
Hackernews recently shared a story about not using an IDE, and I feel mostly the same way. Hence the title in the post – so my current workflow for when I steal some time to work on my R package ptools my workflow looks like this, using Rterm from the shell:
I don’t have anything against RStudio, I just only have so much room in my brain. Sometimes conversations at work are like a foreign language, “How are we going to test the NiFi script from Hadoop to our Kubernetes environment” or “I can pull the docker image from JFrog, but I run out of room when extracting the image on our sandbox machine. But df says we have plenty of room on all the partitions?”.
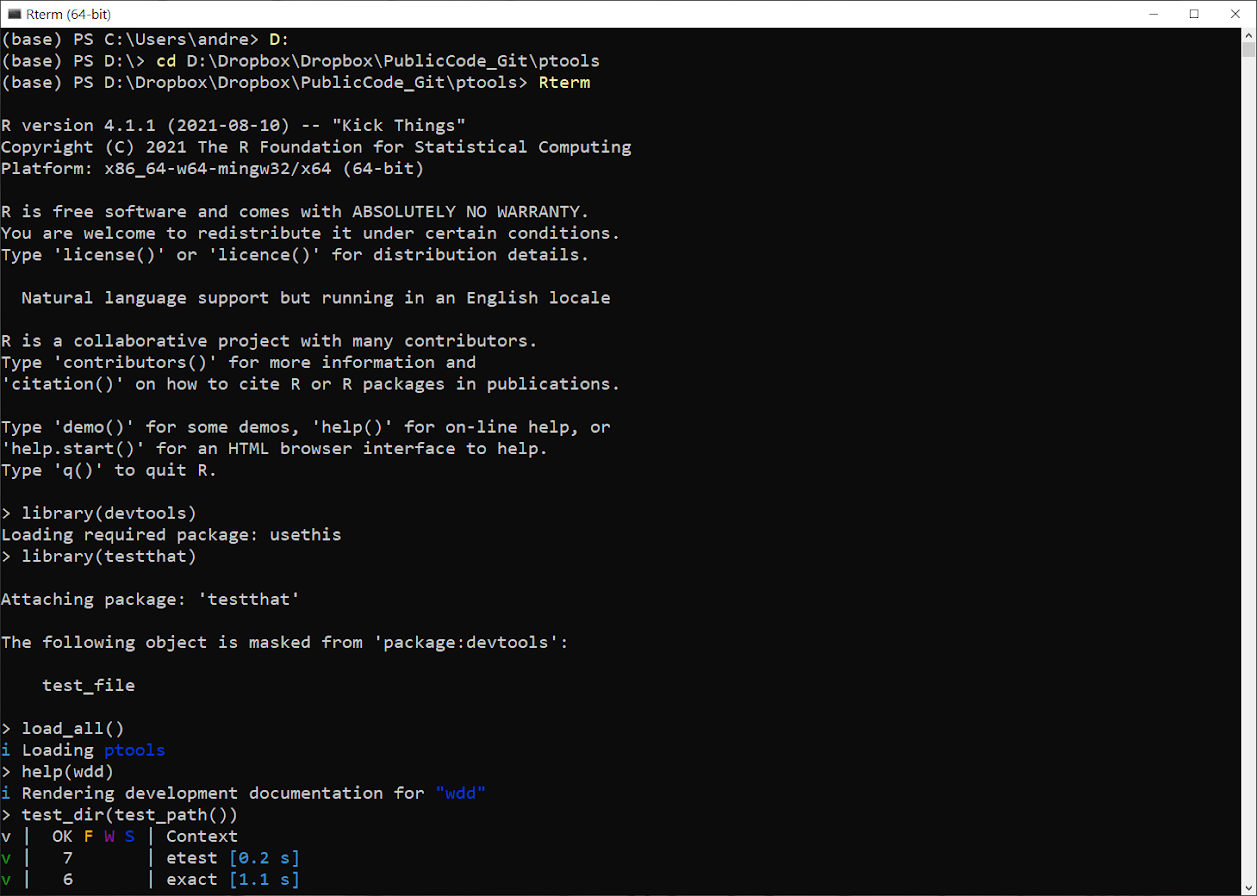
If you notice at the top the (base) in front of the shell, that is because this is within the anaconda shell as well. So if you look at many of my past blog posts (see here for one example), I am just using the snipping tool in windows to take screenshots of the shell output in interactive mode.
