
For my dissertation I have been estimating negative binomial regression models predicting the counts of crimes at small places (i.e. street segments and intersections). When evaluating the fit of poisson regression models and their variants, you typically make a line plot of the observed percent of integer values versus the predicted percent by the models. This is particularly pertinent for data that have a high proportion of zeros, as the negative binomial may still under-predict the number of zeros.
I mistakenly thought that to make such a plot you could simply estimate the predicted value following the negative binomial regression model and then round the predictions. But I was incorrect, and to make the typical predicted versus observed plot you need to estimate the probability of an observation taking an integer value, and then take the mean of that probability over all the observations. That mean will subsequently be the predicted percent given the model. Fortunately I caught my mistake before I gave some talks on my work recently, and I will show how to make said calculations in SPSS. I have posted the data to replicate this work at this dropbox link, and so you can download the data and follow along.
First, I got some help on how to estimate the predicted probabilities via an answer to my question at CrossValidated. So that question lists the formula one needs to estimate the predicted probability for any integer value N after the negative binomial model. To calculate that value though we need to make some special SPSS functions, the factorial and the complete gamma function. Both have SPSS tech help pages showing how to calculate them.
For the factorial we can use a general relationship with the LNGAMMA function.
DEFINE !FACT (!POSITIONAL = !ENCLOSE("(",")"))
( EXP(LNGAMMA((!1)+1)) )
!ENDDEFINE.
And for the complete gamma function we can use a relationship to the CDF of the gamma function.
DEFINE !GAMMAF (!POSITIONAL = !ENCLOSE("(",")"))
( EXP(-1)/(!1)/(CDF.GAMMA(1,(!1),1) - CDF.GAMMA(1,(!1)+1,1)) )
!ENDDEFINE.
And given these two functions, we can create a macro that takes as parameters and returns the predicted probability we are interested in:
out– new variable name for predicted probability of taking on that integer valuePredN– the predicted mean of the variable conditional on the covariatesDisp– estimate of the dispersion parameterInt– the integer value being predicted
DEFINE !PredNB (Out = !TOKENS(1)
/PredN = !TOKENS(1)
/Disp = !TOKENS(1)
/Int = !TOKENS(1) )
COMPUTE #a = (!Disp)**(-1).
COMPUTE #mu = !PredN.
COMPUTE #Y = !Int.
COMPUTE #1 = (!GAMMAF(#Y + #a))/(!FACT(#Y)*!GAMMAF(#a)).
COMPUTE #2 = (#a/(#a+#mu))**#a.
COMPUTE #3 = (#mu/(#a + #mu))**#Y.
COMPUTE !Out = #1*#2*#3.
!ENDDEFINE.
But to make our plot we want to estimate this predicted probability over a range of values, so I created a helper macro that instead of taking only one integer value, takes the end integer value and will calculate the predicted probability of zero through N.
DEFINE !PredNBRange (Num = !TOKENS(1)
/Mean = !TOKENS(1)
/Disp = !TOKENS(1)
/Stub = !TOKENS(1) )
!DO !I = 0 !TO !Num
!LET !Base = !CONCAT(!Stub,!I)
!PredNB Out = !Base PredN = !Mean Disp = !Disp Int = !I.
!DOEND
!ENDDEFINE.
The example data and code I have posted compares these values to the ones predicted from Stata, and shows my function agrees with Stata to about 7 decimal points. I won’t go through all of those commands here, but I will show how to make the predicted proportions plot after you have a vector of predicted probabilities (you can download all of the code and data and the link I reference prior in the post).
So lets say that you have a vector NB0 TO NB8, and these are the predicted probabilities of integer values 0 to 8 for the observations in your dataset. To subsequently get the mean of the predictions, you can use the AGGREGATE command. Having no variables specified on the BREAK subcommand tells SPSS to aggregate over all values in the dataset. Here I export the file to a new dataset named PredNBAgg.
DATASET DECLARE PredNBAgg.
AGGREGATE OUTFILE='PredNBAgg'
/BREAK =
/NB0 TO NB8 = MEAN(NB0 TO NB8).
Now to merge later on to the observed proportions, I will reshape the dataset so the mean values are all in the same column using VARSTOCASES. Here I also make a category for the predicted probability of being 9 or higher (which isn’t typical for these types of plots, but something I believe is useful).
DATASET ACTIVATE PredNBAgg.
COMPUTE NB9_Plus = 1 - SUM(NB0 TO NB8).
