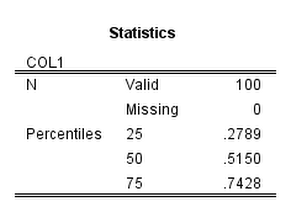
So I actually bothered to read the help the other day for SPSSINC TRANS, which being generic allows you to use Python functions similar to how COMPUTE statements work, just a bit more general. Two examples of passing arguments I did not know you could do were 1) pass a list as an argument, and 2) pass constants that aren’t SPSS variables to functions. To follow are a few brief examples.
The first is passing a list to a function, and here is a simple example using the Python function sorted().
DATA LIST FREE / X1 X2 X3.
BEGIN DATA
3 2 1
1 0 3
1 1 2
2 2 1
3 0 3
END DATA.
DATASET NAME Test.
SPSSINC TRANS RESULT=S1 S2 S3 TYPE=0
/FORMULA sorted([X1,X2,X3]).This takes the variables X1 to X3, sorts them, and returns them in a new set of variables S1 to S3. We can also do reverse sorting by passing a constant value of 1 to the reverse function, which acts synonymously with reverse=True.
SPSSINC TRANS RESULT=RS1 RS2 RS3 TYPE=0
/FORMULA sorted([X1,X2,X3],reverse=1).This is a rather simplistic example, but the action is much simpler in Python than whatever equivalent SPSS code you can come up with. When using the SPSSINC TRANS extension it expects the returned function to simply be a flat list. For this sorting situation though it might be convenient to return the order in which the original value was stored. Here I make a function that returns the indice of the original list, and then flattens the two into sequential order, per this SO answer.
BEGIN PROGRAM Python.
import itertools
def SortList(L,reverse=0):
I = range(1,len(L)+1)
x = sorted(zip(L,I),reverse=reverse)
r = list(itertools.chain.from_iterable(x))
return r
#example use
print SortList(L=[2,1,3])
print SortList(L=[2,1,3],reverse=1)
END PROGRAM.
MATCH FILES FILE = * /DROP S1 TO RS3.
SPSSINC TRANS RESULT= S1 T1 S2 T2 S3 T3 TYPE=0
/FORMULA SortList([X1,X2,X3],reverse=1).When passing a string constant to a function in SPSSINC TRANS you need to triple quote the string. This makes some of my prior examples of using the Google maps related API’s much simpler. Instead of making variables to pass to the function, you can just triple quote the constants. Also when using the maps API I often have an argument for the API key, but you will get results even without a key (I presume Google just checks the IP address an limits you after so many requests). So for many of my functions you can not worry about making an API key and just pass an empty string. Here is an example from my prior Google distance API post using string constants and no API key.
BEGIN PROGRAM Python.
import urllib, json
#This parses the returned json to pull out the distance in meters and
#duration in seconds, [None,None] is returned is status is not OK
def ExtJsonDist(place):
if place['rows'][0]['elements'][0]['status'] == 'OK':
meters = place['rows'][0]['elements'][0]['distance']['value']
seconds = place['rows'][0]['elements'][0]['duration']['value']
else:
meters,seconds = None,None
return [meters,seconds]
#Takes a set of lon-lat coordinates for origin and destination,
#plus your API key and returns the json from the distance API
def GoogDist(OriginX,OriginY,DestinationX,DestinationY,key):
MyUrl = ('https://maps.googleapis.com/maps/api/distancematrix/json'
'?origins=%s,%s'
'&destinations=%s,%s'
'&key=%s') % (OriginY,OriginX,DestinationY,DestinationX,key)
response = urllib.urlopen(MyUrl)
jsonRaw = response.read()
jsonData = json.loads(jsonRaw)
data = ExtJsonDist(jsonData)
return data
END PROGRAM.
*Grab the online data.
DATASET CLOSE ALL.
SPSSINC GETURI DATA
URI="https://dl.dropboxusercontent.com/u/3385251/NewYork_ZipCentroids.sav"
FILETYPE=SAV DATASET=NY_Zips.
*Selecting out only a few.
SELECT IF $casenum <= 5.
EXECUTE.
SPSSINC TRANS RESULT=Meters Seconds TYPE=0 0
/FORMULA GoogDist(OriginX=LongCent,OriginY=LatCent,DestinationX='''-78.276205''',DestinationY='''42.850721''',key=''' ''').