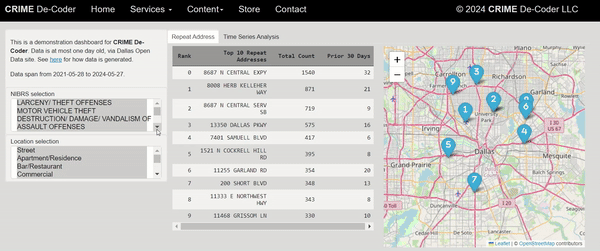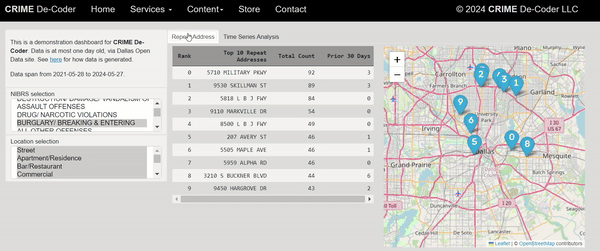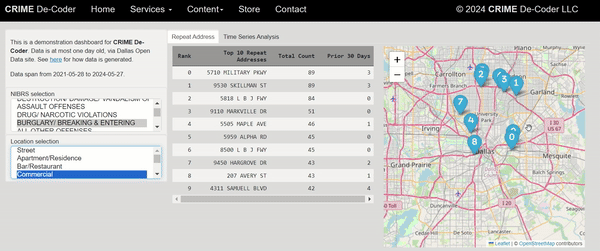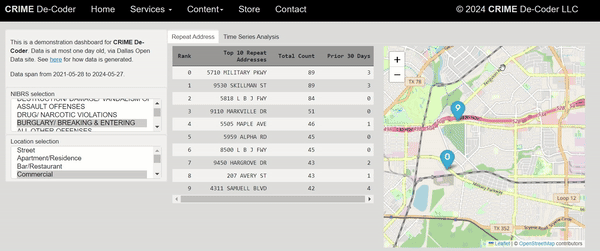
One of the ideas that has come up with the recent GenAI craze is to use these tools to conduct end-to-end data analysis. So you feed it a dataset + a question and out pops an analysis. Mike Zidar has notes on using a Google tool to do this:

I am not worried about these tools usurping crime analysts though. The reason is that the vast majority of data analysis (crime or business or whatever) is very superficial. The hardest part is not generating the chart, it is knowing what chart to generate, and how it will be used by real people to make real decisions. Often in crime analysis you get the ambiguous “well this will help allocate resources” – when in reality your chart can in no way help dictate any realistic decision a department is going to make.
If you cut out analysts, and just have front line individuals asking google “do crime analysis”, it will be hopelessly superficial, and the front line will just ignore it altogether.
I however do think that GenAI has the ability to become power-tools for super-users. That is, someone who does know what they want to calculate, but uses the computer to help them get that information faster. Not dissimilar to how auto-complete while texting helps you type faster. And here is one use case I have been thinking about – so analysts spend a ton of time automating different products, such as monthly CompStat reports. The reports should have tables/graphs in them, like this chart of gun crimes in DC for example:

Now, most reports you want to also have a plain text summary of what is going on in the chart. Currently when auto-generating reports, it is difficult to mix that plain text in and not make it very superficial using a rule based system. The newest round of many of the GenAI tools lets you upload an image and ask it questions about the image. So this is still very open ended, but has many more guiderails than simply telling the machine “go brr and generate analysis”. You have already decided the chart, you are just asking for a nice description of the chart to fill in your already pre-made metrics.
I did this with ChatGPT, Google’s Gemini, and Claude to see how it does with the gun crime chart, the below Raleigh weekly chart:

And in some cases a more tame monthly time series chart:


Because these models are changing all the time, keep in mind that when you read this the newest models may do even better than what I show here (and see the end section on how you may prompt engineer this to produce better results as well). That said lets check out the results!
ChatGPT
For ChatGPT I used the GPT-4o model, I first just asked about the DC chart “Describe the patterns in this chart”. ChatGPT as it is known, is quite verbose:


I then asked ChatGPT to keep it to two to three sentences, and I think it did very well.

