
I was nerdsniped a bit by this paper, Targeting Knife-Enabled Homicides For Preventive Policing: A Stratified Resource Allocation Model by Vincent Hariman and Larry Sherman (HS from here on).
It in, HS attempt to define a touring schedule based on knife crime risk at the lower super output area in London. So here are the identified high risk areas:
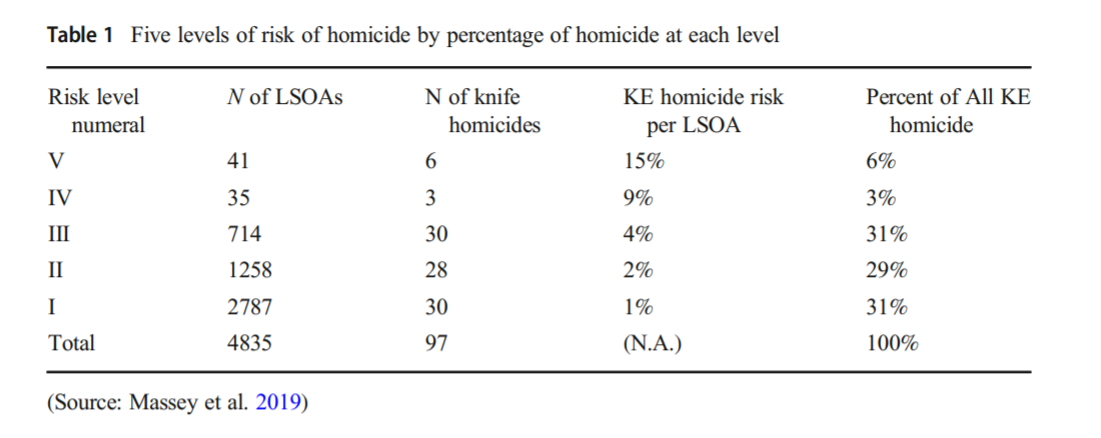
And here are HS’s suggested hot spot tours schedule.
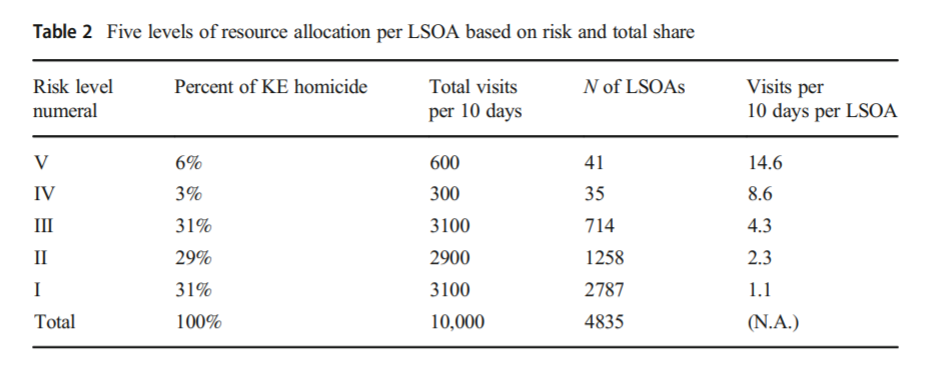
This is ad-hoc, but an admirable attempt to figure out a reasonable schedule. As you can see in their tables, the ‘high’ knife crime risk areas still only have a handful of homicides, so if reducing homicides is the objective, this program is a bit dead in the water (I’ve written about the lack of predictive ability of the model here).
I don’t think defining tours to visit everywhere makes sense, but I do think a somewhat smaller in scope question, how to figure out geographically informed tours for hot spot areas does. So instead of the single grid cell target ala PredPol, pick out multiple areas to visit for hot spots. (I don’t imagine the 41 LSOA areas are geographically contiguous either, e.g. it would make more sense to pick a tour for areas connected than for areas very far apart.)
Officers don’t tend to like single tiny areas either really, and I think it makes more sense to widen the scope a bit. So here is my attempt to figure those reasonable tours out.
Defining the Problem
The way I think about that problem is like this, look at the hypothetical diagram below. We have two choices for the hot spot location we are targeting, where the crime counts for locations are noted in the text label.
