
Recently saw Kim Rossmo have a paper that describes a Bayesian approach to prioritizing areas for a search for missing persons. So he illustrates an approach to give a probability surface, but that still leaves implicit how individuals are to traverse over that probability space in the search itself.
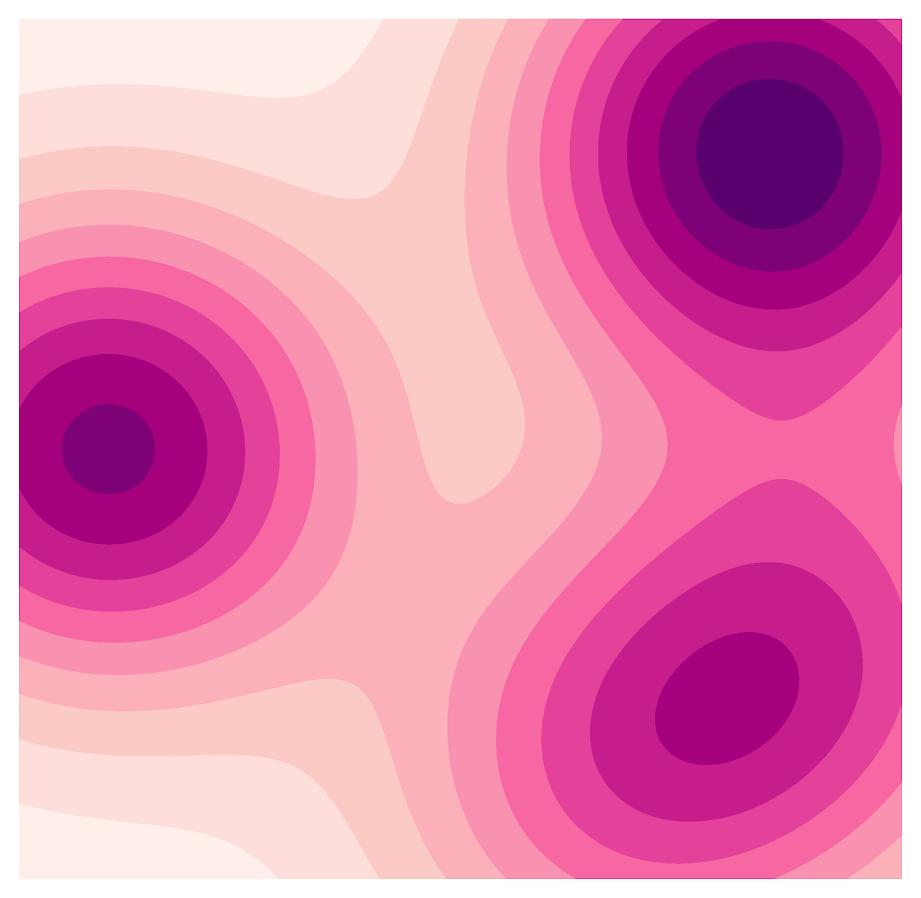
For an example of where there can be potential ambiguity even with the probability surface, in the surface below we have three hot spots. So if we have four people to search this area, and they can only search a finite connected area (so no hop-scotching around), should we have them split between each of the hot spots, or should they cover one of the hot spots in more detail. (It is hard to tell in my graph, but the hot spot in the central western part of the graph has a higher hump, but is steeper, so top right has more mass but is more spread out.)
I’ve actually failed to be able to generate a decent algorithm to do this though. It is similar to this prior work of mine, but I actually discovered some errors in that work in trying to apply it to this situation (can have disconnected subtours that are complicated paths). So attempted several other variants and have yet to come up with a decent solution.
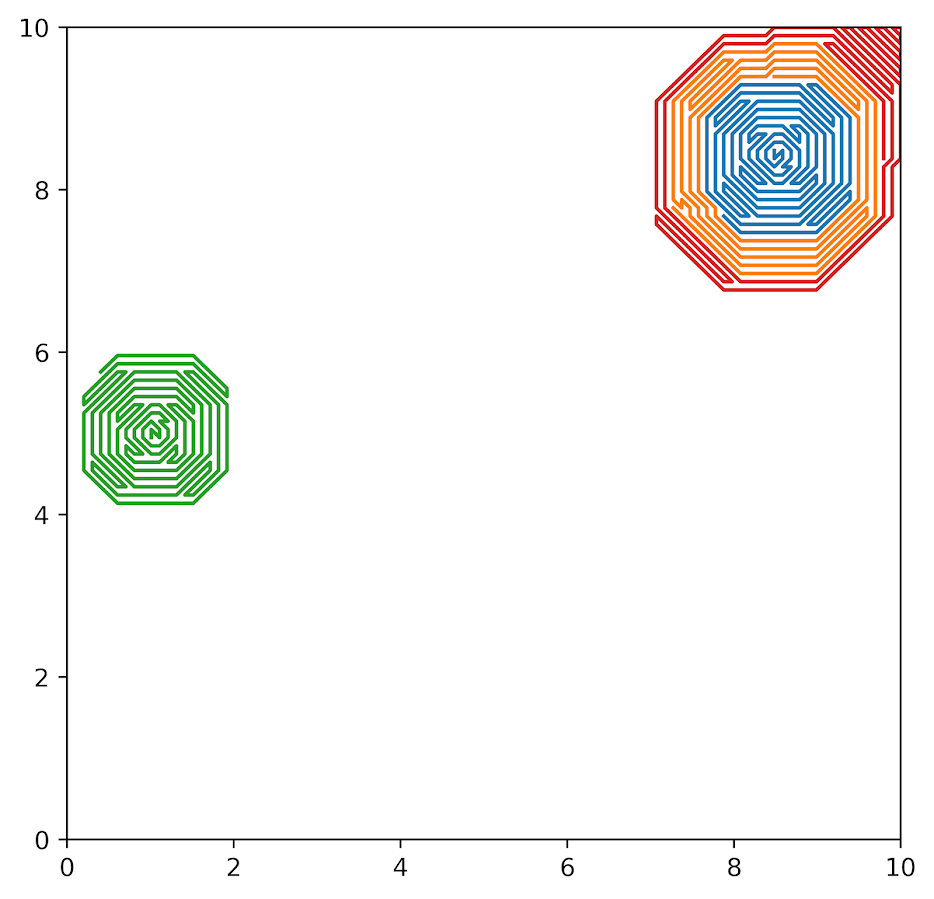
I tried out a greedy algorithm to solve the problem (pick the highest hump, march like an ant around until you have covered your max tour, and then start again). But this was not good either. But it generated some interesting accidental art. So here is my greedy approach to pick four tours in which they can traverse 300 grid cells, and here it says better to ignore the bottom hotspot and spread around your effort in the other two areas:
I know this is pretty sup-optimal though, as you can continue to generate more tours through this approach and eventually find better ones.
