My paper (with colleagues Jordan Riddell and Cory Haberman), Breaking the chain: How arrests reduce the probability of near repeat crimes, has been published in Criminal Justice Review. If you cannot access the peer reviewed version, always feel free to email and I can send an offprint PDF copy. (For those not familiar, it is totally OK/legal for me to do this!) Or if you don’t want to go to that trouble, I have a pre-print version posted here.
The main idea behind the paper is that crimes often have near-repeat patterns. That is, if you have a car break in on 100 1st St on Monday, the probability you have another car break in at 200 1st St later in the week is higher than typical. This is most often caused by the same person going and committing multiple offenses in a short time period. So a way to prevent that would on its face be to arrest the individual for the initial crime.
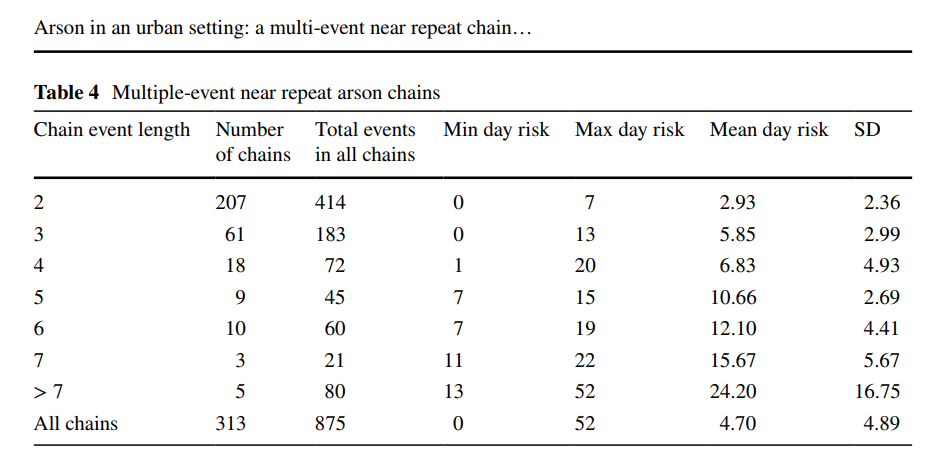
I estimate models showing the reduction in the probability of a near repeat crime if an arrest occurs, based on publicly available Dallas PD data (paper has links to replication code). Because near repeat in space & time is a fuzzy concept, I estimate models showing reductions in near repeats for several different space-time thresholds.
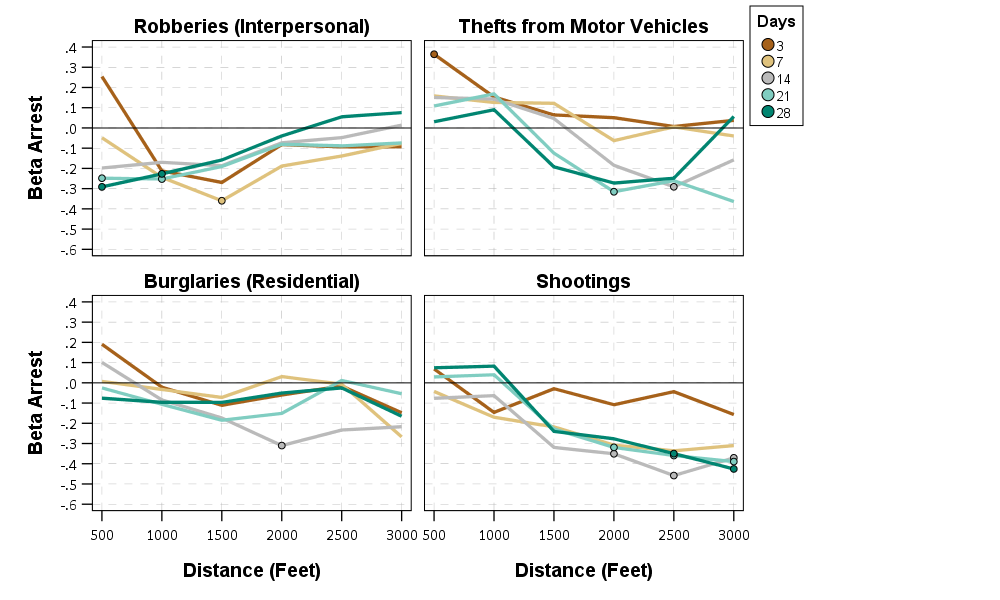
So here the model is Prob[Future Crime = I(time < t & distance < d)] ~ f[Beta*Arrest + sum(B_x*Control_x)] where the f function is a logistic function, and I plot the Beta estimates given different time and space look aheads. Points indicate statistical significance, so you can see they tend to be negative for many different crime and different specifications (with a linear coefficient of around -0.3).
Part of the reason I pursued this is that the majority of criminal justice responses to near repeat patterns in the past were target hardening or traditional police patrol. Target hardening (e.g. when a break in occurs, go to the neighbors and tell them to lock their doors) does not appear to be effective, but traditional patrol does (see the work of Rachel/Robert Santos for example).
It seems to me ways to increase arrest rates for crimes is a natural strategy that is worthwhile to explore for police departments. Easier said than done, but one way may be to prospectively identify incidents that are likely to spawn near repeats and give them higher priority in assigning detectives. In many urban departments, lower level property crimes are never assigned a detective at all.
Open Data and Reproducible Criminology Research
This is part of a special issue put together by Jonathan Grubb and Grant Drawve on spatial approaches to community violence. Jon and Grant specifically asked contributors to discuss a bit about open data standards and replication materials. I repost my thoughts on that here in full:
In reference to reproducibility of the results, we have provided replication materials. This includes the original data sources collated from open sources, as well as python, Stata, and SPSS scripts used to conduct the near-repeat analysis, prepare the data, generate regression models, and graph the results. The Dallas Police Department has provided one of the most comprehensive open sources of crime data among police agencies in the world (Ackerman & Rossmo, 2015; Wheeler et al., 2017), allowing us the ability to conduct this analysis. But it also identifies one particular weakness in the data as well – the inability to match the time stamp of the occurrence of an arrest to when the crime occurred. It is likely the case that open data sources provided by police departments will always need to undergo periodic revision to incorporate more information to better the analytic potential of the data.
For example, much analysis of the arrest and crime relationship relies on either aggregate UCR data (Chamlin et al., 1992), or micro level NIBRS data sources (Roberts, 2007). But both of these data sources lack specific micro level geographic identifiers (such as census tract or addresses of the events), which precludes replicating the near repeat analysis we conduct. If however NIBRS were to incorporate address level information, it would be possible to conduct a wide spread analysis of the micro level deterrence effects of arrests on near repeat crimes across many police jurisdictions. That would allow much broader generalizability of the results, and not be dependent on idiosyncratic open data sources or special relationships between academics and police departments. Although academic & police practitioner relationships are no doubt a good thing (for both police and academics), limiting the ability to conduct analysis of key policing processes to the privileged few is not.
That being said, currently both for academics and police departments there are little to no incentives to provide open data and reproducible code. Police departments have some slight incentives, such as assistance from governmental bodies (or negative conditions for funding conditional on reporting). As academics we have zero incentives to share our code for this manuscript. We do so simply because that is a necessary step to ensure the integrity of scientific research. Relying on the good will of researchers to share replication materials has the same obvious disadvantage that allowing police departments to pick and choose what data to disseminate does – it can be capricious. What a better system to incentivize openness may look like we are not sure, but both academics and police no doubt need to make strides in this area to be more professional and rigorous.