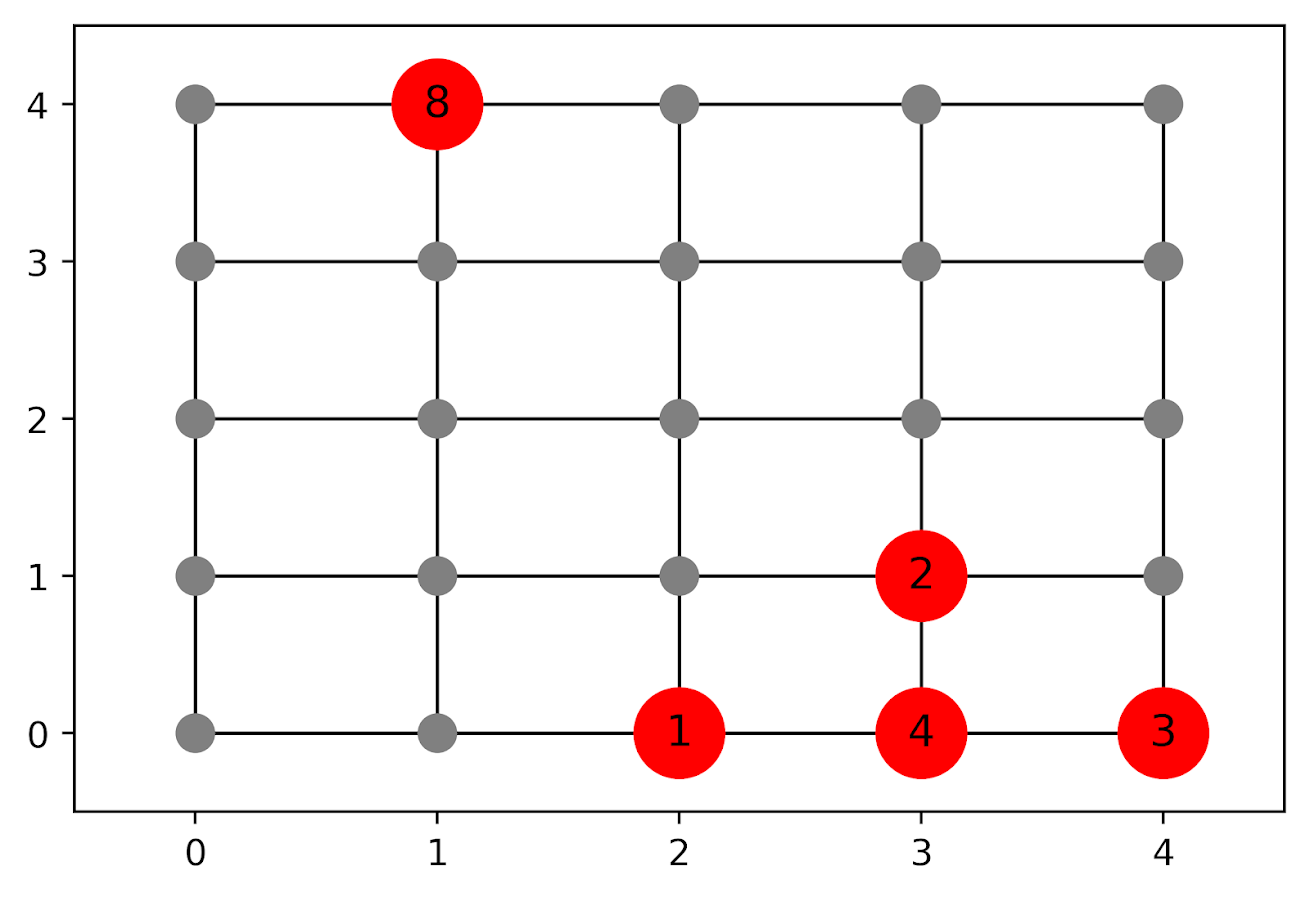
In the select the top hot spot (e.g. PredPol) approach, you would select the singlet grid cell in the top left, it is the highest intensity. We have another choice though, the more spread out hot spot in the lower right. Even though it is a lower density, it ends up capturing more crime overall.
I subsequently formulated an integer linear program to try to tackle the problem of finding good sub-tours through the graph that cumulatively capture more crime. So with the above graph, if I select two subtours, I get the results as (where nodes are identified by their (x,y) position):
['Begin', (1, 4), 'End']['Begin', (4, 0), (4, 1), (3, 1), (3, 0), (2, 0), 'End']
So it can select singlet areas if they are islands (the (1,4) area in the top left), but will grow to wind through areas. Also note that the way I have programmed this network, it doesn’t skip the zero area (4,1) (it needs to go through at least one in the bottom right unless it doubles back on itself).
I will explain the meaning of the begin and end nodes below in my description of the linear program. It ends up being sort of a mash-up of traveling salesman type vehicle routing and min cost max flow type problems.
