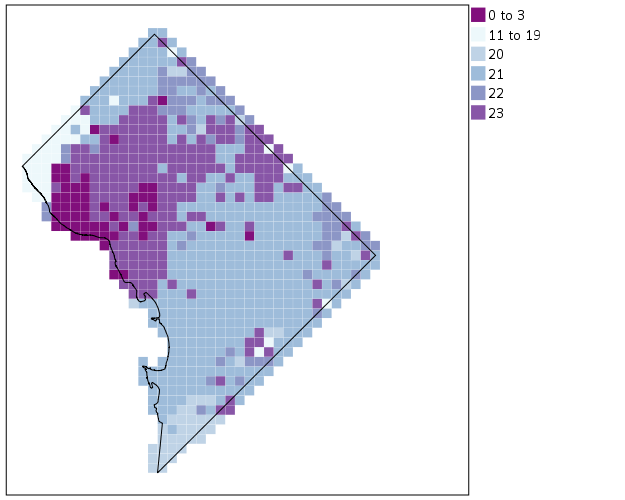
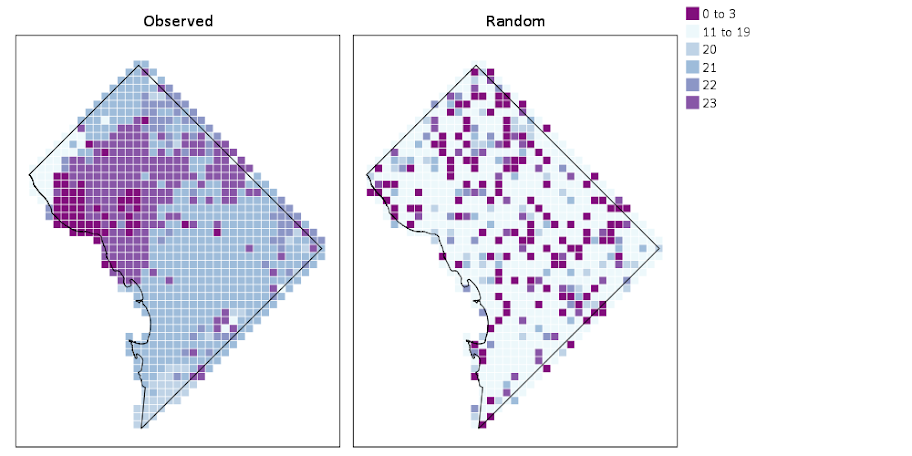
I was recently asked for some code to show how I created the charts in my paper, Tables and Graphs for Monitoring Crime Patterns (Pre-print can be seen here).
I cannot share the data used in the paper, but I can replicate them with some other public data. I will use calls for service publicly available from Burlington, VT to illustrate them.
The idea behind these time-series charts are not for forecasting, but to identify anomalous patterns – such as recent spikes in the data. (So they are more in line with the ideas behind control charts.) Often even in big jurisdictions, one prolific offender can cause a spike in crimes over a week or a month. They are also good to check more general trends as well, to see if crimes have had more slight, but longer term trends up or down.
For a preview, we will be making a weekly time series chart:
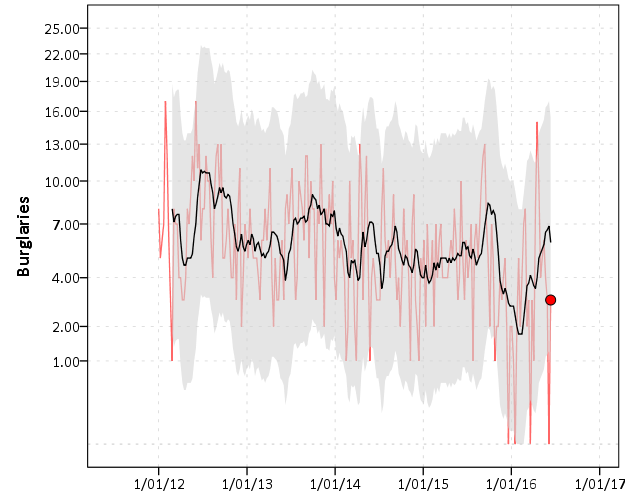
In the weekly chart the red line is the actual data, the black line is the average of the prior 8 weeks, and the grey band is a Poisson confidence interval around that prior moving average. The red dot is the most recent week.
