
While reviewing a paper recently it struck me that the content was (very) good, but the writing was stereotypical academic. My first impression was that this was caused by monotonously long sentences. See this advice from Gary Provost (via Francis Diebold). Part of the reason why long sentences are undesirable is not only for aesthetic reasons though — longer sentences are harder to parse, hold in memory, and subsequently understand. See Steven Pinker’s The Sense of Style writing guide for discussion.
So I did some text analysis of the sentences. To do the text analysis I used the nltk library in python, and here is the IPython notebook to replicate for yourself if you care to do so (apparently Wakari is not a thing anymore, so here is the corpus for Huck Finn and for my Small Sample paper). In the notebook I have saved two text corpuses, one my finished draft of this article. I compared the sentence length to Mark Twain’s Huckleberry Finn (text via here).
For a simple example getting started with the library, here is an example of tokenizing a string into words and sentences:
#some tests for http://www.nltk.org/, nice book to follow along
import nltk
#nltk.download('punkt') #need to download this for the English sentence tokenizer files
#this splits up punctuation
test = """At eight o'clock on Thursday morning Arthur didn't feel very good. This is a second sentence."""
tokens = nltk.word_tokenize(test)
print tokens
ts = nltk.sent_tokenize(test)
print tsThe first prints out each individual word (plus punctuation in some circumstances) and the second marks individual sentences. I have the line #nltk.download('punkt') commented out, as I downloaded it once already. (Running once in Wakari I did not need to download it again – I presume it would work similarly on your local machine.)
So what I did was transfer the PDF document I was reviewing to a text file and then clean up things like the section headers (ditto for my academic articles I compare it to). In Huckleberry I took out the table of contents and the “CHAPTER ?” parts. I also started a list of variables that were parsed as words but that I did not want to count after the sentences and words were tokenized. For example, an inline cite such as (X, 1996) would be split into 4 words with the original tokenizer, (, X, 1996 and ). The “x96” is an en-dash. Below takes those instances out.
#Get the corpus
f = open('SmallSample_Corpus.txt')
raw = f.read()
#Count number of sentences
sent_tok = nltk.sent_tokenize(raw)
ns = len(sent_tok)
#Count number of words
word_tok = nltk.word_tokenize(raw) #need to take out commas plus other stuff
NoWord = [',','(',')',':',';','.','%','\x96','{','}','[',']','!','?',"''","``"]
word_tok2 = [i for i in word_tok if i not in NoWord]
nw = len(word_tok2)
#Average Sentence length are words divided by sentences
print float(nw)/nsThere are inevitably more instances of things that shouldn’t be counted as words, but that makes the sentences longer on average. For example, I spotted a few possessive 's that were listed as different words. (The nltk library is smart and lists contractions as seperate words.)
So someone may know a better way to count the words, but all the articles should have the same biases. In my tests, here are the average number of words per sentence:
- article I was reviewing, 28
- my small sample article, 27
- my working article (that has not undergone review), 25
- Huck Finn, 20
So the pot is calling the kettle black here – my writing is not much better. I looked at the difference between an in-print article and a working draft, as responses to reviewers I bet will make the sentences longer. Hedges in statements that academics love.
Looking at the academic article histograms they are fairly symmetric, confirming my impression about monotonous sentence length. To make the histograms I used the panda’s library, which has a nice simple method.
sent_len = []
for i in sent_tok:
sent_w1 = nltk.word_tokenize(i)
sent_w2 = [i for i in sent_w1 if i not in NoWord]
sent_len.append(len(sent_w2))
import pandas as pd
dfh = pd.DataFrame(sent_len)
dfh.hist(bins = 50);Here is the histogram for my small sample paper:
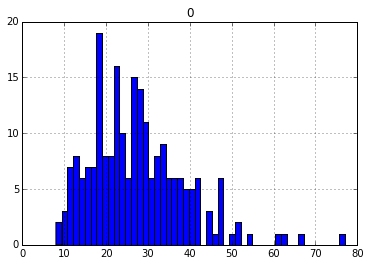
And here it is for Huck Finn
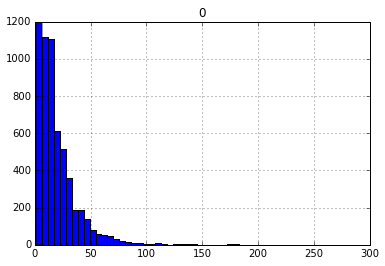
(I’m not much of an exemplar for making graphs in python – forgive the laziness in the figures.) Apparently analyzing sentence length has a long history, see a paper by G. Udny Yule in 1939! From a quick perusal the long right tail is more usual for analyzing texts. The symmetry I see for this sample of academic articles is not the norm.
There could be more innocuous reasons for this. Huck Finn has dialogue with shorter sentences, and the academic articles have numbers and citations. (Although I think it is reasonable to count those things towards sentence complexity, “1” or “one” should have the same complexity.)
I will have to keep this in mind in the future (maybe I should write my articles in poem form)!


Boghos L. Artinian MD
/ October 30, 2019Every time I submit an article for publication the editor replies
‘Please send the whole article’ to avoid saying ‘It’s damn short!’
So I am sending only ‘statements’ for publication.
Boghos L. Artinian MD