
Jerry Ratcliffe, and now more recently Jeff Asher, have written about how volatile early year projection of year-to-date (YTD) percent changes. I am going to write about this is not the right way to frame the problem in my opinion – I will present a better behaved estimate that is less volatile, but clearly doesn’t give police departments what they want.
Going to the end advice first – people find me irksome for the suggestion, but you shouldn’t be using percent changes at all. A simple alternative I have stated for low count crime data is a Poisson Z-score, which is simply 2*(sqrt(Current) - sqrt(Past)) – a value of greater than 3 or 4 is a signal the two processes are significantly different (under the null hypothesis that the counts have a Poisson distribution).
A Better YTD estimate
So here I am going to present a more accurate YTD percent change metric – but don’t take that as advice you should be using YTD percent change. It is more of an exercise to say why you shouldn’t be using this metric to begin with. Year end percent change is defined as:
(Current - Past)/Past = % ChangeNote that you can rewrite this as:
Current/Past - Past/Past = % Change
Current/Past - 1 = % ChangeSo really it is only the ratio of Current/Past that we care about estimating, the translating to a percent doesn’t matter. In the above equations, I am writing these as cumulative totals for the whole year. So lets do breakdowns via subscripts, and shorten Current and Past to C and P respectively. So say we have data through January, people typically estimate the YTD percent change then as:
(C_January - P_January)/P_January = % Change JanuaryTo make it easier, I am going to write e subscript for early, and l subscript for later. So if we then estimate YTD for February, we then have C_January + C_February = C_e. Also note that C_e + C_l = Current, the early observed values plus the later unobserved values equals the year totals. This identifies a clear error when people use only subsets of the data to do YTD year end projections (what both Jerry and Jeff did in their posts to argue against early YTD estimates). You should not just use P_e in your estimate, you should use the full prior year counts.
Lets go back to our year end estimate, writing in early/later form:
[C_e + C_l - (P_e + P_l)]/(P_e + P_l) = % ChangeThis only has one unknown in the equation – C_l, the unknown rest of year projection. You should not use (C_e - P_e)/P_e, as this introduces several stochastic elements where none are needed. P_e is not necessarily a good estimate of P_e + P_l. So lets do a simple example, imagine we had homicide totals:
Past Current
Jan 2 1
Feb 0
Mar 1
Apr 1
May 1
Jun 1
Jul 1
Aug 1
Sep 1
Oct 1
Nov 1
Dec 1
---
Tot 12The naive way of doing YTD estimates, we would say our January YTD estimates are (1 - 2)/2 = -50%. Whereas I am saying, you should use (1 + C_l)/12 – filling in whatever value you project to the rest of the year totals C_l. Simple ones you can do in a spreadsheet are ‘no change’, just fill in the prior year which here would be C_l = 10, and would give a YTD percent change estimate of (11 - 12)/12 ~ -8%. Or another simple one is extrapolate, which would be C_l = C_e*(1/year_proportion) = 1*12, so (12 - 12)/12 = 0%. (You would really want to fit a model with seasonal and trend components and project out the remaining part of the year, which will often be somewhere between these two simpler methods.)
So far this is just theoretical “should be a better estimator” – lets show with some actual data. Python code to replicate here, but I took open data from Cary, NC, which goes back to 2000, so we have a sample of 22 years. Estimates of the error, broken down by month and version, are below. The naive estimate is how it is typically done (equivalent to Jeff/Jerry’s blog posts), the running estimate is taking prior to fill in C_l, and extrapolate is using the current months to fill in. The error metrics are | (estimated % change) - (actual year end % change) |, and the stats show the mean (standard deviation) of the sample (n=22). Here are the metrics for larceny, which average 123 per month over the sample:
Naive Running Extrapolate
Jan 12 (7) 6 (4) 10 (7)
Feb 8 (6) 6 (4) 11 (7)
Mar 9 (6) 5 (3) 8 (6)
Apr 9 (7) 5 (3) 8 (5)
May 7 (6) 5 (3) 6 (4)
Jun 6 (4) 4 (3) 4 (3)
Jul 5 (3) 4 (3) 4 (3)
Aug 4 (3) 3 (2) 3 (2)
Sep 3 (2) 3 (2) 2 (2)
Oct 2 (1) 2 (1) 2 (1)
Nov 1 (1) 1 (1) 1 (1)
Dec 0 (0) 0 (0) 0 (0)And here are the metrics for burglary, which average 28 per month over the sample. Although these have higher error metrics (due to lower/more volatile baseline counts), my estimator is still better than the naive one for the majority of the year.
