
This is just a quick blog post. A crime analyst friend the other day posed a network problem to me. They had a social network in which they had particular individuals of interest, and wanted to show just a subset of that graph that connected those key individuals. The motivation was for plotting – if you show the entire hairball it can become really difficult to uncover any relationships.
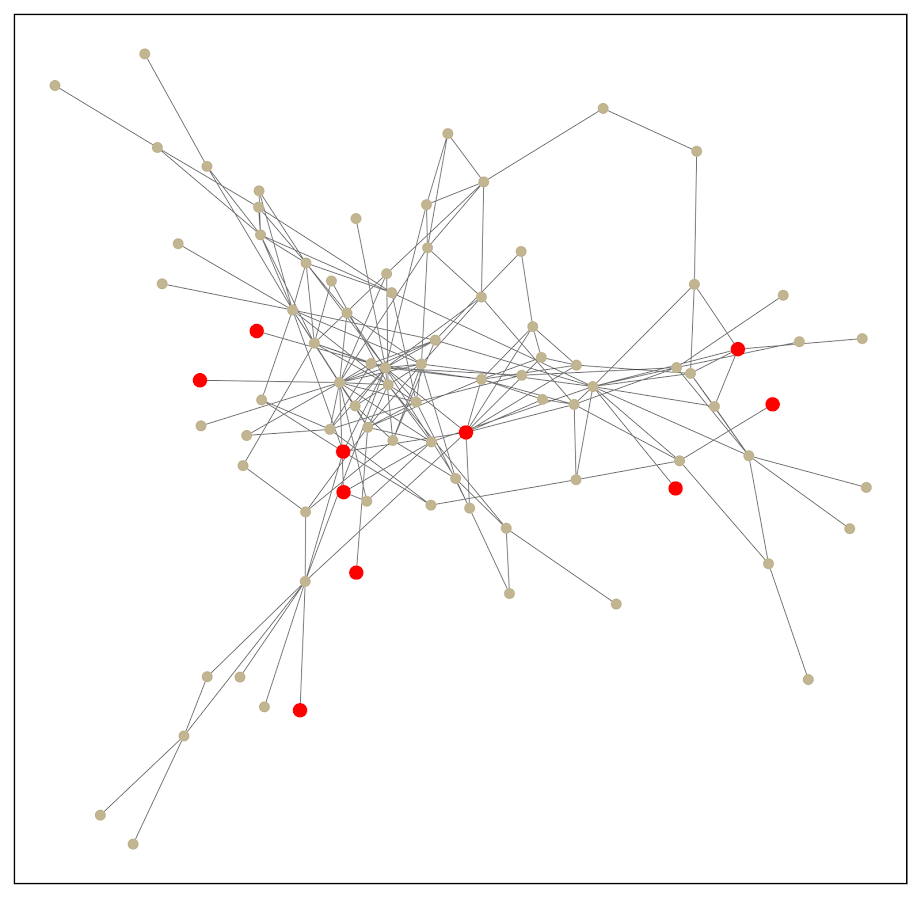
Here is an example gang network from this paper. I randomly chose 10 nodes to highlight (larger red circles), and you can see it is quite hairy. You often want to label the nodes for these types of graphs, but that becomes impossible with so many intertwined nodes.
One solution to select out a subgraph of the connected bits is to use a Steiner tree. Here is that graph after running the approximate Steiner tree algorithm in networkx (in python).
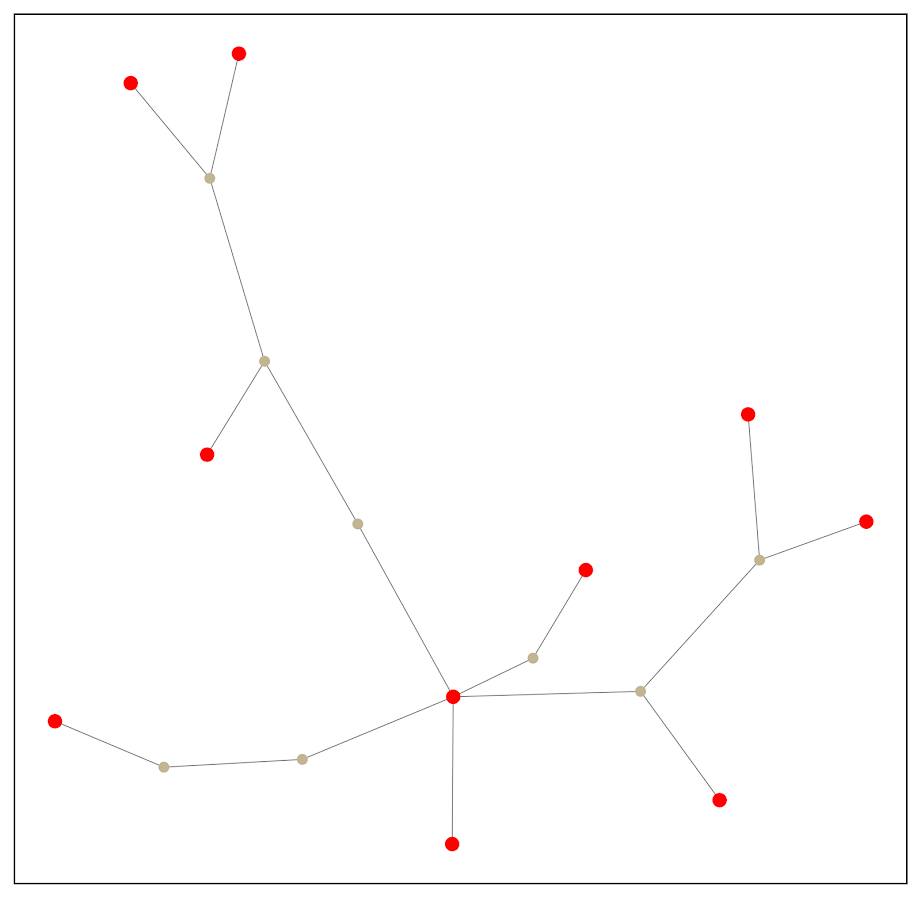
Much simpler! And much more space to put additional labels.