Ok, now to the Raleigh chart with error bars:

So this is OK, it spotted the recent increasing trend. “Frequently exceeded the average of the prior 8 weeks (gray shaded area)” is wrong, there are only 2! But I think the last sentence about notable recent spikes is good.
I then gave it the Durham chart that had the anomalies in early 2019/2020:

And I again think this is quite reasonable. I mean an analyst should probably say “these must be reporting idiosyncrasies”, but I don’t think this is not so bad a description as to be misleading.
All in all very happy with the results for ChatGPT here – these charts are not typical line and bar charts, and ChatGPT interpreted each quite well. At least the description is not so bad that if I did these directly in an automated report it would be embarrassing.
Google
For all of these examples I am using the free tools (that typically have limits that I run out by just these two queries). I did this on 5/22 for Google (which I think is Gemini-1.5, I am not 100% sure). So here is the DC gun crime seasonal chart for Google with the prompt Describe the trends in this chart:

This is very wrong in multiple places. It did not do any better with the Raleigh chart:

There is not strong seasonality here, and it includes some filler “important to note” that is not actually important to note. After this I gave it a more tame monthly crime counts of Robberies in Houston chart to see if Google could redeem itself:

And it flopped pretty hard again. Maybe most charts are increasing, so the model is biased to say increasing (I don’t know).
So again this is Google’s free version, and so the paid may be better (or recent updates may be better). But this isn’t even close to make me want to prompt engineer further.
Claude
I did the tests with Sonnet 3.5 (so around a month after the tests with Google/ChatGPT). I used the shorter 2/3 sentences prompt.

I like this description even slightly better than ChatGPT. How about the Raleigh MV thefts chart:

Similar to ChatGPT it is not quite right but in very subtle ways. It does catch the upward trend. It is wrong in terms of data ends before 2024, and the gray area indicating greater variability is technically true but I would not describe it as noticeable. So again not embarrassingly wrong (like Google), but not quite right either.
How about the anomaly Durham chart:

Very similar to ChatGPT, which I think is again OK.
Prompt Engineering Ideas
So the idea behind prompt engineering is you can ask “Describe this chart” or you can ask “Describe this chart in two to three sentences” and it changes the results (in any of these tools). Subsequently a big part of this is figuring out the prompts that give the most reasonable results. Prompts in these GenAI tools when submitting images have two parts, the image and the text. Do not take me as an expert by any means, but for other analysts here are my guesses as to how to prompt engineer this to maybe return better results.
For the text part, one thing you may do for auto reports is to give examples of the text you want. So for example, you could have a prompt that is “Please fill in the blanks: The chart shows _____ trends over time.”. So provide more guidance as to the structure of how you want to the response to look. Or you could do: “Here is example description 1: …., description 2: ….”. This is how RAG applications work, but with a static report you can give static exemplars, they don’t really need to be dynamically looked up from prior reports.
For the image part of the prompt, in an auto-application you may submit a different image than is actually shown in the report. So for example I may have the X axis for monthly crimes be labeled with the actual months (instead of numbers). Putting all the months in smaller font I bet the GenAI tools will still read it just fine, even if I don’t want it to look like that in the final report.
And I probably shouldn’t include logos (since they are immaterial and just cause extra info that may distract the description), and the text footers. I also think making my legends more descriptive may help guide the tools interpretation. I may remove the title text all together and place the relevant info in the prompt “Here is a chart of Robberies in Houston from …. to … Please describe the chart, including any long term trends, or anomalous spikes (high or low) in any month.” The text prompt may keep the tools on track a bit more with the specific details, but still allow them leeway to interpret the chart without being too rigid.
For the error bar chart, you could insert into the prompt explicit dates they were outside, e.g. “weeks a and b were high, make sure to mention that”. So you could have a mix of explicit anomaly detection, insert those anomalies into the prompt, to just keep the results on track.
It would still be a lot of work to automate a report with such plain text language, but I think it could be a quite reasonable iterative workflow. So you generate the report in a format you can edit, like Word, review it. And then in subsequent reports try to tweak the parameters a wee bit to produce better outputs.