VARSTOCASES /MAKE NBPred FROM NB0 TO NB9_Plus /INDEX Int.
COMPUTE Int = Int - 1. /*Index starts at 1 instead of 0 */.
Now I reactivate my original dataset, here named PredNegBin, calculate the binned observed values (with observations 9 and larger recoded to just 9) and then aggregate those values.
DATASET ACTIVATE PredNegBin.
RECODE TotalCrime (9 THRU HIGHEST = 9)(ELSE = COPY) INTO Int.
DATASET DECLARE PredObsAgg.
AGGREGATE OUTFILE='PredObsAgg'
/BREAK = Int
/TotalObs = N.
To get the predicted proportions within each category, I need to do another aggregation to get the total number of observations, and then divide the totals of each integer value with the total number of observations.
DATASET ACTIVATE PredObsAgg.
AGGREGATE OUTFILE = * MODE=ADDVARIABLES OVERWRITE=YES
/BREAK =
/TotalN=SUM(TotalObs).
COMPUTE PercObs = TotalObs / TotalN.
Now we can go ahead and merge the two aggregated datasets together. I also go ahead and close the old PredNBAgg dataset and define a value label so I know that the 9 integer category is really 9 and larger.
MATCH FILES FILE = *
/FILE = 'PredNBAgg'
/BY Int.
DATASET CLOSE PredNBAgg.
VALUE LABELS Int 9 '9+'.
Now at this point you could make the plot with the predicted and observed proportions in seperate variables, but this would take two ELEMENT statements within a GGRAPH command (and I like to make line plots with both the lines and points, so it would actually take 4 ELEMENT statements). So what I do here is reshape the data one more time with VARSTOCASES, and make a categorical variable to identify if the proportion is the observed value or the predicted value from the model. Then you can make your chart.
VARSTOCASES /MAKE Dens FROM PercObs NBPred /Index Type /DROP TotalObs TotalN.
VALUE LABELS Type
1 'Observed'
2 'Predicted'.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=Int Dens Type
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: Int=col(source(s), name("Int"), unit.category())
DATA: Type=col(source(s), name("Type"), unit.category())
DATA: Dens=col(source(s), name("Dens"))
GUIDE: axis(dim(1), label("Total Crimes on Street Units"))
GUIDE: axis(dim(2), label("Percent of Streets"))
GUIDE: legend(aesthetic(aesthetic.color.interior), null())
SCALE: cat(aesthetic(aesthetic.color.interior), map(("1",color.black),("2",color.red)))
ELEMENT: line(position(Int*Dens), color.interior(Type))
ELEMENT: point(position(Int*Dens), color.interior(Type), color.exterior(color.white), size(size."7"))
END GPL.
And voila, here you can see the predicted values are so close to the observed that it is difficult to even see the observed values. Here instead of creating a legend I manually added labels to the chart. A better chart may be to subtract the observed from predicted (especially if you were comparing multiple poisson models), but it should be quite plain to see that the negative binomial fits quite well to the observed data in this instance.
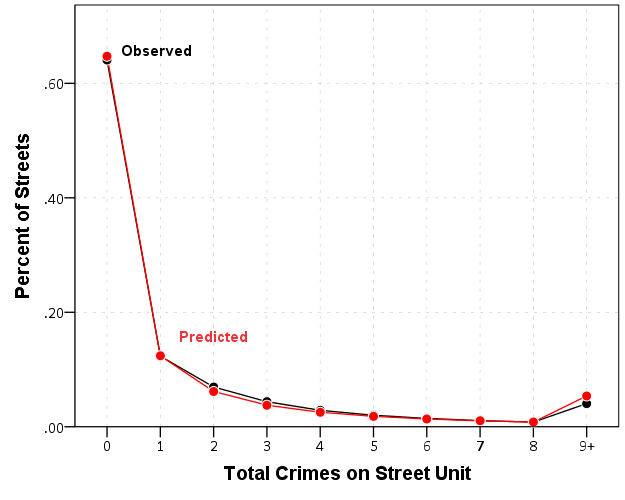
Similar to Paul Allison’s experience, even with nearly 64% of the observations being zero, the negative binomial model fits just fine. I recently fit some other models with the same data (but a different outcome) in which the number of zeros were nearer to 90%. In that instance the negative binomial model would not converge, so estimating a zero inflated model was necessary. Here though it is clearly not necessary, and I would prefer the negative binomial model over a zip (or hurdle) as I see no obvious reason why I would prefer the complications of the different predicted zero equation in addition to the count equation.


3 Comments