
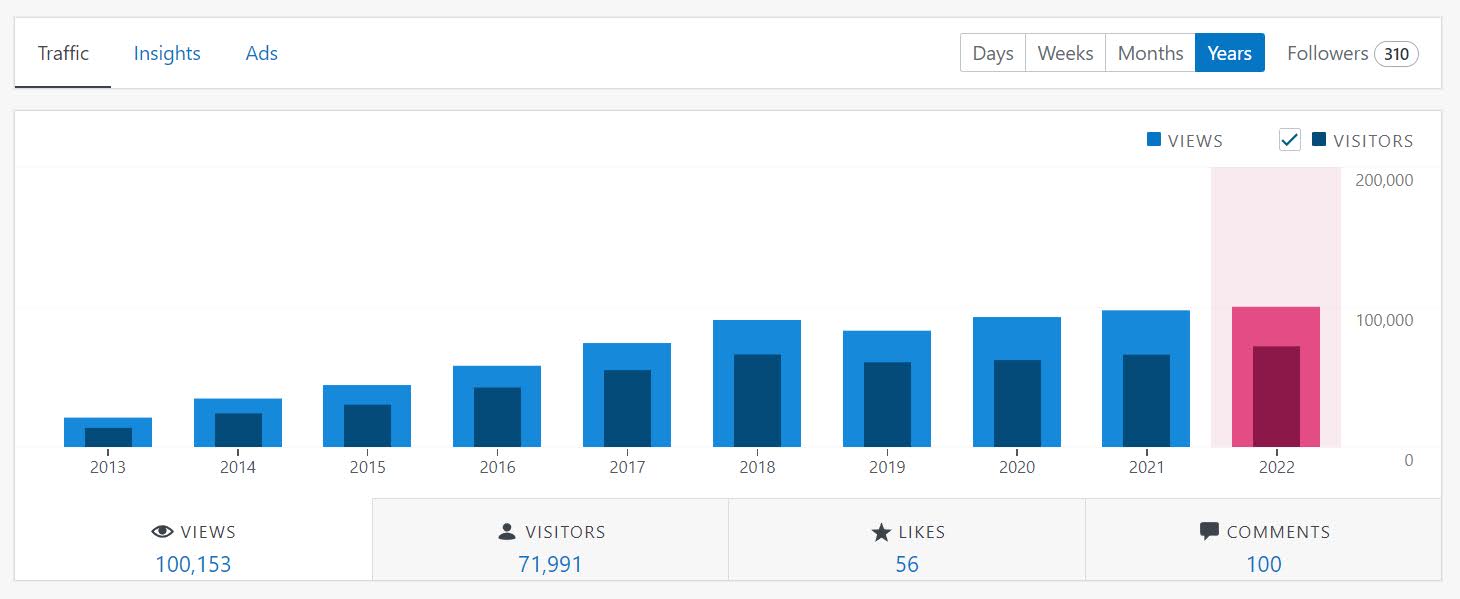
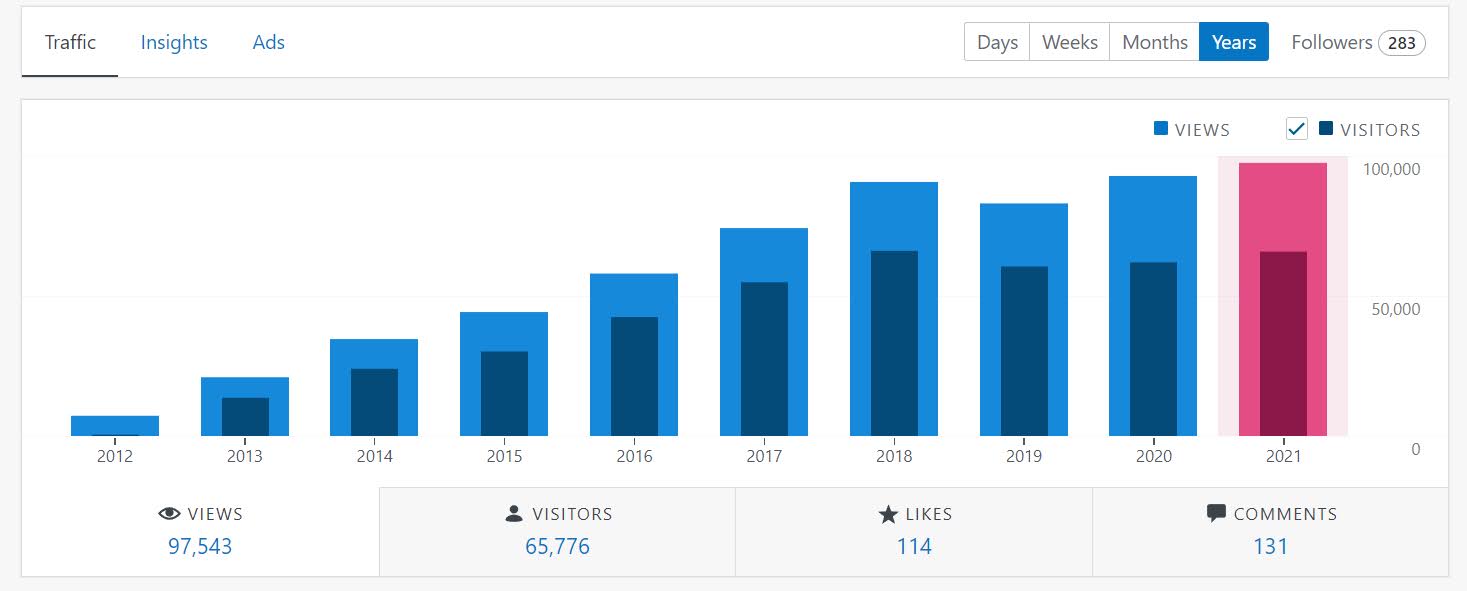
In 2023, I published 45 pages on the blog. Cumulative site views were slightly more than last year, a few over 150,000.

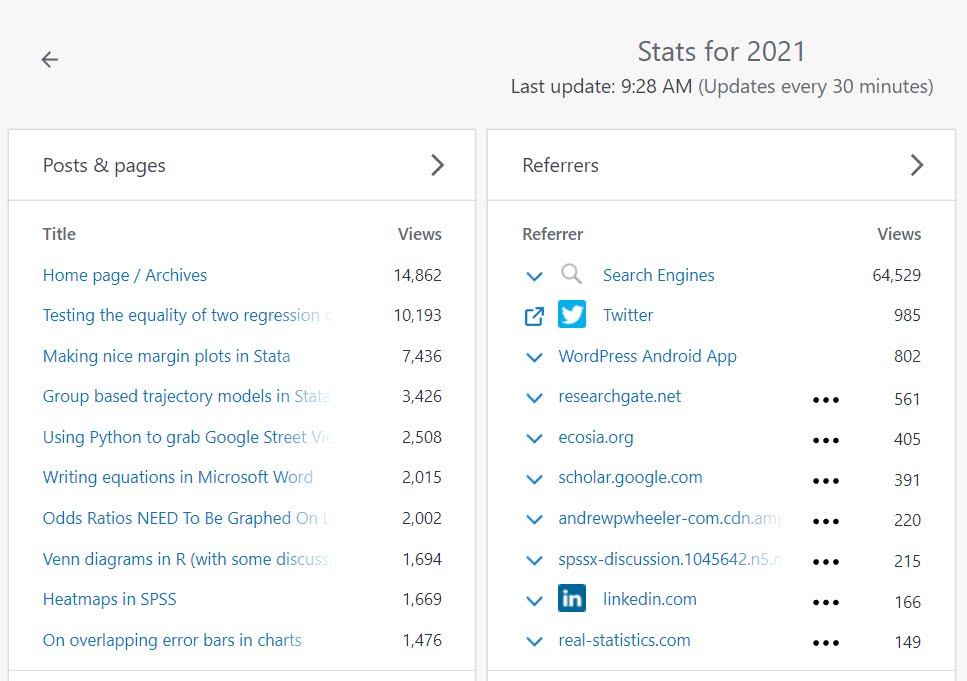
I would have had pretty much steady cumulative views from last year (site views took a dip in April, the prior year had quite a bit of growth, I suspect something to do with the way WordPress counts stats changed), but in December my post Forecasts need to have error bars hit front page on Hackernews. This generated about 12k views for that post over two days. (In 2022 I had just shy of 140k views in total.)

