
At work I am currently working on estimating/forecasting healthcare spending. Similar to work I have done on forecasting person level crime risks (Wheeler et al., 2019), I build the predictive model dataset like this:
CrimeYear2020 PriorCrimeA PriorCrimeB
0 2 3
1 5 0
0 0 0etc. So I flatten people to a single row, and as covariates include prior cumulative crime histories. Most people do this similarly in the healthcare setting, so it looks like:
SpendingYear2020 PriorComorbidA PriorComorbidB
3000 1 2
500 3 0
10000 0 0Or sometimes people do a longitudinal dataset, where it is a spending*year*person panel (see Lauffenburger et al., 2020 for an example). I find this approach annoying for a few reasons though. One, it requires arbitrary temporal binning, which is somewhat problematic in these transaction level databases. We are talking for chronic offenders a few crimes per year is quite high, and ditto in the healthcare setting a few procedures a year can be very costly. So there is not much data to estimate the underlying function over time.
A second aspect I think is bad is that it doesn’t take into account the recency of the patterns. So the variables on the right hand side can be very old or very new. And with transaction level databases it is somewhat difficult to define how to estimate the lookback – do you consider it normalized by time? The VOID paper I mentioned we evaluated the long term scores, but the PD that does that chronic offender system has two scores – one a cumulative history and another a 90 day history to attempt to deal with that issue (again ad-hoc).
One approach to this issue from marketing research I have seen from very similar types of transactions databases are models to estimate Customer Lifetime Value (Fader et al. 2005). These models in the end generate a dataset that looks like this:
Person RecentMonths TotalEvents AveragePurchase
A 3 5 $50
B 1 2 $100
C 9 8 $25TotalEvents should be straightforward, RecentMonths just is a measure of the time since the last purchase, and then you have the average value of the purchases. And using just this data, estimates the probability of any future purchases, as well as projects the total value of the future average purchases. So here I use an example of this approach, using the Wolfgang Philly cohort public data. I am not going into the model more specifically (read some of the Bruce Hardie notes to get a flavor).
I have created some python code to follow along and apply these same customer lifetime value estimates to chronic offender data. Most examples of weighting crime harm apply it to spatial areas (Mitchell, 2019; Wheeler & Reuter, 2021), but you can apply it the same to chronic offender lists (Liggins et al., 2019).
Example Criminal Lifetime Value in Python
First, install the lifetimes python library – Cam’s documentation is excellent and makes the data manipulation/modelling quite simple.
Here I load in the transaction level crime data, e.g. it just have person A, 1/5/1960, 1000, where the 1000 is a crime seriousness index created by Wolfgang. Then the lifetimes package has some simple functions to turn our data into the frequency/recency format.
Note that for these models, you drop the first event in the series. To build a model to do train/test, I also split the data into evens before 1962, and use 1962 as the holdout test period.
import lifetimes as lt
import pandas as pd
# Just the columns from dataset II
# ID, SeriousScore, Date
df = pd.read_csv('PhilData.csv')
df['Date'] = pd.to_datetime(df['Date'])
# Creating the cumulative data
# Having holdout for one year in future
sd = lt.utils.calibration_and_holdout_data(df,'ID','Date',
calibration_period_end='12-31-1961',
observation_period_end='12-31-1962',
freq='M',
monetary_value_col='SeriousScore')
# Only keeping people with 2+ events in prior period
sd = sd[sd['frequency_cal'] > 0].copy()
sd.head()
Recency_cal is how many months since a prior crime (starting in 1/1/1962), frequency is the total number of events (minus 1, so number of repeat events technically), and the monetary_value_cal here is the average of the crime seriousness across all the events. The way this function works, the variables with the subscript _cal are in the training period, and _holdout are events in the 1962 period. For subsequent models I subset out people with at least 2 events total in the modeling.
Now we can fit a model to estimate the predicted number of future crimes a person will commit – so this does not take into account the seriousness of those crimes. The final groupby statement shows the predicted number of crimes vs those actually committed, broken down by number of crimes in the training time period. You can see the model is quite well calibrated over the entire sample.
