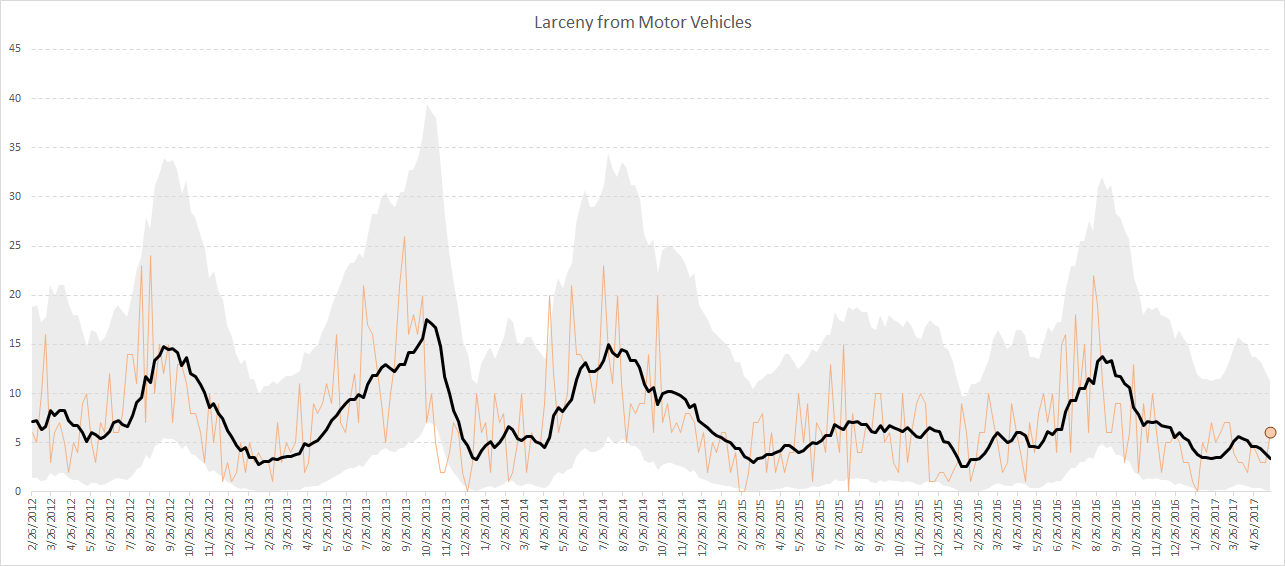
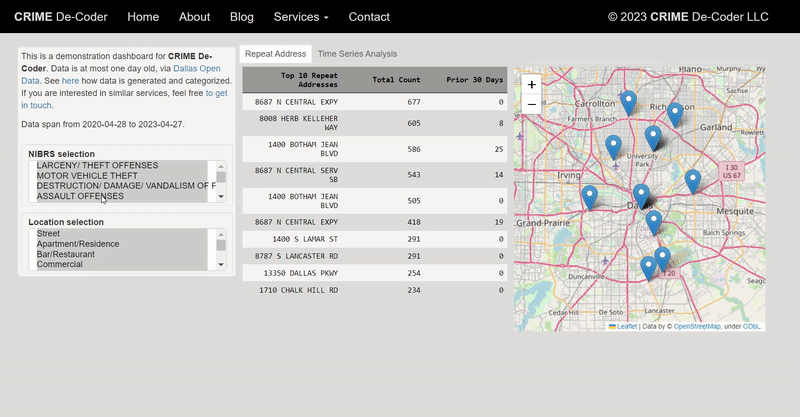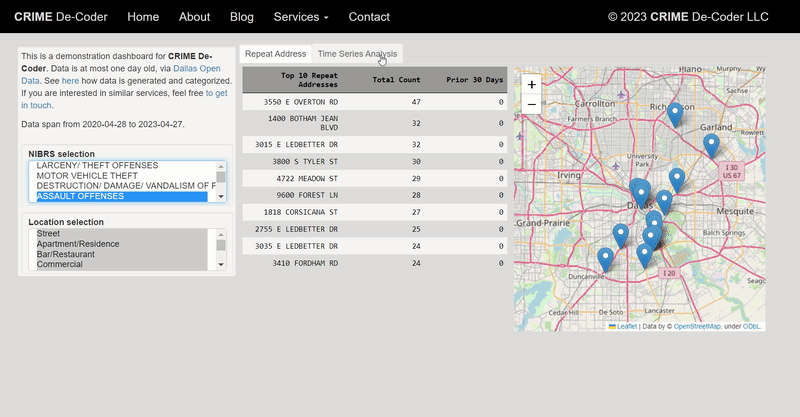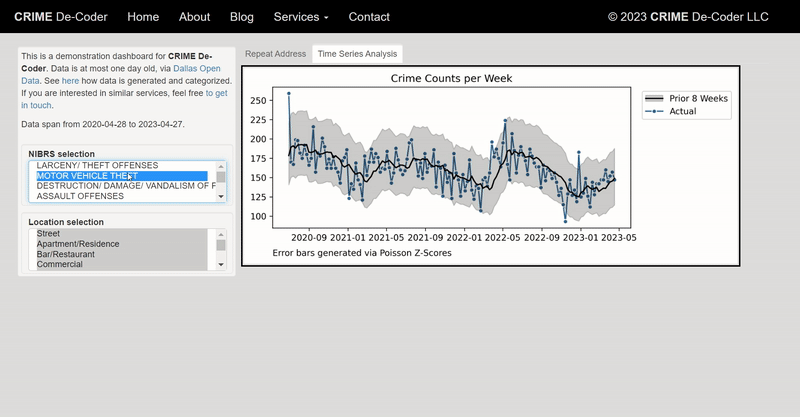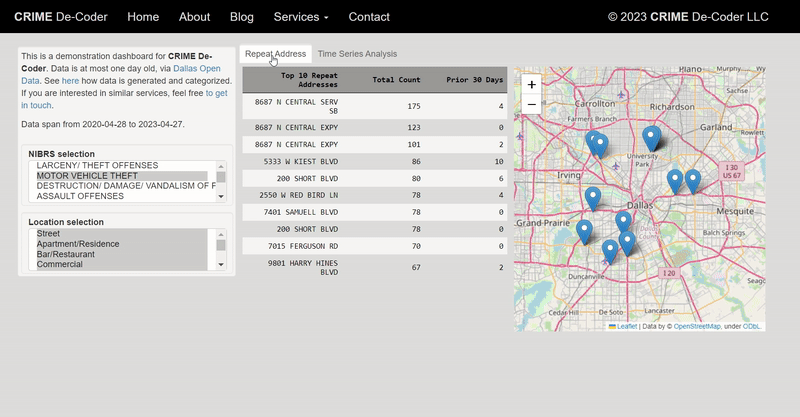
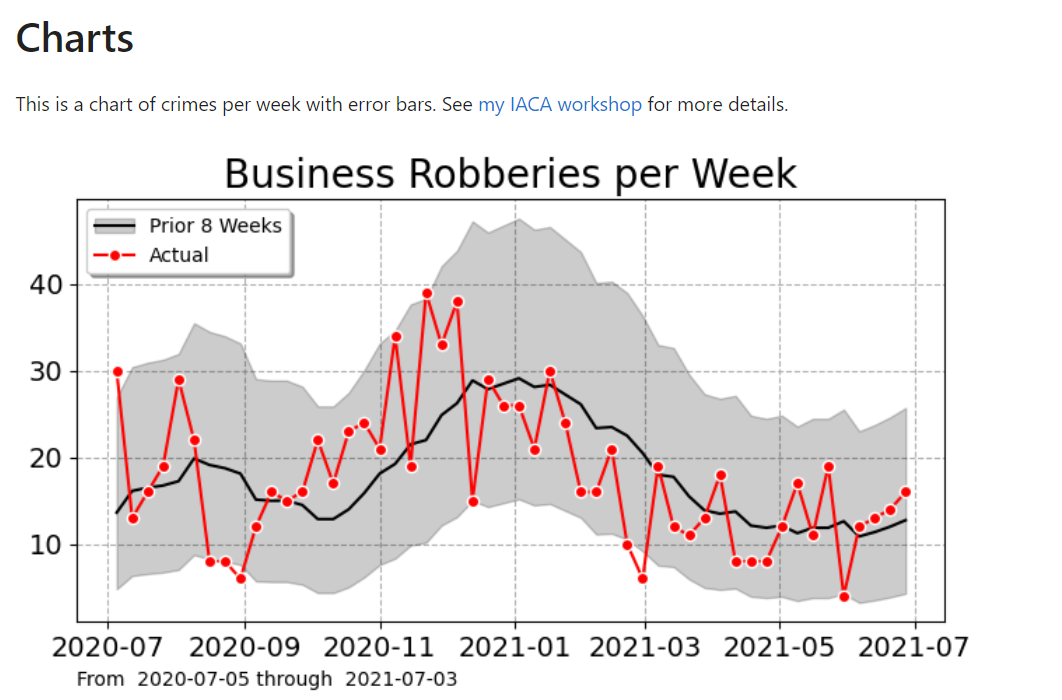