And we will also be making a monthly seasonal chart:
The red line is the counts of calls per month in the current year, and the lighter grey lines are prior years (here going back to 2012).
So to start, I saved the 2012 through currently 6/20/2016 calls for service data as a csv file. And here is the code to read in that incident level data.
*Change this to where the csv file is located on your machine.
FILE HANDLE data /NAME = "C:\Users\andrew.wheeler\Dropbox\Documents\BLOG\Tables_Graphs".
GET DATA /TYPE=TXT
/FILE="data\Calls_for_Service_Dashboard_data.csv"
/ENCODING='UTF8'
/DELCASE=LINE
/DELIMITERS=","
/QUALIFIER='"'
/ARRANGEMENT=DELIMITED
/FIRSTCASE=2
/DATATYPEMIN PERCENTAGE=95.0
/VARIABLES=
AdjustedLatitude AUTO
AdjustedLongitude AUTO
AlcoholRelated AUTO
Area AUTO
CallDateTime AUTO
CallType AUTO
Domv AUTO
DayofWeek AUTO
DrugRelated AUTO
EndDateTime AUTO
GeneralTimeofDay AUTO
IncidentNumber AUTO
LocationType AUTO
MentalHealthRelated AUTO
MethodofEntry AUTO
Month AUTO
PointofEntry AUTO
StartDateTime AUTO
Street AUTO
Team AUTO
Year AUTO
/MAP.
CACHE.
EXECUTE.
DATASET NAME CFS.First I will be making the weekly chart. What I did when I was working as an analyst was make a chart that showed the recent weekly trends and to identify if the prior week was higher than you might expect it to be. The weekly patterns can be quite volatile though, so I smoothed the data based on the average of the prior eight weeks, and calculated a confidence interval around that average count (based on the Poisson distribution).
As a start, we are going to turn our date variable, CallDateTime, into an SPSS date variable (it gets read in as a string, AM/PM in date-times are so annoying!). Then we are going to calculate the number of days since some baseline – here it is 1/1/2012, which is Sunday. Then we are going to calculate the weeks since that Sunday. Lastly we select out the most recent week, as it is not a full week.
*Days since 1/1/2012.
COMPUTE #Sp = CHAR.INDEX(CallDateTime," ").
COMPUTE CallDate = NUMBER(CHAR.SUBSTR(CallDateTime,1,#Sp),ADATE10).
COMPUTE Days = DATEDIFF(CallDate,DATE.MDY(1,1,2012),"DAYS").
COMPUTE Weeks = TRUNC( (Days-1)/7 ).
FREQ Weeks /FORMAT = NOTABLE /STATISTICS = MIN MAX.
SELECT IF Weeks < 233.Here I do weeks since a particular date, since if you do XDATE.WEEK you can have not full weeks. The magic number 233 can be replaced by sometime like SELECT IF Weeks < ($TIME - 3*24*60*60). if you know you will be running the syntax on a set date, such as when you do a production job. (Another way is to use AGGREGATE to figure out the latest date in the dataset.)
Next what I do is that when you use AGGREGATE in SPSS, there can be missing weeks with zeroes, which will mess up our charts. There end up being 22 different call-types in the Burlington data, so I make a base dataset (named WeekFull) that has all call types for each week. Then I aggregate the original calls for service dataset to CallType and Week, and then I merge the later into the former. Finally I then recode the missings intos zeroes.
*Make sure I have a full set in the aggregate.
FREQ CallType.
AUTORECODE CallType /INTO CallN.
