Two resources I have been consuming lately I would highly recommend:
- How to measure anything by Douglas Hubbard
- Keith McCormick’s short LinkedIn courses, particularly just went through estimating return on investment
Keith’s perspective is nearly a 100% match to my experiences, e.g. should aim for projects that have around $1 million in expected revenue to justify a data science person/team, up front estimates should be on the low end, the easiest projects you can formulate as micro-decisions and you use a model to improve those binary decisions, etc. How to measure anything fits right into this as well, where Hubbard basically says get a prior distribution on expected outcomes, and then do simulations to see possible outcomes.
Here I am going to show an example that is very close to several of the projects I have done to show the potential increase in revenue from taking a model based approach using simulations in python.
Background
So the point in the data science project I am going to be illustrating is you have already decided to do an initial pilot model, and you have historical cases and then predicted probabilities from your model. Here I am thinking of the case of auditing some type transaction (it can be whatever you want, tax-returns, bank transactions, insurance claims, etc.). Here I am going to simulate some fake data to illustrate the later ROI estimates, but in real life you would use your own data for the business.
Here the variables I simulate are:
- 5000 transactions,
total_cases - a model based predicted probability,
prob - a dollar value for the transaction,
dollar - a historical marker whether a transaction was audited,
audit - a historical marker whether the transaction was bad,
hit
To be clear, this would be data you would normally already have for your business use case (e.g. historical transactions). To just illustrate my point I am making 100% fake data for everyone to follow along.
####################################
# Simulating data, probabilities
# and money values
from scipy.stats import norm
from scipy.stats import binom
from scipy.stats import beta
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
np.random.seed(10)
total_cases = 5000
# Beta(1,5), to generate the probs
prob = beta.rvs(1, 5, size=total_cases)
# Lognormal for the dollar values, clipped
dollar = np.exp(norm.rvs(7,2,size=total_cases)).clip(500,25000)
# Historical auditing process, all cases over 15000
audit = (dollar > 15000)*1
# Out of these, random 10% are hits
hit = binom.rvs(1, 0.10, size=total_cases)
# Putting into a dataframe
cases = pd.concat([pd.Series(dollar),pd.Series(audit),
pd.Series(prob), pd.Series(hit)],
axis=1)
cases.columns = ['value','audit','prob', 'hit']
cases['revenue'] = cases['hit']*cases['value']*cases['audit']
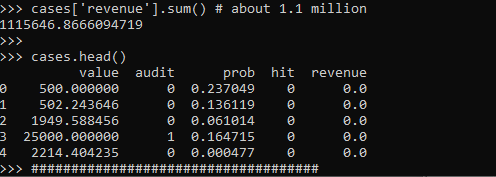
cases['revenue'].sum() # about 1.1 million
cases.head()
####################################
These are all simulated from various probability distributions to look somewhat like real data. Probabilities and dollar values are right skewed. They are independent here, but it is ok if in your real data they are not.
Here I pretend the historical audit selection process is they automatically audit all large transactions, over $15k. And these historical audits have a 10% probability of finding a hit (think of it as fraud if you want). So the context is given our model estimates prob, how much more money do we think we can make if you use these model based decision as opposed to our simple threshold that is the current process?
Revenue Simulations
So here for my revenue simulations, what I am going to do is pretend I can audit the same number of cases (471), based on my model estimates, audit_total.
audit_total = audit.sum() #pretend we get to model the same
#number of cases
cases['model_expected'] = cases['prob']*cases['value']
cases['model_rank'] = cases['model_expected'].rank(method='first', ascending=False)
cases['model_audit'] = 1*(cases['model_rank'] >= audit_total)
# Expected revenue from our model based approach
(cases['model_audit']*cases['model_expected']).sum()
# About 1.3 millionSo if our model is well calibrated, we can take those predicted probabilities and estimate what we think should happen if we used our model to audit 471 cases. Here we think we would make around 1.3 million, so about a lift of over $200k.
But, these models are probabilistic estimates. So I like to use simulations to hedge a bit when I am presenting to the business. Here I do 5000 simulations where I select my 471 cases, use a binomial random number generator to flip the coin whether the case results in a hit or not, and then calculate the total revenue.