# fit BG model
bgf = lt.BetaGeoFitter(penalizer_coef=0)
bgf.fit(sd['frequency_cal'],sd['recency_cal'],sd['T_cal'])
# look at fit of BG model
t = 12
sd['pred_events'] = bgf.conditional_expected_number_of_purchases_up_to_time(t, sd['frequency_cal'], sd['recency_cal'],sd['T_cal'])
sd.groupby('frequency_cal',as_index=False)[['frequency_holdout','pred_events']].sum() # reasonable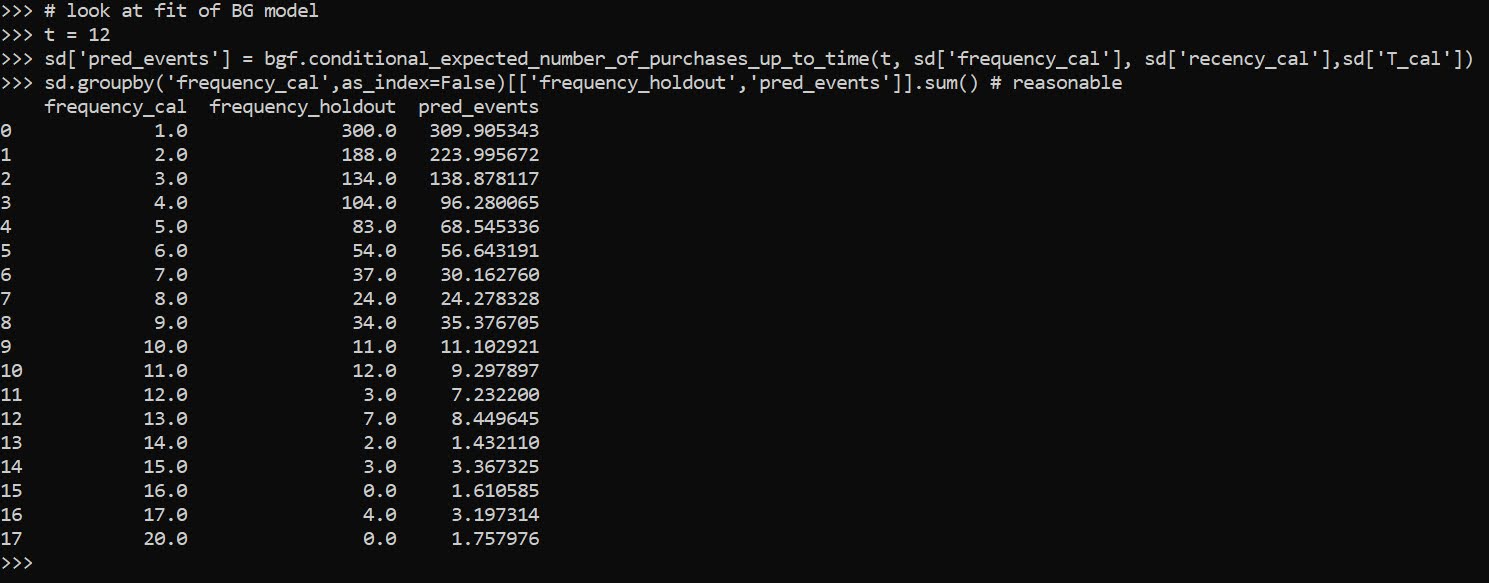
Now we can fit a model to estimate the average crime severity score for an individual as well. Then you can project a future cumulative score for an offender (here over a horizon of 1 year), by multiple the predicted number of events times the estimate of the average severity of the events, what I label as pv here:
# See conditional seriousness
sd['pred_ser'] = ggf.conditional_expected_average_profit(
sd['frequency_cal'],
sd['monetary_value_cal'])
sd['pv'] = sd['pred_ser']*sd['pred_events']
sd['cal_tot_val'] = sd['monetary_value_holdout']*sd['frequency_holdout']
# Not great correlation, around 0.2
vc = ['frequency_holdout','monetary_value_holdout','cal_tot_val','pred_events','pv']
sd[vc].corr()The correlation between pv and the holdout cumulative crime severity cal_tot_val, is not great at 0.26. But lets look at this relative to the more typical approach analysts will do, simply rank prior offenders based on either total number of events or the crime seriousness:
# Lets look at this method via just ranking prior
# seriousness or frequency
sd['rank_freq'] = sd['frequency_cal'].rank(method='first',ascending=True)
sd['rank_seri'] = (sd['monetary_value_cal']*sd['frequency_cal']).rank(method='first',ascending=True)
vc += ['rank_freq','rank_seri']
sd[vc].corr()[vc[-3:]]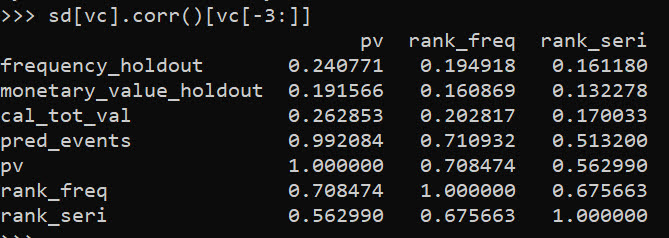
So we can see that pv outperforms ranking based on total crimes (rank_freq), or ranking based on the cumulative serious score for offenders (rank_seri) in terms of the correlation for either the total number of future events or the cumulative crime harm.