*22 categories, may want to collapse a few together.
INPUT PROGRAM.
LOOP #Weeks = 0 TO 232.
LOOP #Calls = 1 TO 22.
COMPUTE CallN = #Calls.
COMPUTE Weeks = #Weeks.
END CASE.
END LOOP.
END LOOP.
END FILE.
END INPUT PROGRAM.
DATASET NAME WeekFull.
*Aggregate number of tickets to weeks.
DATASET ACTIVATE CFS.
DATASET DECLARE WeekCalls.
AGGREGATE OUTFILE='WeekCalls'
/BREAK Weeks CallN
/CallType = FIRST(CallType)
/TotCalls = N.
*Merge Into WeekFull.
DATASET ACTIVATE WeekFull.
MATCH FILES FILE = *
/FILE = 'WeekCalls'
/BY Weeks CallN.
DATASET CLOSE WeekCalls.
*Missing are zero cases.
RECODE TotCalls (SYSMIS = 0)(ELSE = COPY).Now we are ready to calculate our statistics and make our charts. First we create a date variable that represents the beginning of the week (for our charts later on.) Then I use SPLIT FILE and CREATE to calculate the prior moving average only within individiual call types. The last part of the code calculates a confidence interval around prior moving average, and assumes the data is Poisson distributed. (More discussion of this is in my academic paper.)
DATASET ACTIVATE WeekFull.
COMPUTE WeekBeg = DATESUM(DATE.MDY(1,1,2012),(Weeks*7),"DAYS").
FORMATS WeekBeg (ADATE8).
*Moving average of prior 8 weeks.
SORT CASES BY CallN Weeks.
SPLIT FILE BY CallN.
CREATE MovAv = PMA(TotCalls,8).
*Calculating the plus minus 3 Poisson intervals.
COMPUTE #In = (-3/2 + SQRT(MovAv)).
DO IF #In >= 0.
COMPUTE LowInt = #In**2.
ELSE.
COMPUTE LowInt = 0.
END IF.
COMPUTE HighInt = (3/2 + SQRT(MovAv))**2.
EXECUTE.If you rather use the inverse of the Poisson distribution I have notes in the code at the end to do that, but they are pretty similar in my experience. You also might consider (as I mention in the paper), rounding fractional values for the LowInt down to zero as well.
Now we are ready to make our charts. The last data manipulation is to just put a flag in the file for the very last week (which will be marked with a large red circle). I use EXECUTE before the chart just to make sure the variable is available. Finally I keep the SPLIT FILE on, which produces 22 charts, one for each call type.
IF Weeks = 232 FinCount = TotCalls.
EXECUTE.
*Do a quick look over all of them.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=WeekBeg TotCalls MovAv LowInt HighInt FinCount MISSING=VARIABLEWISE
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: WeekBeg=col(source(s), name("WeekBeg"))
DATA: TotCalls=col(source(s), name("TotCalls"))
DATA: MovAv=col(source(s), name("MovAv"))
DATA: LowInt=col(source(s), name("LowInt"))
DATA: HighInt=col(source(s), name("HighInt"))
DATA: FinCount=col(source(s), name("FinCount"))
SCALE: pow(dim(2), exponent(0.5))
GUIDE: axis(dim(1))
GUIDE: axis(dim(2), label("Crime Count"))
ELEMENT: line(position(WeekBeg*TotCalls), color(color.red), transparency(transparency."0.4"))
ELEMENT: area(position(region.spread.range(WeekBeg*(LowInt+HighInt))), color.interior(color.lightgrey),
transparency.interior(transparency."0.4"), transparency.exterior(transparency."1"))
ELEMENT: line(position(WeekBeg*MovAv))
ELEMENT: point(position(WeekBeg*FinCount), color.interior(color.red), size(size."10"))
END GPL.
