You will recover your time in 24 weeks.
Time savings is not the only component though. Fully automating means the workflow is 100% reproducible, and makes it easier to transfer that workflow to other analysts in the future. This is an important consideration when scaling – if you need to spend a few hours once a week forever, you can only take on generating so many reports. It is better for your time to do a one time large sink into automating something, than to loan out a portion of your time forever.
A final part is the skills you develop when generating automated reports are more similar to data science roles in the private sector – so consider it an investment in your career as well. The types of machine learning pipelines I create at my current role would not be possible if I could not fully automate. I would only be able to do 2 or maybe 3 projects forever and just maintain them. I fully automate my data pipelines though, and then can hand off that job to a DevOps engineer, and only worry about fixing things when they break. (Or a more junior data scientist can take over that project entirely.)

