I’ve updated the roadblocks in Buffalo manuscript due to a rejection and subsequent critiques. So be prepared about my complaints of the peer-review!
I’ve posted the original manuscript, reviews and a line-by-line response here. This was reviewed at Policing: An International Journal of Police Strategies & Management. I should probably always do this, but I felt compelled to post this review by the comically negative reviewer 1 (worthy of an article on The Allium).
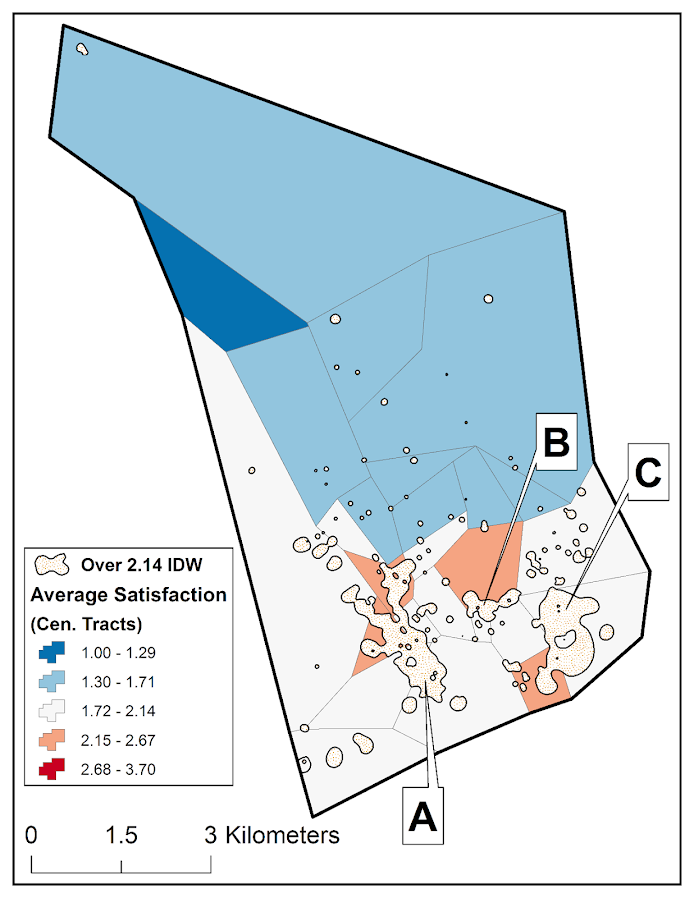
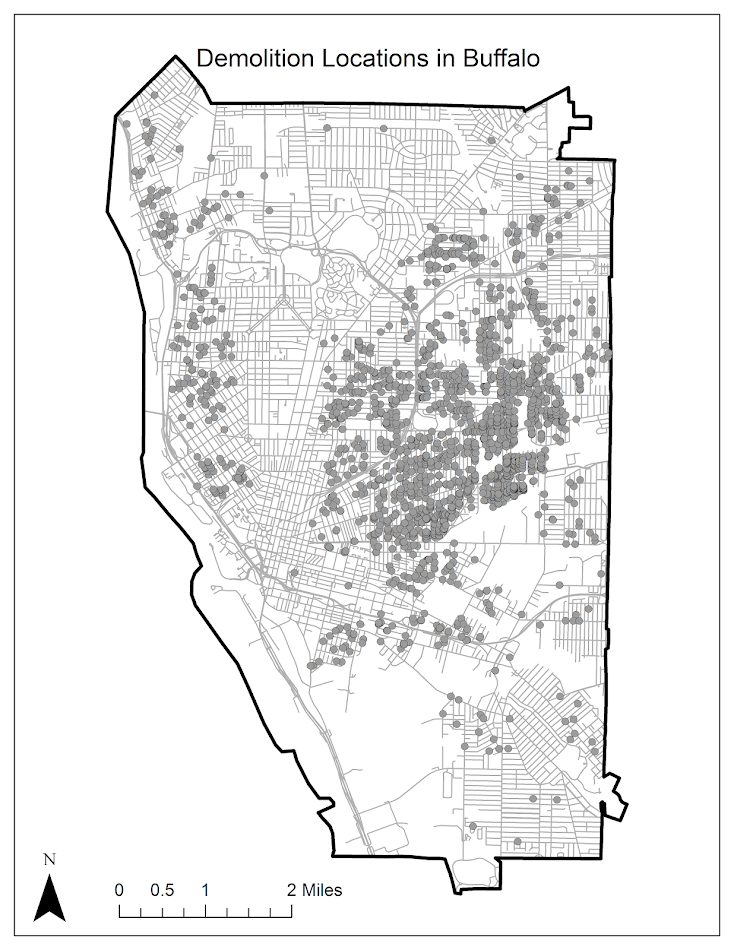
The comment of reviewer 1 that really prompted me to even bother writing a response was the critique of the maps. I spend alot of time on making my figures nice and understandable. I’m all ears if you think they can be improved, but best be prepared for my response if you critique something silly.