SPLIT FILE OFF.This is good for the analyst, I can monitor many series. Here is an example the procedure produces for mental health calls:

The current value is within the confidence band, so it is not alarmingly high. But we can see that they have been trending up over the past few years. Plotting on the square root scale makes the Poisson count data have the same variance, but a nice thing about the SPLIT FILE approach is that SPSS does smart Y axis ranges for each individual call type.
You can update this to make plots for individual crimes, and here I stuff four different crime types into a small multiple plot. I use a TEMPORARY and SELECT IF statement before the GGRAPH code to select out the crime types I am interested in.
FORMATS TotCalls MovAv LowInt HighInt FinCount (F3.0).
TEMPORARY.
SELECT IF ANY(CallN,3,10,13,17).
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=WeekBeg TotCalls MovAv LowInt HighInt FinCount CallN MISSING=VARIABLEWISE
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
PAGE: begin(scale(900px,600px))
SOURCE: s=userSource(id("graphdataset"))
DATA: WeekBeg=col(source(s), name("WeekBeg"))
DATA: TotCalls=col(source(s), name("TotCalls"))
DATA: MovAv=col(source(s), name("MovAv"))
DATA: LowInt=col(source(s), name("LowInt"))
DATA: HighInt=col(source(s), name("HighInt"))
DATA: FinCount=col(source(s), name("FinCount"))
DATA: CallN=col(source(s), name("CallN"), unit.category())
COORD: rect(dim(1,2), wrap())
SCALE: pow(dim(2), exponent(0.5))
GUIDE: axis(dim(1))
GUIDE: axis(dim(2), start(1), delta(3))
GUIDE: axis(dim(3), opposite())
GUIDE: form.line(position(*,0),color(color.lightgrey),shape(shape.half_dash))
ELEMENT: line(position(WeekBeg*TotCalls*CallN), color(color.red), transparency(transparency."0.4"))
ELEMENT: area(position(region.spread.range(WeekBeg*(LowInt+HighInt)*CallN)), color.interior(color.lightgrey),
transparency.interior(transparency."0.4"), transparency.exterior(transparency."1"))
ELEMENT: line(position(WeekBeg*MovAv*CallN))
ELEMENT: point(position(WeekBeg*FinCount*CallN), color.interior(color.red), size(size."10"))
PAGE: end()
END GPL.
EXECUTE.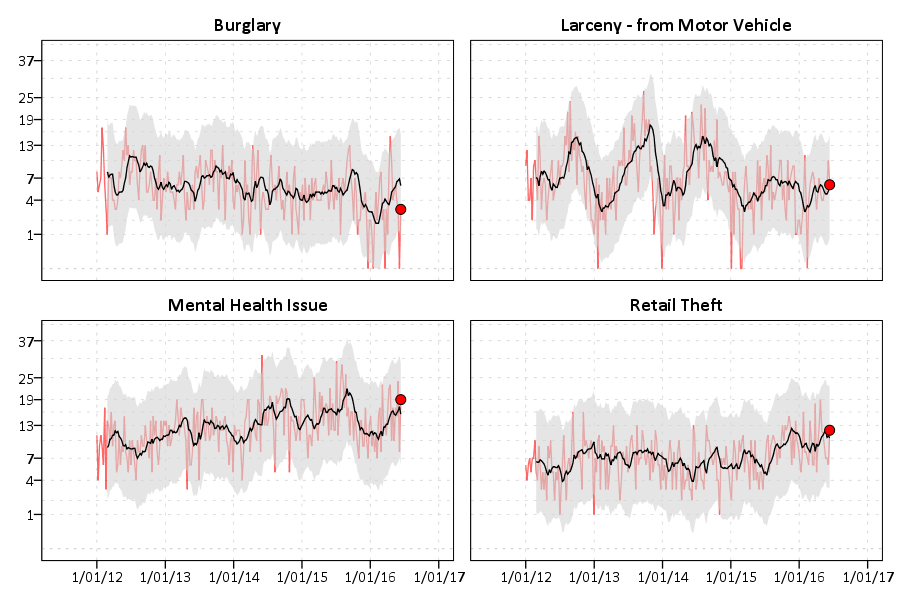
You could do more fancy time-series models to create the confidence bands or identify the outliers, (exponential smoothing would be similar to just the prior moving average I show) but this ad-hoc approach worked well in my case. (I wanted to make more fancy models, but I did not let the perfect be the enemy of the good to get at least this done when I was employed as a crime analyst.)