I am typically just writing the code in Notepad++ (as well as this blog post) – and it is quite simple to switch between interactive copy this function/code and compiling entire scripts. Here is a screenshot of R unit tests for example.
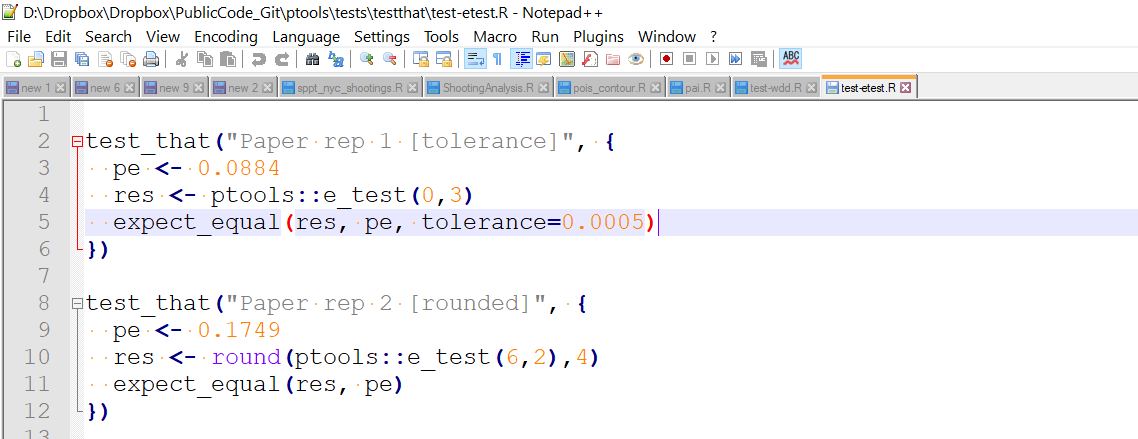
So Notepad++ has some text highlight (for both R and python), and that is nice, but honestly not that necessary. Main thing I use is the selection of brackets to make sure they are balanced. I am sure I am missing out on some nice autocomplete features that would make me more productive, and function hints in Spyder are nice for pandas functions (I mostly use google still though for that when I need it).
I do use VS Code for development work on our headerless virtual machines at work. But that is more to replicate essentially the workflow on Windows with file explorer + Notepad++ + Shell (I am not a vim ninja – what is it esc + wq:, need to look that up everytime). I fucked up one of my git repos the other day using VS Code stuff tools, and I am just using git directly anymore. (Again this means I am the problem, not VS Code!)
Why data science projects fail?
Some more random musings, but the more I get involved and see what projects work and what don’t at work, pretty much all of the failures I have come across are due to what I will call “not modeling the right thing”. That potentially covers a bit, but quite a few are simply not understanding counterfactual reasoning and selection bias.
The modeling part (in terms of actually fitting models) is typically quite easy – you do some simple but slightly theoretically informed feature engineering and feed that info into a machine learning model that is very flexible. But maybe that is the problem, people can easily fool themselves into thinking a model looks good, but because they are modeling the wrong thing it does not result in better decision making.
Even in most of the failures I have seen, selection bias is surmountable (often just requires multiple models or models on different samples of data – reduced form for the win!). So learning how to train/test split the data, and feed your data into XGboost only takes a few classes to learn. How to know the right thing to model though takes a bit more thought.
A secondary part of the failure is not learning how to translate the model outputs into actionable decisions. But the not modeling the right thing is at the start, so makes any downstream decision not work out how you want.

