
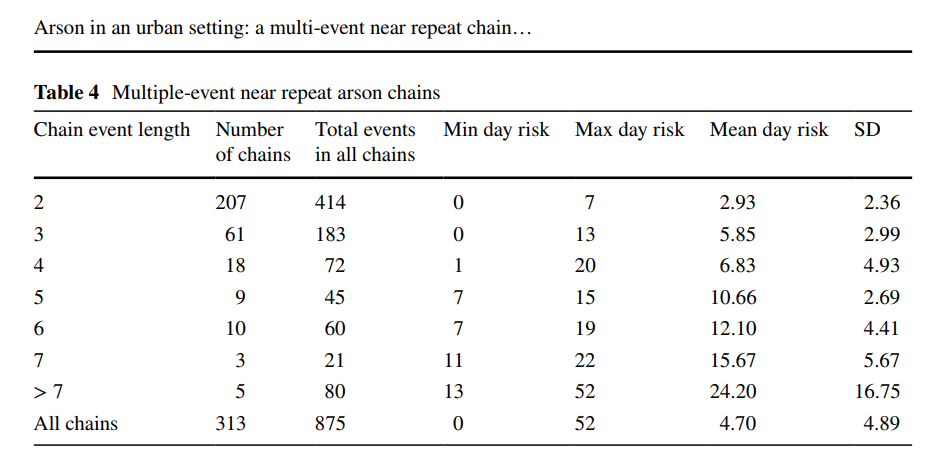
One thing several studies that examine near-repeat patterns have looked at is the distribution of the string of near-repeats. So near-repeats sometimes result in only 2 cases connected, sometimes 3, sometimes 4, etc. Here is an example from a recent work on arsons (Turchan et al., 2018):
Cory Haberman and Jerry Ratcliffe were the first I noticed to do this in this paper (Jerry’s near-repeat calculator has the option to export the strings). It is also a similar idea to what Davies and Marchione did in this paper.
Looking at these strings of events has clear utility for crime analysts, as they have a high probability of being linked to the same offender(s). Building off of some prior work, I wrote some python code to see what the distribution of these strings would look like when you randomly permuted the times in the data (which is the same approach used to estimate the intervals in the near repeat calculator). Here is the data and code, which is an analysis of 14,184 thefts from motor vehicles in Dallas that occurred in 2015.
So first I breakdown the total number of near repeat strings according to within 1000 feet and 7 days of each other. I then conduct 99 random permutations to see how many strings might happen by chance even if there is no near-repeat phenomenon. Some near-repeats can simply happen by chance, especially in places where crime is more prevalent. A length of string 1 in the table means it is not a near repeat, and 10+ means the string has 10 or more events in it. The numbers are the number of chains (in the Turchan article parlance), so 1,384 2-length chains means it includes 2,768 crime events.
If you compare the observed to the bounds in the table, you can see there are fewer isolates (1 length) in the observed than permutation distribution, and more 2 and 3 string events. After that the higher level strings occur just as frequently in the observed data than in the random data, with the exception of 10+ are fewer, but not by much.

So this provides evidence of the boost hypothesis in this data, albeit many near-repeat strings are still likely to occur just by chance, and the differences are not uber large. A crime analyst may be more interested in the question though "if I have X events in a near-repeat string, should I look into the data more". The idea being that since 2-strings are not that rare it would probably be a waste of an analysts time to dig into all of the two-events. I don’t think this is the perfect way to make that decision, but here is a breakdown of the distribution of strings for the permutated data.

So isolates happen in the random data 86% of the time. 2-strings happen 8.7% of the time, 3-strings 2.6%, etc. Based on this I would recommend that there needs to be at least 3 strings of near-repeat events if you have a low threshold in terms of "should I bother to dig into these events". If you want a high threshold though you may do more like 6+ events in a string.
This again is alittle bit of a slippage, as this is actual if you randomly picked a crime, what is the probability it is in a string of near-repeats of length N. I’m not quite sure of a better way to pose it though. Maybe it is better to think in terms of forecasts (eg given N prior crimes, what is the prob. of an additional near-repeat crime, similar to Piza and Carter). Or maybe in terms of if there are N near-repeats, what is the probability they will be linked to a common person (ala Mike Porter and crime linkage).
Also I should mention some of the cool work Liz Groff and Travis Taniguchi are doing on near-repeat work. I should probably just use their near-repeat code instead of rolling my own.