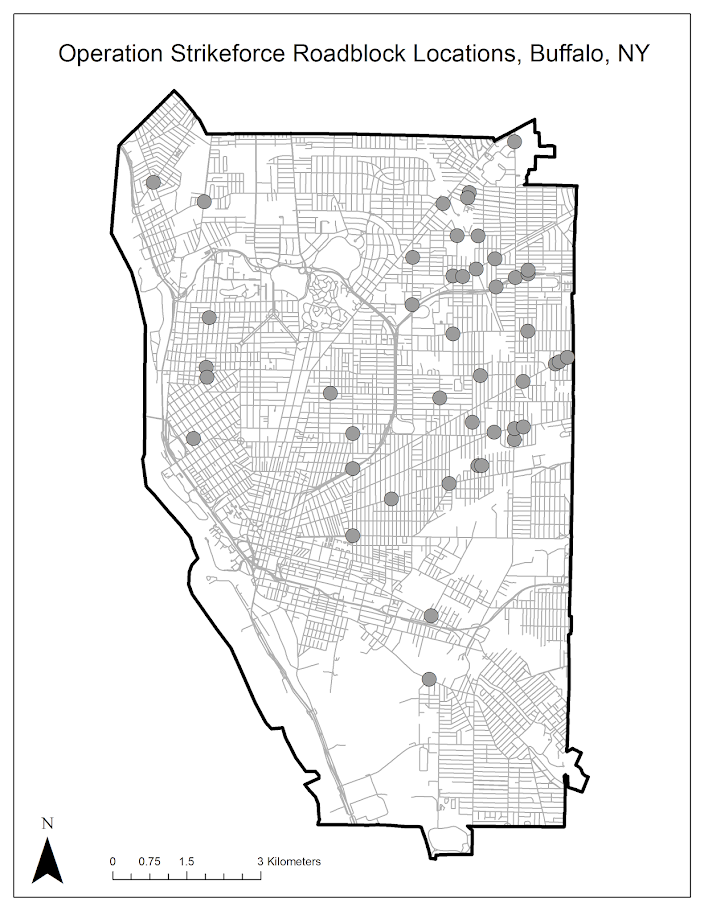
So here is the figure in question – spot anything wrong?
The reviewer stated it did not have legend, so it does not meet "GIS standards". The lack of a legend is intentional. When you open google maps do they have a legend? Nope! It is a positive thing to make a graphic simple enough that it does not need a legend. This particular map only has three elements: the outline of Buffalo, the streets, and the points where the roadblocks took place. There is no need to make a little box illustrating these three things – they are obvious. The title is sufficient to know what you are looking at.
Reviewer 2 was more even keeled. The only thing I would consider a large problem in their review was they did not think we matched comparable control areas. If true I agree it is a big deal, but I’m not quite sure why they thought this (sure balance wasn’t perfect, but it is pretty close across a dozen variables). I wouldn’t release the paper if I thought the control areas were not reasonable.
Besides arbitrary complaints about the literature review this is probably the most frustrating thing about peer-reviews. Often you will get a list of two dozens complaints, with most being minor and fixable in a sentence (if not entirely arbitrary), but the article will still be rejected. People have different internal thresholds for what is or is not publishable. I’m on the end that even with worts most of the work I review should still be published (or at least the authors given a chance to respond). Of the 10 papers I’ve reviewed, my record is 5 revise-and-resubmits, 4 conditional accepts, and 1 rejection. One of the revise-and-resubmits I gave a pretty large critique of (in that I didn’t think it was possible to improve the research design), but the other 4 would be easily changed to accept after addressing my concerns. So worst case scenario I’ve given the green light to 8/10 of the manuscripts I’ve reviewed.
Many reviewers are at the other end though. Sometimes comically so, in that given the critiques nothing would ever meet their standards. I might call it the golden-cow peer review standard.
Even though both of my manuscripts have been rejected from PSM, I do like their use of a rubric. This experience makes me wonder what if the reviewers did not give a final reject-accept decision – just the editors took the actual comments and made their own decision. Editors do a version of this currently, but some are known to reject if any of the reviewers give a rejection no matter what the reviewers actually say. It would force the editor to use more discretion if the reviewers themselves did not make the final judgement. It also forces reviewers to be more clear in their critiques. If they are superficial the editor will ignore them, whereas the final accept-reject is easy to take into account even if the review does not state any substantive critiques.
I don’t know if I can easily articulate what I think is a big deal and what isn’t though. I am a quant guy, so the two instances I rejected were for model identification in one and for sample selection biases in the other. So things that could not be changed essentially. I haven’t read a manuscript that was so poor I considered it to be unsalvagable in terms of writing. (I will do a content analysis of reviews I’ve recieved sometime, but almost all complaints about the literature review are arbitrary and shouldn’t be used as reasons for rejection.)
Often times I write abunch of notes on the paper manuscript my first read, and then when I go to write up the critique specifically I edit them out. This often catches silly initial comments of mine, as I better understand the manuscript. Examples of silly comments in the reviews of the roadblock paper are claiming I don’t conduct a pre-post analysis (reviewer 1), and asking for things already stated in the manuscript (reviewer 2 asking for how long the roadblocks were and whether they were "high visibility"). While it is always the case things could be explained more clearly, at some point the reviewer(s) needs to be more careful in their reading of the manuscript. I think my motto of "be specific" helps with this. Being generic helps to conceal silly critiques.