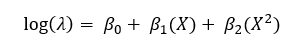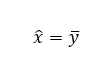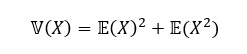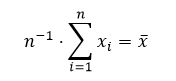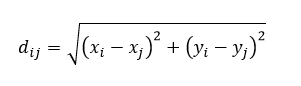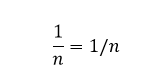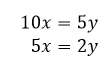I was recently introduced to the work of Jean-luc Doumont via Robert Kosara. So I picked up his book, Trees, maps, and theorems: Effective Communication for rational minds, and it does not disappoint.

In a nutshell, if you have read Tufte’s Visual display of quantitative information and you like it, you will like Doumont’s book as well. He persists in the same minimalist ideal as Tufte, but has advice not just about statistical graphics, but about all aspects of scientific communication; writing, presentations, and even email.
Doumont’s chapter on effective graphical displays is mainly a brief overview of Tufte’s main points for statistical graphics (also he gives some advice on pictures and icons), but otherwise the book has quite a bit of new advice. Here is a quick sampling of some of the points that most resonated with me:
The rule of three: It is very difficult to maintain any more than three items in our short term memory. While some people use the magic number 7 rule, Doumont notes this is clearly the upper limit. Doumont’s suggestion of using three (such as for subheadings in a document, or bullet points in a powerpoint presentation) also coincides with Howard Wainer’s suggestion to limit the number of significant digits in tables to three as well.
For oral presentations with slides, he suggests printing out your slides 6 to a page on a standard letter size paper. If you have a hard time reading them, the font is too small. I’m not sure if this fits inline with my suggestions for font sizes, it will take some more investigation on my part. Another piece of advice for oral presentations is that you can’t read text on slides and listen to the presenter at the same time. Those two inputs compete in our brain, as opposed to images and talking at the same time. Doumont gives the same advice as Tufte (prepare a handout), but I don’t think this is a good idea. (The handout can be distracting.) If you need people to read text, just take a break and get a sip of water. Otherwise make the text as minimal as possible.
My only real point of contention is that Doumont makes the mistake in talking about graphics that one only needs two points labeled on axes. This is not true in general, you need three. Imagine I gave you an axis:
2--?--8For a linear scale, the missing point would be 5, but for a logarithmic scale (in base 2) the missing point would be 4. I figured this is worth pointing out as I recently reviewed a paper where a legend for a raster image (pretty sure ArcGIS was the culprit) only had the end points labeled.
Doumont also has a bunch of advice about writing that I will need to periodically reread. In general one point is that the first sentence of either a section (or paragraph) should be declarative as to the point of that section. Sometimes folks lead with fluff that is only revealed to be related to the material later on in the section.
My writing and work will definitely not live up to Doumont’s standard, but it is a goal I believe scientists should strive for.