If we look at capture rates, e.g. pretend we highlight the top 50 chronic offenders for intervention, we can see the criminal lifetime value pv estimate outperforms either simple ranking scheme by quite a bit:
# Look at capture rates by ranking
topn = 50
res_summ = []
for v in vc[-3:]:
rank = sd[v].rank(method='first',ascending=False)
locv = sd[rank <= topn].copy()
tot_crimes = locv['frequency_holdout'].sum()
tot_ser = locv['cal_tot_val'].sum()
res_summ.append( [v,tot_crimes,tot_ser,topn] )
res_df = pd.DataFrame(res_summ,columns=['Var','TotCrimes','TotSer','TotN'])
res_df
In terms of the seriousness projection, it is reasonably well calibrated over the entire sample, but has a very tiny variance – it basically just predicts the average crime serious score over the sample and assigns that as the prediction going forward:
# Cumulative stats over sample reasonable
# variance much too small
sd[['cal_tot_val','pv']].describe()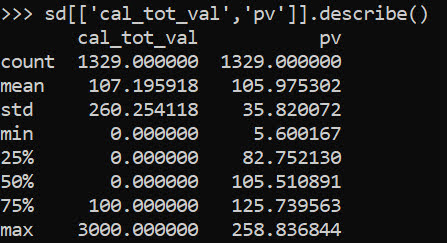
So what this means is that if say Chicago READI wanted to do estimates to reasonably justify the max dollar cost for their program (over a large number of individuals) that would be reasonable. And this is how most marketing people use this info, average benefits of retaining a customer.
For individual projections though, e.g. I think OffenderB will generate between [low,high] crime harm in the next year, this is not quite up to par. I am hoping though to pursue these models further, maybe either in a machine learning/regression framework to estimate the parameters directly, or to use mixture models in an equivalent way that marketers use “segmentation” to identify different types of customers. Knowing the different way people have formulated models though is very helpful to be able to build a machine learning framework, which you can incorporate covariates.
References
- Fader, P. S., Hardie, B. G., & Lee, K. L. (2005). “Counting your customers” the easy way: An alternative to the Pareto/NBD model. Marketing Science, 24(2), 275-284.
- Lauffenburger, J. C., Mahesri, M., & Choudhry, N. K. (2020). Use of data-driven methods to predict long-term patterns of health care spending for Medicare patients. JAMA network open, 3(10), e2020291.
- Liggins, A., Ratcliffe, J. H., & Bland, M. (2019). Targeting the most harmful offenders for an English police agency: Continuity and change of membership in the “Felonious Few”. Cambridge Journal of Evidence-Based Policing, 3(3), 80-96.
- Mitchell, R. J. (2019). The usefulness of a crime harm index: analyzing the Sacramento Hot Spot Experiment using the California Crime Harm Index (CA-CHI). Journal of Experimental Criminology, 15(1), 103-113.
- Wheeler, A. P., & Reuter, S. (2021). Redrawing hot spots of crime in Dallas, Texas. Police Quarterly, 24(2), 159-184.
- Wheeler, A. P., Worden, R. E., & Silver, J. R. (2019). The accuracy of the violent offender identification directive tool to predict future gun violence. Criminal Justice and Behavior, 46(5), 770-788.
- Wolfgang, Marvin E., Figlio, Robert M., and Sellin, Thorsten. Delinquency in a Birth Cohort in Philadelphia, Pennsylvania, 1945-1963. Inter-university Consortium for Political and Social Research (distributor), 2006-01-12.