Recently for a crimede-coder project I have been building out a custom library to make nice leaflet maps using the python folium library. See the example I have posted on my website. Below is a screenshot:
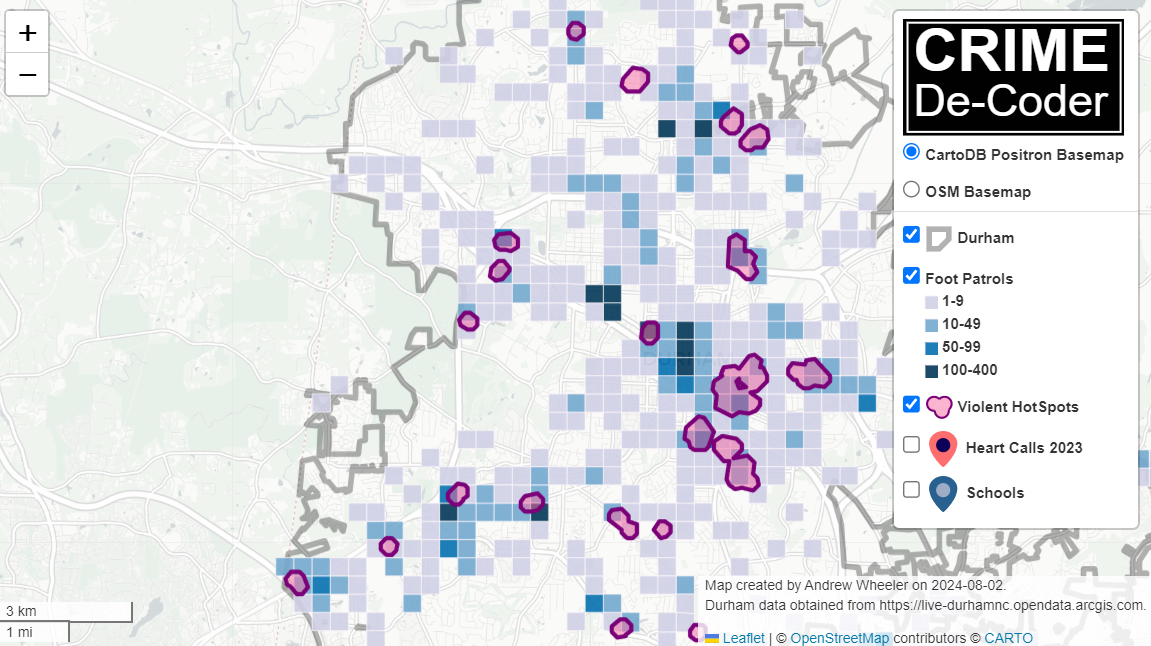
This map ended up having around 3000 elements in it, and was a total of 8mb. 8mb is not crazy to put on a website, but is at the stage where you can actually notice latency when first rendering the map.