It was very high on the front page (#1) for most of that day. So for folks who want to guesstimate the “death by Hackernews” referrals, I would guess if your site/app can handle 10k requests in an hour you will be ok. WordPress by default this is fine (my Crime De-Coder Hostinger site is maybe not so good for that, the SLA is 20k requests per day). Also interesting note, about 10% of people who were referred to the forecast post clicked at least one other page on the site.
So I started CRIME De-Coder in February this year. I have published a few over 30 pages on that site during the year, and have accumulated a total of a few more than 11k site views. This is very similar to the first year of my personal blog, with publishing around 30 posts and getting just over 7k total views for the year. This is almost entirely via direct referrals (I share posts on LinkedIn, google searches are just a trickle).
Sometimes people are like “cool you started your own company”, but really I did that same type of consulting since I was in grad school. I have had a fairly consistent set of consulting work (around $20k per year) for quite awhile. That was people cold asking me for help with mostly statistical analysis.
The reason I started CRIME De-Coder was to be more intentional about it – advertise the work I do, instead of waiting for people to come to me. Doing your own LLC is simple, and it is more a website than anything.
So how much money did I make this year for CRIME De-Coder? Not that much more than $30k (I don’t count the data competitions I won in that metric, but actual commissioned work.) I do have substantially more work lined up for next year though already (more on the order of $50k so far, although no doubt some of that will fall through).
I sent out something like 30 some soft pitches during the year to people in my extended network (first or strong second degree). I don’t know the typical rate of something like that, but mine was abysmal – I was lucky to get an email response no thanks. These are just ideas like “hey I could build you an interactive dashboard with your data” or “you paid this group $150k, I would do that same thing for less than $30k”.
Having CRIME De-Coder did however did increase my first degree network to “ask me for stat analysis” more. So it was definitely worth spending time doing the website and creating the LLC. Don’t ask me for advice though about making pitches for consulting work!
The goal is ultimately to be able to go solo, and just do my consulting work as my full time job. It is hard to see that happening though – even if I had 5 times the amount of work lined up, it would still just be short term single projects. I have pitched more consistent retainers, but no one has gone for that. Small police departments if interested in outsourcing crime analysis let me know – that is I believe the best solution for them. Also have pitched to think tanks to hire me part time as well, as well as CJ programs to hire me in part time roles as well. I understand the CJ programs no interest, I am way more expensive than typical adjunct, I am a good deal for other groups though. (I mean I am good deal for CJ programs as well, part of the value add is supervising students for research, but universities don’t value that very high.)
I will ultimately keep at it – sending email pitches is easy. And I am hoping that as the website gets more organic search referrals, I will be able to break out of my first degree network.




Musings on Comments
I recently posted a comment policy. I do not get that many comments now, but I did delete a comment recently asking for help on a code sample, so figured it would be worth elaborating on.
Comments are great, and I hope to get more, but with my participation on the stack exchange sites (and commenting on other blogs) I definitely see the need to take active moderation. This is not a big deal for the site so far (I rarely post anything controversial) but is really necessary for any blog generating a lot of comments.
My position is not quite extreme as Ed Tufte, e.g. I don’t plan on deleting a comment if I don’t like the content enough, but I will definitely delete off-topic comments and anything I find offensive. My position is more in line with Jeff Atwood’s thoughts, who discusses the topic quite a bit on his coding horror blog (see here for one example).
Basically the comments take curation, just like any site or wiki. Comments without moderation in any substantive amount (e.g. YouTube, many news articles) are simply not worth reading. The same moderation is what makes the stack exchange sites so much better than email list-serves, and the lack of moderation is what makes some MOOC forums so chaotic.
Posted by Andy Wheeler on December 7, 2014
https://andrewpwheeler.com/2014/12/07/musings-on-comments/