I was recently re-reading the article The management of violence by police patrol officers (Bayley & Garofalo, 1989) (noted as BG from here on). In this article BG had NYPD officers (in three precincts) each give a list of their top 3 officers in terms based on minimizing violence. The idea was to have officers give self-assessments to the researcher, and then the researcher try to tease out differences between the good officers and a sample of other officers in police-citizen encounters.
BG’s results stated that the rankings were quite variable, that a single officer very rarely had over 8 votes, and that they chose the cut-off at 4 votes to categorize them as a good officer. Variability in the rankings does not strike me as odd, but these results are so variable I suspected they were totally random, and taking the top vote officers was simply chasing the noise in this example.
So what I did was make a quick simulation. BG stated that most of the shifts in each precinct had around 25 officers (and they tended to only rate officers they worked with.) So I simulated a random process where 25 officers randomly pick 3 of the other officers, replicating the process 10,000 times (SPSS code at the end of the post). This is the exact same situation Wilkinson (2006) talks about in Revising the Pareto chart, and here is the graph he suggests. The bars represent the 1st and 99th percentiles of the simulation, and the dot represents the modal category. So in 99% of the simulations the top ranked officer has between 5 and 10 votes. This would suggest in these circumstances you would need more than 10 votes to be considered non-random.
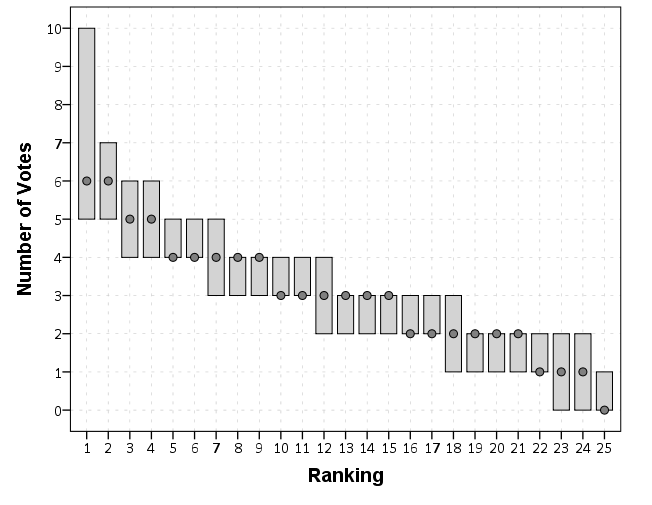
The idea is that while getting 10 votes at random for any one person would be rare, we aren’t only looking at one person, we are looking at a bunch of people. It is an example of the extreme value fallacy.
Here is the SPSS code to replicate the simulation.
***************************************************************************.
*This code simulates randomly ranking individuals.
SET SEED 10.
INPUT PROGRAM.
LOOP #n = 1 TO 1e4.
LOOP #i = 1 TO 25.
COMPUTE Run = #n.
COMPUTE Off = #i.
END CASE.
END LOOP.
END LOOP.
END FILE.
END INPUT PROGRAM.
DATASET NAME Sim.
*Now for every officer, choosing 3 out of 25 by random (without replacement).
SPSSINC TRANS RESULT = V1 TO V3
/FORMULA "random.sample(range(1,26),3)".
FORMATS V1 TO V3 (F2.0).
*Creating a set of 25 dummies.
VECTOR OffD(25,F1.0).
COMPUTE OffD(V1) = 1.
COMPUTE OffD(V2) = 1.
COMPUTE OffD(V3) = 1.
RECODE OffD1 TO OffD25 (SYSMIS = 0).
*Aggregating and then reshaping.
DATASET DECLARE AggResults.
AGGREGATE OUTFILE='AggResults'
/BREAK Run
/OffD1 TO OffD25 = SUM(OffD1 TO OffD25).
DATASET ACTIVATE AggResults.
VARSTOCASES /MAKE OffVote FROM OffD1 TO OffD25 /INDEX OffNum.
*Now compute the ordering.
SORT CASES BY Run (A) OffVote (D).
COMPUTE Const = 1.
SPLIT FILE BY Run.
CREATE Ord = CSUM(Const).
SPLIT FILE OFF.
MATCH FILES FILE = * /DROP Const.
*Quantile graph (for entire simulation).
FORMATS Ord (F2.0) OffVote (F2.0).
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=Ord PTILE(OffVote,99)[name="Ptile99"]
PTILE(OffVote,1)[name="Ptile01"] MODE(OffVote)[name="Mod"]
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: Ord=col(source(s), name("Ord"), unit.category())
DATA: Ptile01=col(source(s), name("Ptile01"))
DATA: Ptile99=col(source(s), name("Ptile99"))
DATA: Mod=col(source(s), name("Mod"))
DATA: OffVote=col(source(s), name("OffVote"))
DATA: Run=col(source(s), name("Run"), unit.category())
GUIDE: axis(dim(1), label("Ranking"))
GUIDE: axis(dim(2), label("Number of Votes"), delta(1))
ELEMENT: interval(position(region.spread.range(Ord*(Ptile01+Ptile99))), color.interior(color.lightgrey))
ELEMENT: point(position(Ord*Med), color.interior(color.grey), size(size."8"), shape(shape.circle))
END GPL.
***************************************************************************.