
Lord’s paradox is a situation in which analyzing change scores between two time points results in different treatment effect estimates than analyzing the treatment effect of the second time point conditional on the first time point. In terms of regression equations we have the following as the change score model:

And the following as the conditional model:
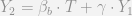
Lord’s paradox is the fact that 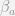

So lets say that we have an equation predicting


Lets also say that we cannot observe 

If we happen to have pre-treatment measures of 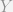
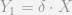
And so we can subtract the latter equation from the former to cancel out the omitted variable effect:

Now, a frequent critique of the change score model is that it assumes that the autoregressive effect of the baseline score on the post score is 1. See Frank Harrell’s comment on this answer on the Cross Validated site (also see my answer to that question as to why change scores that include the baseline on the right hand side don’t make sense). Holland and Rubin (1983) make the same assertion. To make it clear, these critiques say that change scores are only justified when in the below equation 
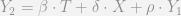
This caused me some angst though. As you can see in my original formulation there is no 
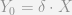
We can see that we could just replace 


Which is the same as saying 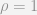

As always, the model one chooses should be balanced against alternatives in an attempt to reduce bias in the effect estimates we are interested in. When the unobserved and omitted
I end this post on a tangent. I recently revisited the material as I wanted to read Holland and Rubin (1983) which is a chapter in the reader Principals of moderns Psychological Measurement: A Festschrift for Frederic M. Lord. I also saw in that same reader a chapter by Melvin Novick, The centrality of Lord’s paradox and exchangeability for all statistical inference. At the end he was pretty daring in making some predictions for the state of statistics as of November 12, 2012 – so I am a year late with my Festschrift but they are still interesting fodder none-the-less. I’ll leave the reader to judge the extent Novick was correct in his following predictions:
- be less dependent on constricting models such as the normal and will primarily use more general classes of distributions, for example, the exponential power distribution;
- be fully Bayesian with full emphasis on the psychometric assessment of proper prior distributions;
- be fully decision theoretic with emphasis on the pyschometric assessment of individual and institutional utilities;
- use robust classes of prior distributions and utility functions as well as robust model distributions;
- rely completely on full-rank Bayesian univariate and multivariate analyses of variance and covariance using fully exchangeable, informative prior distributions as appropriate;
- emphasize exchangeability through careful modeling, blocking, and covariation with randomization playing a residual role;
- emphasize the use of posterior predictive distributions using the lessons of Lord’s paradox, exchangeability, and appropriate conditional probabilities;
- place great emphasis on numerical solutions when exact Bayesian solutions prove intractable;
- still use some pseudo Bayesian methods when both theoretical and computational fully Bayesian solutions remain intractable. (This prevision is subject to modification if I can convince Rubin, Holland and their associates to devote their impressive skills to the quest for fully Bayesian solutions. Should this happen, there may be no need for any pseudo Bayesian methods.)
Citations
- Allison, Paul. 1990. Change scores as dependent variables in regression analysis. Sociological methodology 20: 93-114.
- Holland, Paul & Donald Rubin. 1983. On Lord’s Paradox. In Principles of modern psychological measurement: A festchrift for Frederic M. Lord edited by Wainer, Howard & Samuel Messick pgs:3-25. Lawrence Erlbaum Associates. Hillsdale, NJ.
- Novick, Melvin. 1983. The centrality of Lord’s paradox and exchangeability for all statistical inference. In Principles of modern psychological measurement: A festchrift for Frederic M. Lord edited by Wainer, Howard & Samuel Messick pgs:3-25. Lawrence Erlbaum Associates. Hillsdale, NJ.
- Wainer, Howard & Samuel Messick. 1983. Principles of modern psychological measurement: A festchrift for Frederic M. Lord. Lawrence Erlbaum Associates. Hillsdale, NJ.


apwheele
/ May 6, 2019Apparently one can use this idea to bound treatment effect estimates when the parallel trends assumption is correct vs when the auto-regressive effect is not 1, see https://statmodeling.stat.columbia.edu/2019/05/06/difference-in-difference-estimators-are-a-special-case-of-lagged-regression/ and referenced works.