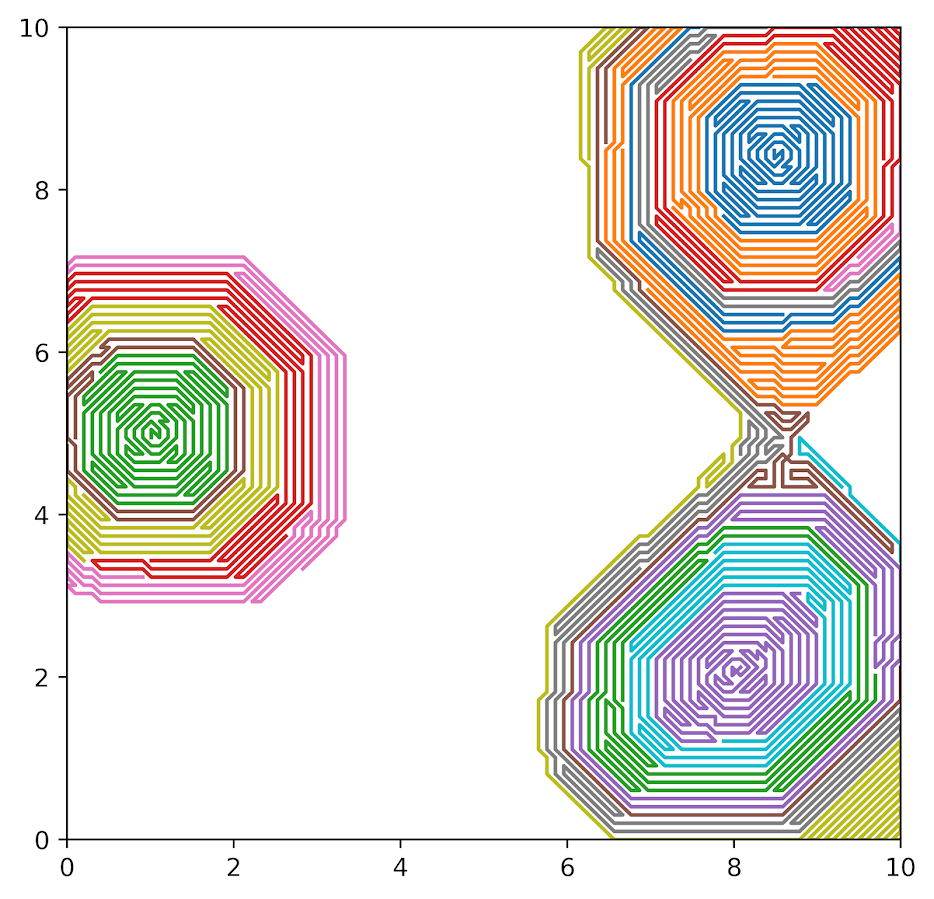
This is going to bug me forever now, but posting a blog to move on. So if you know of a solution please fill me in!


Jon
/ December 20, 2020This is a great use case for reinforcement learning. Actions: up, down, left, right. With reward function proportional to maximizing gathered density. Also easy to generate random training boards. Give Open gym or such a try!
apwheele
/ December 21, 2020Are you familiar with better examples to this situation? Cartpole and Mario are hard for me to translate to here! (In particular I have multi-agents that should not be redundant.)
So agree RL seems like a good idea, I am not sure how to set up the problem though to accomplish that. I was looking at genetic algorithms as well, e.g. https://deap.readthedocs.io/en/master/examples/gp_ant.html, but that is very similar to my greedy one here.
Jon
/ December 21, 2020Agreed. While I appreciate the RL theories — the base examples and frameworks are a pain. You can probably adapt a Maze solving setup via https://medium.com/analytics-vidhya/introduction-to-reinforcement-learning-q-learning-by-maze-solving-example-c34039019317 or https://www.reddit.com/r/Python/comments/eujad1/i_made_a_maze_solving_ai_using_reinforcement. The ML models would be able to adapt much better to different search layouts