# Simulating binomial process, seeing what the revenue is
cases_audit = cases[cases['model_audit'] == 1].copy()
rev_sim = [] #doing 5000 simulations
for i in range(5000):
hit_sim = binom.rvs(1, cases_audit['prob'])
sim_outs = hit_sim * cases_audit['value']
rev_sim.append( (sim_outs.sum(), hit_sim.mean()) )
rev_sim = pd.DataFrame(rev_sim, columns=['RevSim','HitRateSim'])We can then turn this into a nice graph of simulated potential outcomes. In our model approach, on average we would expect to make $1.3 million (versus the actual revenue of $1.1 million), but we have variance around that estimate:
# making a nice graph
actual_rev = cases['revenue'].sum()/1000000
ax = (rev_sim['RevSim']/1000000).hist(bins=100, alpha=0.8, color='grey')
ax.grid(False)
ax.axvline(actual_rev, color='r', linewidth=3)
ax.set_xlabel('Audit Revenue in $1,000,000')
plt.text(actual_rev + 0.008, 150, 'Actual Revenue', color='r')
plt.title('Simulated Revenue when using Model')
plt.show()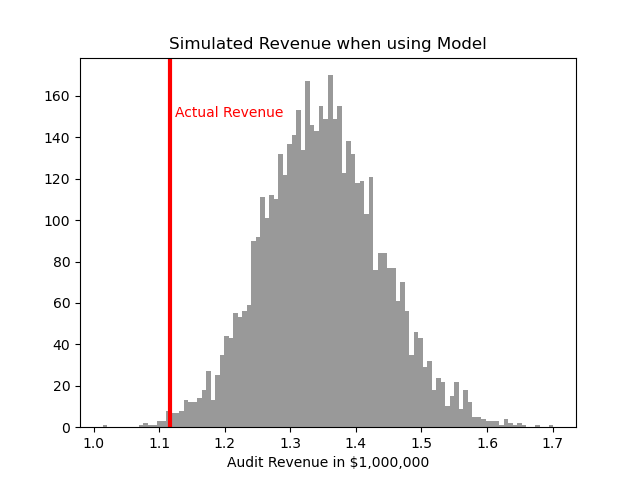
So you can see on a very few occasions we make less than the revenue under the current strategy of audit all large cases. But in just as many circumstances we are making over $400k in additional profit.
You may ask why 5000 simulations instead of more or less? Well these are small enough I can easily do them quickly, so I could up the simulations to a higher value if I wanted. Long story short, if you look at the histogram of outcomes and it is still quite bumpy, you should probably do more simulations. Here 5000 is plenty, although 1000 was clearly more bumpy.
If you don’t want to present the histogram, or have more complicated scenarios and prefer a table laying those scenarios out, you can pull out simulated confidence intervals of the additional revenue outcomes:
# If you want to put a confidence interval on it
# Per 1000 dollars
diff = (rev_sim['RevSim'] - cases['revenue'].sum())/1000
diff.describe()
# 95% confidence interval
diff.quantile([0.025,0.975])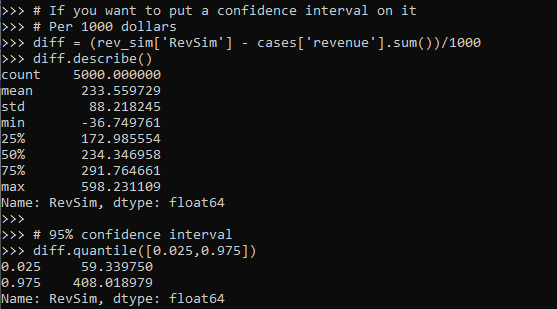
One of the benefits of having a model, even if the revenue is not increased, is that you can generate estimates for other types of interventions. In the auditing case, you can potentially justify more auditors (e.g. we can hire more people to investigate 400 more cases and still expect to make a profit). (Here I have a related criminal justice example for bail decisions.) Or you can apply the models as a potential sales pitch to a new client. E.g. if you hire us to do these audits, given your data and our model, we think we can make the $X dollars.
Model based approaches also allow you to meet more constraints, such as increasing the hit rate, or meeting fairness constraints. Here in this simulation if we use a model based approach, the hit rate goes up to around 15% as opposed to 10%. Which may be worth it for your investigators or clients depending on the situation.