The Linear Program
The way I think about this problem formulation is like this: we have a directed graph, in which you can say, OK I start from location A, then can go to B, than go to C. In my set of decision variables, I have choices that look like this, where the first subscript denotes the from node, and the second subscript denotes the to node.
D_ab := node a -> node b
D_bc := node b -> node cetc. In our subsequent linear program, the destination node is the node that we calculate our cumulative crime density statistics. So if node B had 10 crimes and 0.1 square kilometers, we would have a density of 100 crimes per square kilometer.
Now to make this formulation work, we need to add in a set of special nodes into our usual location network. These nodes I call ‘Begin’ and ‘End’ nodes (you may also call them source/sink nodes though). The begin nodes all look like this:
D_{begin},a
D_{begin},b
D_{begin},cSo you do that for every node in your network. Then you have End nodes as well, e.g.
D_a,{end}
D_b,{end}
D_c,{end}In this formulation, since we are only concerned about the crime stats for the to node, not the from node, the Begin nodes just inherit the crime density stats from the original node data. For the end nodes though, you just set their objective value stats to zero (they are only relevant to define the constraints).
Now here is my linear program formulation:
Maximize
Sum [ D_ij ( CrimeDensity_j - DensityPenalty_j ) ]
Subject To:
1. Sum( D_in for each neighbor of n ) <= 1,
for each original node n
2. Sum( D_in for each neighbor of n ) = Sum( D_ni for each neighbor of n ),
for each original node n
3. Sum( D_bi for each begin node ) = k routes
4. Sum( D_ie for each end node ) = k routes
5. Sum( D_ij + D_ji ) <= 1, for each unique i,j pair
6. D_ij is an element of {0,1}Constraint 1 is a flow constraint. If a node has an incoming edge set to one, it cannot have any other incoming edge set to one (so a location can only be chosen once).
Constraint 2 is a constraint that says if an incoming node is selected, one of the outgoing edges needs to be selected.
Constraints 3 & 4 determine the number of k tours/routes to choose in the end. Since the begin/end nodes are special we have k routes going out of the begin nodes, and k routes going into the end nodes.
With just these constraints, you can still get micro-cycles I found. So something like, X -> Z -> X. Constraint 5 (for only the undirected edges) prevents this from happening.
Constraint 6 is just setting the decision variables to binary 0/1. So it is a mixed integer linear program.
The final thing to note is the objective function, I have CrimeDensity_j - DensityPenalty_j, so what exactly is DensityPenalty? This is a value that penalizes visiting areas that are below this threshold. Basically the way that this works is that, the density penalty sets an approximate threshold for the minimum density a tour should contain.
I suggest a default of a predictive accuracy index of 10. Where do I get 10 you ask? Weisburd’s law of crime concentration suggests 5% of the areas should contain 50% of the crime, which is a PAI of 0.5/0.05 = 10. In my example with DC data then I just calculate the actual density of crime per unit area that corresponds to a PAI of 10.
You can adjust this though, if you prefer smaller tours of higher crime density you would up the value. If you prefer longer tours decrease it.
This is the best way I could figure out how to trade off the idea of spreading out the targeted hot spot vs selecting the best areas. If you spread out you will ultimately have a lower density. This turns it into a soft objective penalty to try to keep the selected tours at a particular density threshold (and will scoop up better tours if they are available). For awhile I tried to figure out if I could maximize the PAI metric, but it is the case with larger areas the PAI will always go down, so you need to define the objective some other way.
This formulation I only consider linked nodes (unlike the usual traveling salesman in which it is a completely linked distance graph). That makes it much more manageable. In this formulation, if you have N as the number of nodes/areas, and E is the number of directed edges between those areas, we will then have:
2*N + Edecision variables2 + 2*N + E/2constraints
Generally if you are doing directly connected areas in geographic networks (i.e. contiguity connections), you will have less than 8 (typically more like an average of 6) neighbors per each area. So in the case of the 4k London lower super output areas, if I chose tours I would guess it would end up being fewer than 2*4,000 + 8*4,000 = 40,000 decision variables, and then fewer than that constraints.
Since that is puny (and I would suggest doing this at a smaller geographic resolution) I tested it out on a harder network. I used the data from my dissertation, a network of 21,506 street units (both street segments and intersections) in Washington, D.C. The contiguity I use for these micro units is based on the Voronoi tessellation, so tends to have more neighbors than you would with a strictly road based network connectivity. Still in the end it ends up being a shade fewer than 200k decision variables and 110k constraints. So is a better test for in the wild whether the problem can be feasibly solved I think.