Looking at the rendered html code though it was verbose in a few ways for every element. One is that lat/lon are in crazy precision by default, e.g. [-78.83229390597961, 35.94592660794455]. So a single polygon can have many of those. Six digits of precision for lat/lon is still under 1 meter of precision, which is plenty sufficient for my mapping applications. So you can reduce 8+ characters per lat/lon and not really make a difference to the map (you can technically have invalid polygons doing this, but this is really pedantic and should be fine).
A second part of the rendered folium html map for every object is given a full uuid, e.g. geo_json_a19eff2648beb3d74760dc0ddb58a73d.addTo(feature_group_2e2c6295a3a1c7d4c8d57d001c782482);. This again is not necessary. I end up reducing the 32 length uuids to the first 8 alphanumeric characters.
A final part is that the javascript is not minified – it has quite a bit of extra lines/spaces that are not needed. So here are my notes on using python code to take care of some of those pieces.
To clean up the precision for geometry objects, I do something like this.
import re
# geo is the geopandas dataframe
redg = geo.geometry.set_precision(10**-6).to_json()
# redg still has floats, below regex clips values
rs = r'(\d{2}\.|-\d{2}\.)(\d{6})(\d+)'
re.sub(rs,r'\1\2',redg)As most of my functions add the geojson objects to the map one at a time (for custom actions/colors), this is sufficient to deal with that step (for markers, can round lat/lon directly). It may make more sense for the set precision to be 10**-5 and then clip the regex. (For these regex’s I am showing there is some risk they will replace something they should not, I think it will be pretty safe though.)
Then to clean up the UUID’s and extra whitespace, what I do is render the final HTML and then use regex’s:
# fol is the folium object
html = fol.get_root()
res = html.script.get_root().render()
# replace UUID with first 8
ru = r'([0-9a-f]{8})[0-9a-f]{4}[0-9a-f]{4}[0-9a-f]{4}[0-9a-f]{12}'
res = re.sub(ru,r'\1',res)
# clean up whitespace
rl = []
for s in res.split('\n'):
ss = s.strip()
if len(ss) > 0:
rl.append(ss)
rlc = '\n'.join(rl)There is probably a smarter way to do this directly with the folium object for the UUID’s. For whitespace though it would need to be after the HTML is written. You want to be careful with the cleaning up the whitespace step – it is possible you wanted blank lines in say a leaflet popup or tooltip. But for my purposes this is not really necessary.
Doing these two steps in the Durham map reduces the size of the rendered HTML from 8mb to 4mb. So reduced the size of the file by around 4 million characters! The savings will be even higher for maps with more elements.
One last part is my map has redundant svg inserted for the map markers. I may be able to use css to insert the svg, e.g. something like in css .mysvg {background-image: url("vector.svg");}, and then in the python code for the marker svg insert <div class="mysvg"></div>. For dense point maps this will also save quite a few characters. Or you could add in javascript to insert the svg as well (although that would be a bit sluggish I think relative to the css approach, although sluggish after first render if the markers are turned off).
I have not done this yet, as I need to tinker with getting the background svg to look how I want, but could save another 200-300 characters per marker icon. So will save a megabyte in the map for every 3000-5000 markers I am guessing.
The main reason I post webdemo’s on the crimede-coder site is that there a quite a few grifters in the tech space. Not just for data analysis, but for front-end development as well. I post stuff like that so you can go and actually see the work I do and its quality. There are quite a few people now claiming to be “data viz experts” who just embed mediocre Tableau or PowerBI apps. These apps in particular tend to produce very bad maps, so here you can see what I think a good map should look like.
If you want to check out all the interactions in the map, I posted a YouTube video walking through them