Here is just a quick example of making calendar heatmaps in SPSS. My motivation can be seen from similar examples of calendar heatmaps in R and SAS (I’m sure others exist as well). Below is an example taken from this Revo R blog post.
The code involves a macro that can take a date variable, and then calculate the row position the date needs to go in the calendar heatmap (rowM), and also returns a variable for the month and year, which are used in the subsequent plot. It is brief enough I can post it here in its entirety.
*************************************************************************************.
*Example heatmap.
DEFINE !heatmap (!POSITIONAL !TOKENS(1)).
compute month = XDATE.MONTH(!1).
value labels month
1 'Jan.'
2 'Feb.'
3 'Mar.'
4 'Apr.'
5 'May'
6 'Jun.'
7 'Jul.'
8 'Aug.'
9 'Sep.'
10 'Oct.'
11 'Nov.'
12 'Dec.'.
compute weekday = XDATE.WKDAY(!1).
value labels weekday
1 'Sunday'
2 'Monday'
3 'Tuesday'
4 'Wednesday'
5 'Thursday'
6 'Friday'
7 'Saturday'.
*Figure out beginning day of month.
compute #year = XDATE.YEAR(!1).
compute #rowC = XDATE.WKDAY(DATE.MDY(month,1,#year)).
compute #mDay = XDATE.MDAY(!1).
*Now ID which row for the calendar heatmap it belongs to.
compute rowM = TRUNC((#mDay + #rowC - 2)/7) + 1.
value labels rowM
1 'Row 1'
2 'Row 2'
3 'Row 3'
4 'Row 4'
5 'Row 5'
6 'Row 6'.
formats rowM weekday (F1.0).
formats month (F2.0).
*now you just need to make the GPL call!.
!ENDDEFINE.
set seed 15.
input program.
loop #i = 1 to 365.
compute day = DATE.YRDAY(2013,#i).
compute flag = RV.BERNOULLI(0.1).
end case.
end loop.
end file.
end input program.
dataset name days.
format day (ADATE10).
exe.
!heatmap day.
exe.
temporary.
select if flag = 1.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=weekday rowM month
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: weekday=col(source(s), name("weekday"), unit.category())
DATA: rowM=col(source(s), name("rowM"), unit.category())
DATA: month=col(source(s), name("month"), unit.category())
COORD: rect(dim(1,2),wrap())
GUIDE: axis(dim(1))
GUIDE: axis(dim(2), null())
GUIDE: axis(dim(4), opposite())
SCALE: cat(dim(1), include("1.00", "2.00", "3.00", "4.00", "5.00","6.00", "7.00"))
SCALE: cat(dim(2), reverse(), include("1.00", "2.00", "3.00", "4.00", "5.00","6.00"))
SCALE: cat(dim(4), include("1.00", "2.00", "3.00", "4.00", "5.00",
"6.00", "7.00", "8.00", "9.00", "10.00", "11.00", "12.00"))
ELEMENT: polygon(position(weekday*rowM*1*month), color.interior(color.red))
END GPL.
*************************************************************************************.
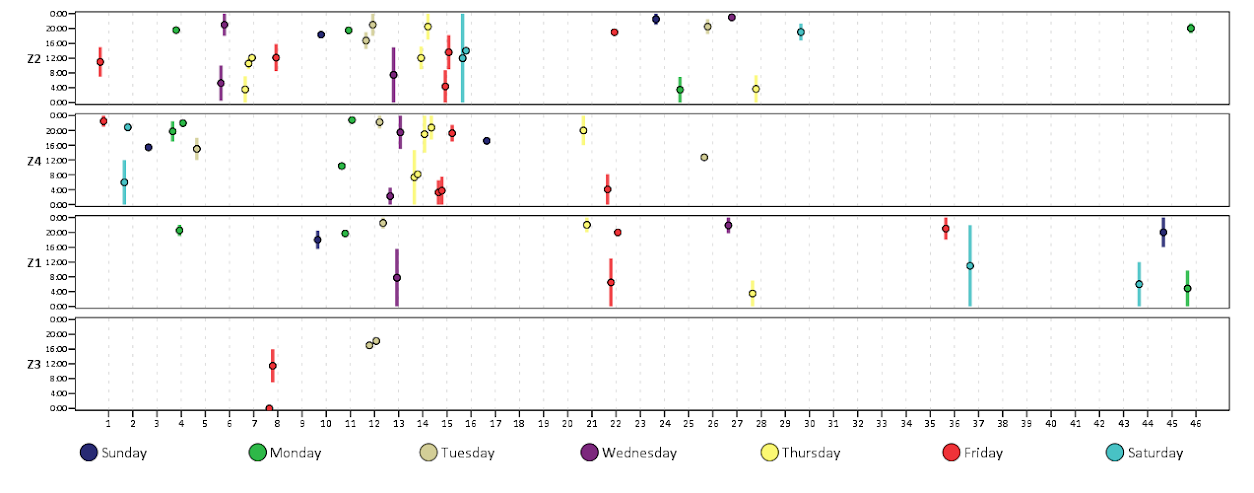
Which produces this image below. You can not run the temporary command to see what the plot looks like with the entire year filled in.