Now we can move onto making our monthly chart. These weekly charts are sometimes hard to visualize with highly seasonal data. So what this chart does is gives each year a new line. Instead of drawing error bars, the past years data show the typical variation. It is then easy to see seasonal ups-and-downs, as well as if the latest month is an outlier.
Getting back to the code — I activate the original calls for service database and then close the Weekly database. Then it is much the same as for weeks, but here I just use calendar months and match to a full expanded set of calls types and months over the period. (I do not care about normalizing months, it is ok that February is only 28 days).
DATASET ACTIVATE CFS.
DATASET CLOSE WeekFull.
COMPUTE Month = XDATE.MONTH(CallDate).
COMPUTE Year = XDATE.YEAR(CallDate).
DATASET DECLARE AggMonth.
AGGREGATE OUTFILE = 'AggMonth'
/BREAK Year Month CallN
/MonthCalls = N.
INPUT PROGRAM.
LOOP #y = 2012 TO 2016.
LOOP #m = 1 TO 12.
LOOP #call = 1 TO 22.
COMPUTE CallN = #call.
COMPUTE Year = #y.
COMPUTE Month = #m.
END CASE.
END LOOP.
END LOOP.
END LOOP.
END FILE.
END INPUT PROGRAM.
DATASET NAME MonthAll.
MATCH FILES FILE = *
/FILE = 'AggMonth'
/BY Year Month CallN.
DATASET CLOSE AggMonth.Next I select out the most recent month of the date (June 2016) since it is not a full month. (When I originally made these charts I would normalize to days and extrapolate out for my monthly meeting. These forecasts were terrible though, even only extrapolating two weeks, so I stopped doing them.) Then I calculate a variable called Current – this will flag the most recent year to be red in the chart.
COMPUTE MoYr = DATE.MDY(Month,1,Year).
FORMATS MoYr (MOYR6) Year (F4.0) Month (F2.0).
SELECT IF MoYr < DATE.MDY(6,1,2016).
RECODE MonthCalls (SYSMIS = 0)(ELSE = COPY).
*Making current year red.
COMPUTE Current = (Year = 2016).
FORMATS Current (F1.0).
SORT CASES BY CallN MoYr.
SPLIT FILE BY CallN.
*Same thing with the split file.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=Month MonthCalls Current Year
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: Month=col(source(s), name("Month"), unit.category())
DATA: MonthCalls=col(source(s), name("MonthCalls"))
DATA: Current=col(source(s), name("Current"), unit.category())
DATA: Year=col(source(s), name("Year"), unit.category())
GUIDE: axis(dim(1))
GUIDE: axis(dim(2), label("Calls"), start(0))
GUIDE: legend(aesthetic(aesthetic.color.interior), null())
SCALE: cat(aesthetic(aesthetic.color.interior), map(("0",color.lightgrey),("1",color.red)))
ELEMENT: line(position(Month*MonthCalls), color.interior(Current), split(Year))
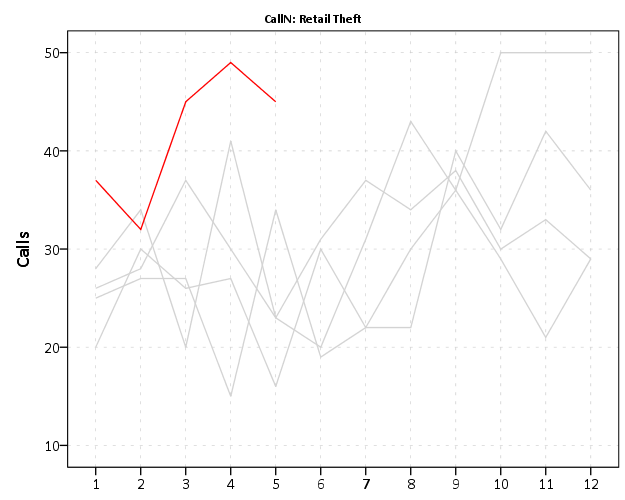
END GPL.You can again customize this to be individual charts for particular crimes or small multiples. You can see in the example at the beginning of the post Retail thefts are high for March, April and May. I was interested to examine overdoses, as the northeast (and many parts of the US) are having a problem with heroin at the moment. In the weekly charts they are so low of counts it is hard to see any trends though.
