
I have a new working paper out, Allocating police resources while limiting racial inequality. In this work I tackle the problem that a hot spots policing strategy likely exacerbates disproportionate minority contact (DMC). This is because of the pretty simple fact that hot spots of crime tend to be in disadvantaged/minority neighborhoods.
Here is a graph illustrating the problem. X axis is the proportion of minorities stopped by the police in 500 by 500 meter grid cells (NYPD data). Y axis is the number of violent crimes over along time period (12 years). So a typical hot spots strategy would choose the top N areas to target (here I do top 20). These are all very high proportion minority areas. So the inevitable extra police contact in those hot spots (in the form of either stops or arrests) will increase DMC.
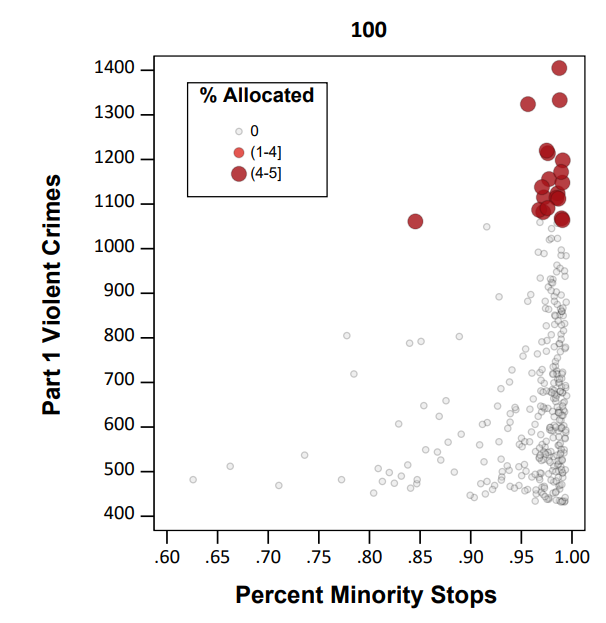
I’d note that the majority of critiques of predictive policing focus on whether reported crime data is biased or not. I think that is a bit of a red herring though, you could use totally objective crime data (say swap out acoustic gun shot sensors with reported crime) and you still have the same problem.
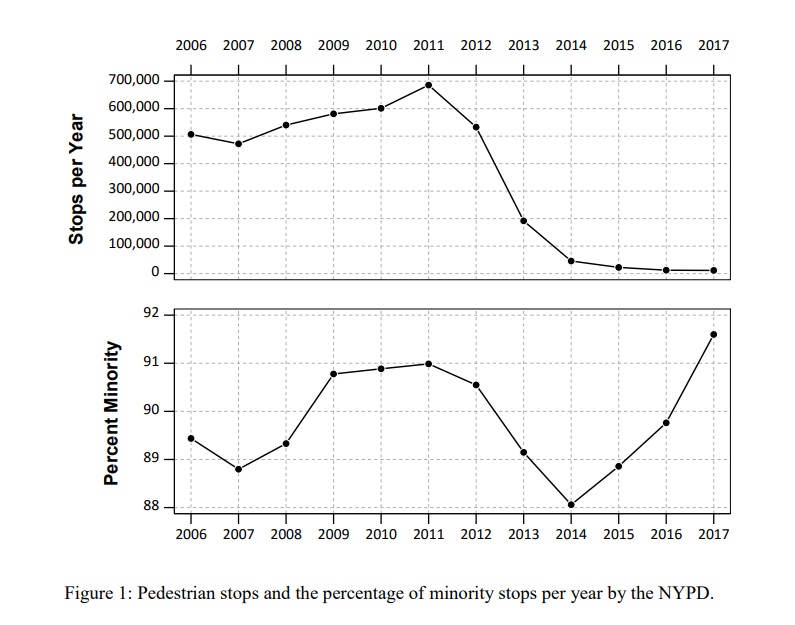
The proportion of stops by the NYPD of minorities has consistently hovered around 90%, so doing a bunch of extra stuff in those hot spots will increase DMC, as those 20 hot spots tend to have 95%+ stops of minorities (with the exception of one location). Also note this 90% has not changed even with the dramatic decrease in stops overall by the NYPD.