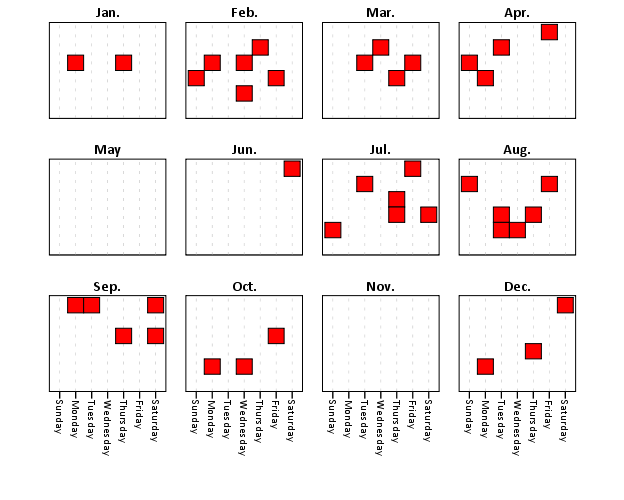
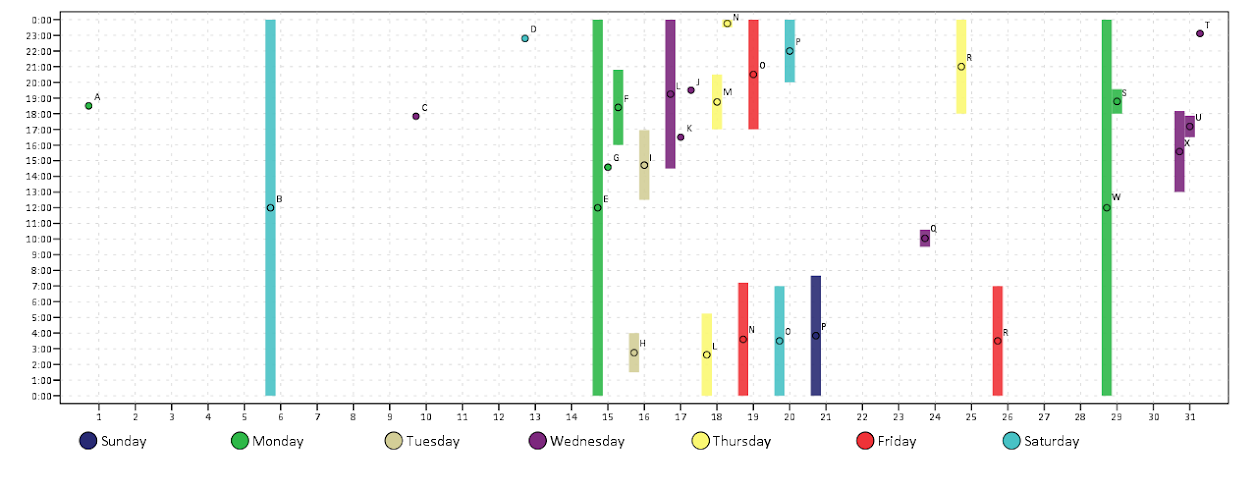
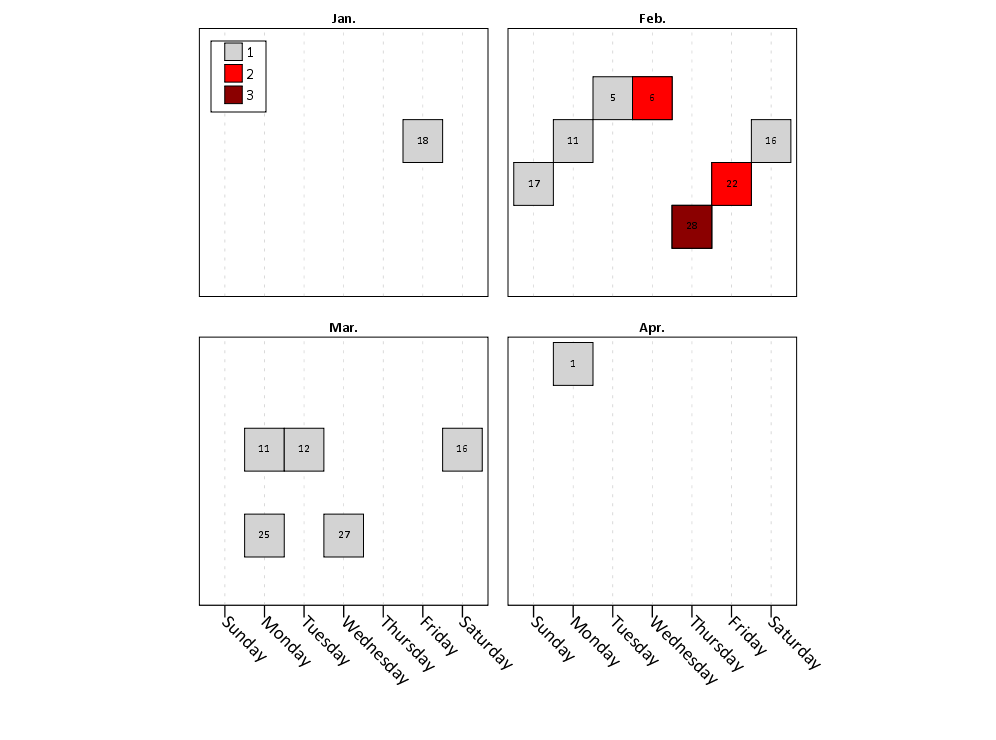
This is nice to illustrate potential day of week patterns for specific events that only rarely occur, but you can map any aesthetic you please to the color of the polygon (or you can change the size of the polygons if you like). Below is an example I used this recently to demonstrate what days a spree of crimes appeared on, and I categorically colored certain dates to indicate multiple crimes occurred on those dates. It is easy to see from the plot that there isn’t a real strong tendency for any particular day of week, but there is some evidence of spurts of higher activity.
In terms of GPL logic I won’t go into too much detail, but the plot works even with months or rows missing in the data because of the finite number of potential months and rows in the plot (see the SCALE statements with the explicit categories included). If you need to plot multiple years, you either need seperate plots or another facet. Most of the examples show numerical information over every day, which is difficult to really see patterns like that, but it shouldn’t be entirely disgarded just because of that (I would have to simultaneously disregard every choropleth map ever made if I did that!)