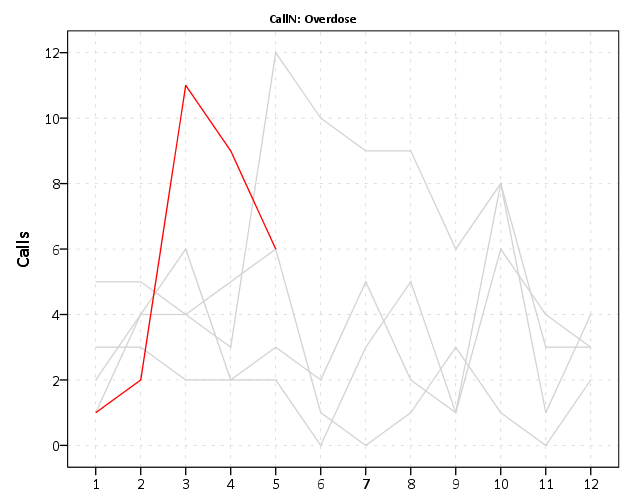
We can see that overdoses were high in March. The other highest line are months in 2015, so it looks like a problem here in Burlington, but it started around a year ago.
For low counts of crime (say under 20 per month) seasonality tends to be hard to spot. For crimes more frequent though you can often see pits and peaks in summer and winter. It is not universal that crimes increase in the summer though. For ordinance violations (and ditto for Noise complaints) we can see a pretty clear peak in September. (I don’t know why that is, there is likely some logical explanation for it though.)
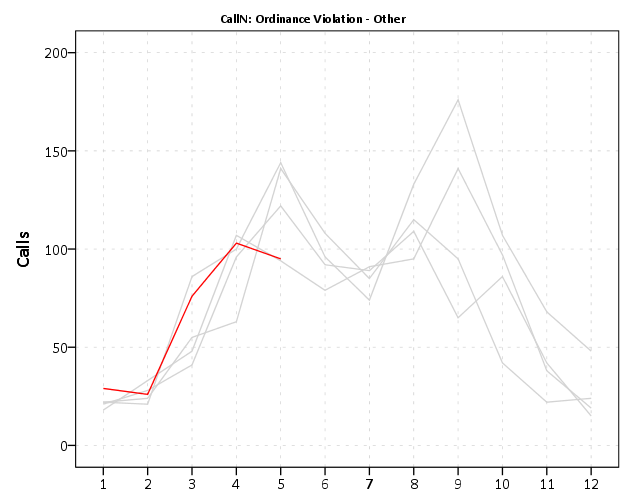
My main motivation to promote these is to replace terrible CompStat tables of year-over-year percent changes. All of these patterns I’ve shown are near impossible to tell from tables of counts per month.
Finally if you want to export your images to place into another report, you can use:
OUTPUT EXPORT /PNG IMAGEROOT = "data\TimeGraphs.png".PNG please – simple vector graphics like these should definately not be exported as jpegs.
Here is a link to the full set of syntax and the csv data to follow along. I submitted to doing an hour long training session at the upcoming IACA conference on this, so hopefully that gets funded and I can go into this some more.