So to illustrate my suggested solution here is a simple example. Consider you have a hot spot with predicted 30 crimes vs a hot spot with predicted 28 crimes. Also imagine that the 30 crime hot spot results in around 90% stops of minorities, whereas the 28 crime hot spot only results in around 50% stops of minorities. If you agree reducing DMC is a reasonable goal for the police in-and-of-itself, you may say choosing the 28 crime area is a good idea, even though it is a less efficient choice than the 30 crime hot spot.
I show in the paper how to codify this trade-off into a linear program that says choose X hot spots, but has a constraint based on the expected number of minorities likely to be stopped. Here is an example graph that shows it doesn’t always choose the highest crime areas to meet that racial equity constraint.
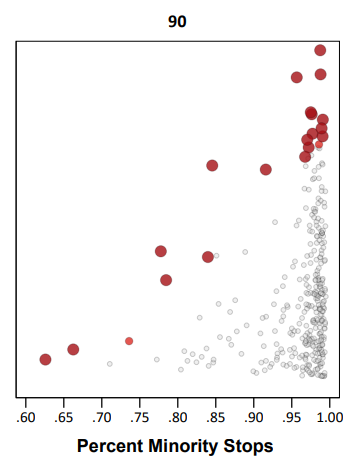
This results in a trade-off of efficiency though. Going back to the original hypothetical, trading off a 28 crime vs 30 crime area is not a big deal. But if the trade off was 3 crimes vs 30 that is a bigger deal. In this example I show that getting to 80% stops of minorities (NYC is around 70% minorities) results in hot spots with around 55% of the crime compared to the no constraint hot spots. So in the hypothetical it would go from 30 crimes to 17 crimes.
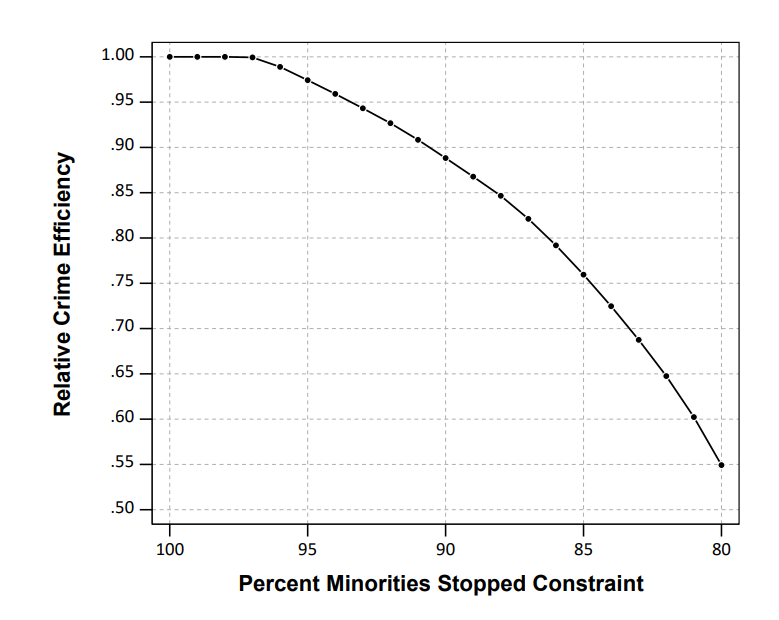
There won’t be a uniform formula to calculate the expected decrease in efficiency, but I think getting to perfect equality with the residential pop. will typically result in similar large decreases in many scenarios. A recent paper by George Mohler and company showed similar fairly steep declines. (That uses a totally different method, but I think will be pretty similar outputs in practice — can tune the penalty factor in a similar way to changing the linear program constraint I think.)
So basically the trade-off to get perfect equity will be steep, but I think the best case scenario is that a PD can say "this predictive policing strategy will not make current levels of DMC worse" by applying this algorithm on-top-of your predictive policing forecasts.
I will be presenting this work at ASC, so stop on by! Feedback always appreciated.