Example with DC Data
Here I have posted the python code and data used for this analysis, I end up having a nice function that you just submit your network with the appropriate attributes and out pops the different tours.
So I end up doing examples of 4 and 8 subtours based on 2011 violent UCR crime data (agg assaults, robberies, and homicides, no rapes in the public data). I use for the penalty that PAI = 10 threshold, so it should limit tours to approximately that value. It only ends up taking 2 minutes for the model to converge for the 4 tours and less than 2.5 minutes for the 8 tours on my desktop. So it should be not a big problem to up the decision variables to more sub-areas and still be solvable in real life applications.
The area estimates are in square meters, hence the high numbers. But on the right you can see that each sub-tour has a PAI above 10.
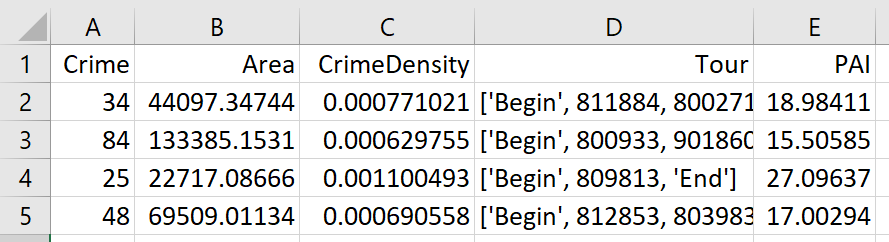
Here is an interactive map for you to zoom into each 4 subtour example. Below is a screenshot of one of the subtours. You can see that since I have defined my connected areas in terms of Voronoi tessalations, they don’t exactly follow the street network.
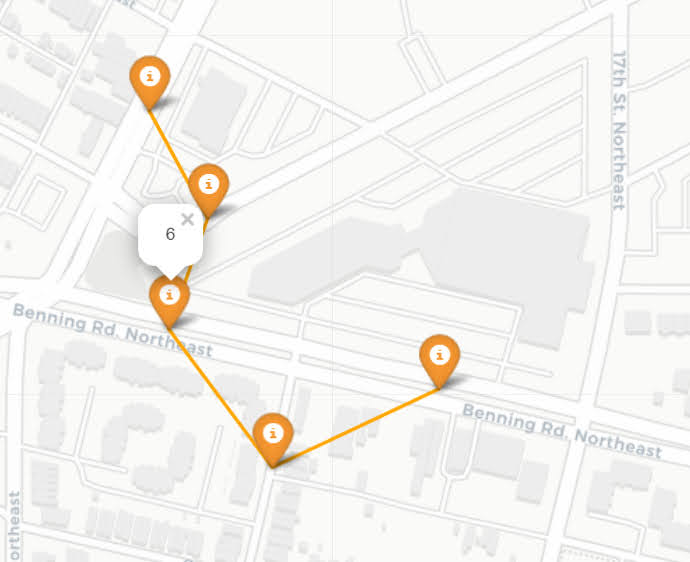
For the 8 tour example, it ends up returning several zero tours, so it is not possible in this data to generate 8 sub-tours that meet that PAI >= 10 threshold.

You can see that it ends up being the tours have higher PAI values, but lower overall crime counts.
You may think, why does it not pick at least singlet areas with at least one crime? It ends up being that I weight areas here by their area (this formulation would be better with grid cells of equal area, so my objective function is technically Sum [ D_ij * w_j *( CrimeDensity_j - DensityPenalty_j ) ], where w_j is the percent of the total area (so the denominator in the PAI calculation). So it ends up picking areas that are the tiniest areas, as they result in the smallest penalty to the objective function (w_j is tiny). I think this is OK though in the end – I rather know that some of the tours are worthless.
You can also see I get one subtour that is just under the PAI 10 threshold. Again possible here, but should be only slightly below in the worst case scenario. The way the objective function works is that it is pretty tricky to pick out subtours below that PAI value but still have a positive contribution to the overall objective function.
Future Directions
The main thing I wish I could do with the current algorithm (but can’t the way the linear program is set up), is to have minimum and maximum tour area/length constraints. I think I can maybe do this by adapting this code (I’m not sure how to do the penalties/objectives though). So if others have ideas let me know!
I admit that this may be overkill, and maybe just doing more typical crime clustering algorithms may be sufficient. E.g. doing DBSCAN hot spots like I did here.
But this is my best attempt shake at the problem for now!


2 Comments