Naive Running Extrapolate
Jan 34 (25) 12 (8) 24 (23)
Feb 15 (14) 11 (7) 16 (13)
Mar 15 (14) 12 (7) 15 (11)
Apr 15 (11) 10 (7) 13 ( 8)
May 14 (10) 10 (7) 10 ( 7)
Jun 11 ( 8) 10 (7) 8 ( 6)
Jul 9 ( 7) 9 (7) 7 ( 5)
Aug 7 ( 5) 8 (5) 6 ( 3)
Sep 6 ( 4) 6 (5) 4 ( 3)
Oct 6 ( 4) 5 (4) 3 ( 3)
Nov 3 ( 3) 3 (3) 2 ( 2)
Dec 0 ( 0) 0 (0) 0 ( 0)Running tends to do better for earlier in the year (and for smaller N samples). Both the running and extrapolate estimates are closer to the true year end percent change compared to the naive estimate in around 70% of the observations in this sample. (And tends to be even more pronounced in the smaller crime count categories, closer to 80% to 90% of the time better.)
In Jerry’s and Jeff’s posts, they use a metric +/- 5 to say “it is close” – this corresponds to in my tables absolute errors in the range of 5 percentage points. You meet that criteria on average in this sample for my estimator in March for Larcenies (running) and September (extrapolate) for Burglaries.
To be clear though, even with the more accurate projections, you should not use this estimate.
What do police departments want?
So Jeff may literally want an end-of-year projection for when he writes a Times article – similar to how a government might give a year end projection for GDP growth. But this is not what most police departments want when they calculate YTD metrics. So saying in turn “you shouldn’t use YTD because the error is high” to me misses the boat a bit. I can give a metric that has lower error rates, but you still shouldn’t use YTD percent change.
What police departments want to examine is the more general question “are my numbers high?” – you can further parse this into “are my numbers high consistently over the past date range” (of which the past year is just a convenient demarcation) or “are my numbers anomalous high right now”. The former is asking about long term trends, and the latter is asking about short term increases. Part of why I don’t like YTD is that it masks these two metrics – a spike early in the year can look like a perpetual long term upward trend later in the year.
I have training material showing off two different types of charts I like to use in lieu of YTD metrics. These can identify anomalous short term and long term trends. Here is an example weekly chart showing trends (in black line) and short term spikes (outside the error intervals):
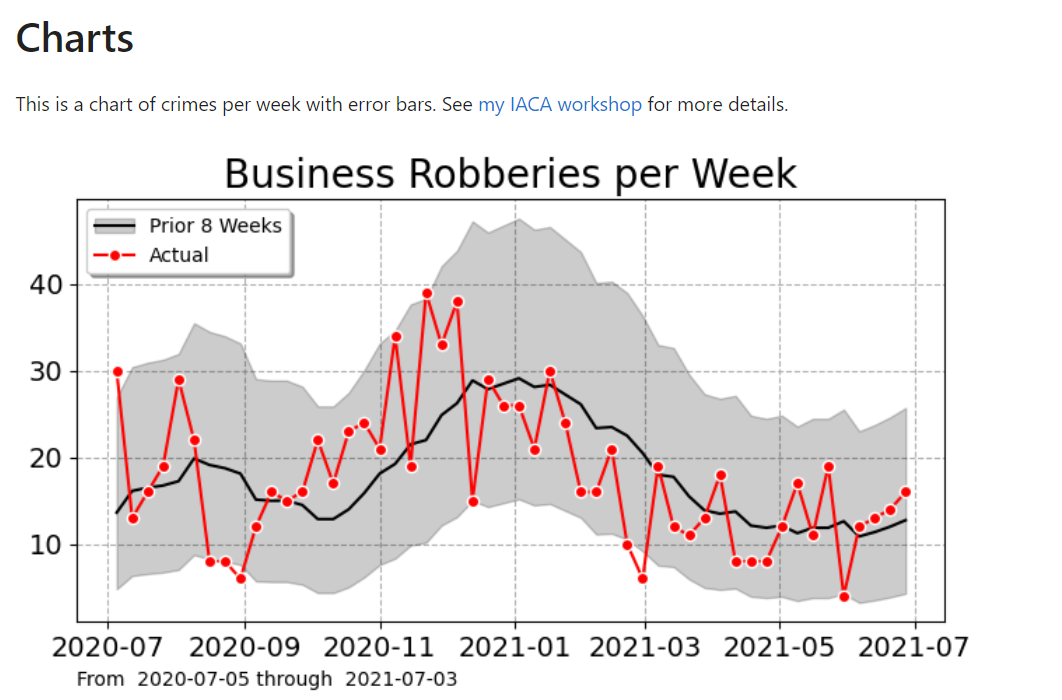
So this is an uber nerd post – I hope it has general lessons though. One is that if you need to estimate Y, and you can write Y as a function of other variables, some that are variable and some that are not, e.g. Y = f(x1,c), then maybe you should just focus on estimating x1 in this scenario, not model Y directly.
In terms of more general statistical modeling of crime trends, I have debated in the past examining more thoroughly seasonal-trend decomposition techniques, but I think the examples I give above are quite sufficient for most analysis (and can be implemented in a spreadsheet).

