My first solo publication, The moving home effect: A quasi experiment assessing effect of home location on the offence location, after being in the online first que nearly a year, has finally been published in the Journal of Quantitative Criminology 28(4):587-606. It was the oldest paper in the online first section (along with the paper by Light and Harris published on the same day)!

This paper was the fruits of what was basically the equivalent of my Masters thesis, and I would like to take this opportunity to thank all of the individuals whom helped me with the project, as I accidently ommitted such thanks from the paper (entirely my own fault). I would like to thank my committee members, Rob Worden, Shawn Bushway, and Janet Stamatel. I would also like to thank Robert Apel and Greg Pogarsky for useful feedback I had recieved on in class papers based on the same topic, as well as the folks in the Worden meeting group (for not only feedback but giving me motivation to do work so I had something to say!)
Rob Worden was the chair of my committee, and he deserves extra thanks not only for reviewing my work, but also for giving me a job at the Finn Institute, which otherwise I would have never had access to such data and opportunity to conduct such a project. I would also like to give thanks to the Syracuse PD and Chief Fowler for letting me use the data and reveal the PD’s identity in the publication.
I would also like to thank Alex Piquero and Cathy Widom for letting me make multiple revisions and accepting the paper for publication. For the publication itself I recieved three very excellent and thoughtful peer reviews. The excellence of the reviews were well above the norm for feedback I have otherwise encountered, and demonstrated that the reviewers not only read the paper but read it carefully. I was really happy with the improvements as well as how fair and thoughtful the reviews were. I am also very happy it was accepted for publication in JQC, it is the highest quality venue I would expect the paper to be on topic at, and if it wasn’t accepted there I was really not sure where I would send it otherwise.
In the future I will publish pre-prints online, so the publication before editing can still be publicly available to everyone. But, if you can not get a copy of this (or any of the other papers I have co-authored so far) don’t hesitate to shoot me an email for a copy of the off-print. Hopefully I have some more work to share in the new future on the blog! I currently have two papers I am working on with related topics, one with visualizing journey to crime flow data, and another paper with Emily Owens and Matthew Feedman of Cornell comparing journey to work data with journey to crime data.
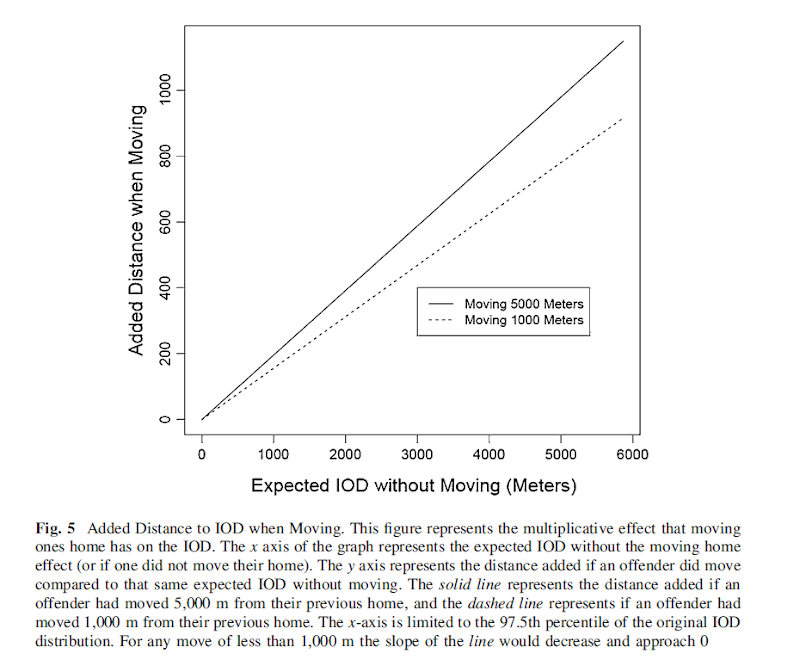
For a teaser for this paper here is the structured abstract from the paper and a graph demonstrating my estimated moving home effect.
Objectives
This study aims to test whether the home location has a causal effect on the crime location. To accomplish this the study capitalizes on the natural experiment that occurs when offender’s move, and uses a unique metric, the distance between sequential offenses, to determine if when an offender moves the offense location changes.
Methods
Using a sample of over 40,000 custodial arrests from Syracuse, NY between 2003 and 2008, this quasi-experimental design uses t test’s of mean differences, and fixed effects regression modeling to determine if moving has a significant effect on the distance between sequential offenses.
Results
This study finds that when offenders move they tend to commit crimes in locations farther away from past offences than would be expected without moving. The effect is rather small though, both in absolute terms (an elasticity coefficient of 0.02), and in relation to the effect of other independent variables (such as the time in between offenses).
Conclusions
This finding suggests that the home has an impact on where an offender will choose to commit a crime, independent of offence, neighborhood, or offender characteristics. The effect is small though, suggesting other factors may play a larger role in influencing where offenders choose to commit crime.