I’ve posted the code and data to replicate here. Initially I debated on solving this via setting up the problem as a min-cost-flow, where one of the highlighted nodes had the supply, and the other highlighted nodes had the demand. But this approximate algorithm in my few tests looks really good in selecting tiny subsets, so not much need.
A few things to note about this. It is likely for many dense networks there will be many alternative subsets that are the same size, but different nodes (e.g. you can swap out a node and have the same looking network). A better approach to see connections between interesting nodes may be a betweenness centrality metric, where you only consider the flows between the highlighted nodes.
A partial solution to that problem is to add nodes/edges back in after the Steiner tree subset. Here is an example where I add back in all first degree nodes to the red nodes of interest:
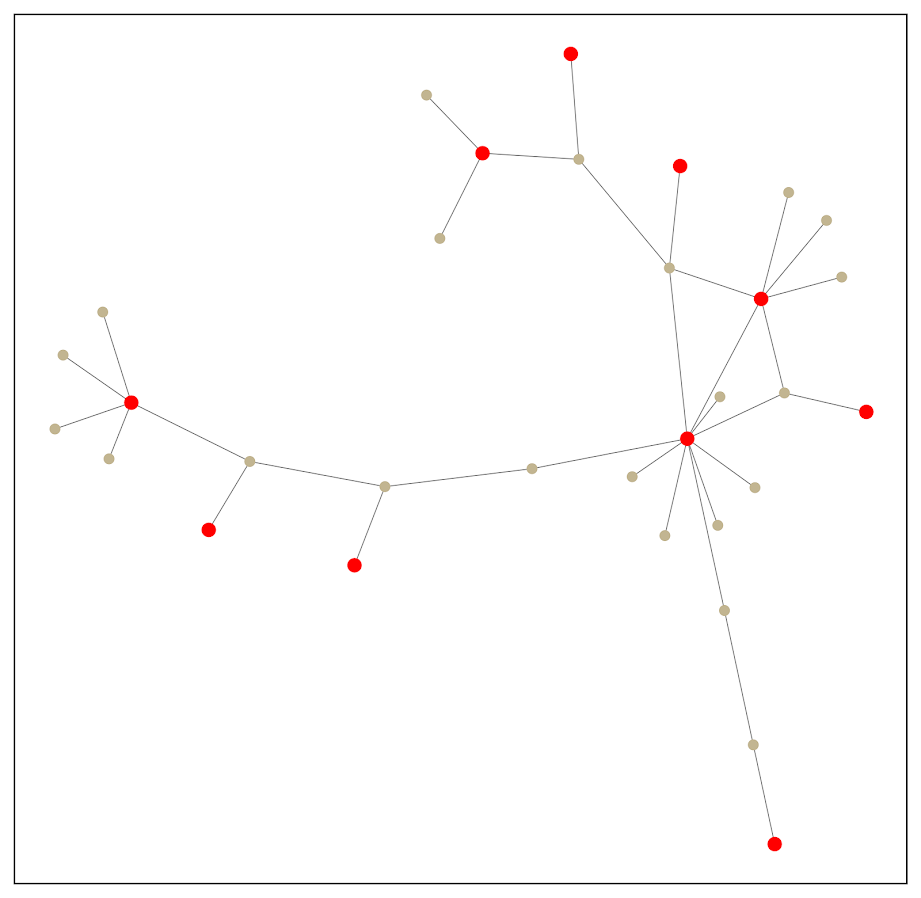
So it is still a tiny enough network to plot. This just provides a way to identify higher order nodes of interest that aren’t directly connected to those red nodes.

