
A prior post on analyzing distances looked at geographic versus network (road) distances between zip codes in New York and one particular location. Over the large distances the correlation ended up being 0.99. But most crime analysis applications will be within one city, so restricting the distances there will the correlation be just as high? I conducted some analysis in Albany, NY to see if this was the case.
First I took a set of 2,640 street segments and intersections in Albany, defined as basically having over 1 reported crime between 2000 through 2013. (This is a pretty good proxy for places where people are actually located in the city, so places where people might actually travel from/to.) Here is a map of those points showing the coverage.
I then made the 2,640^2 pairs, and then took a random sample of 2,300 of those pairs to calculate the geographic versus the network distance (calculating the network distance using the google distance API). Here is a flow map, again showing it has pretty good coverage of the city.
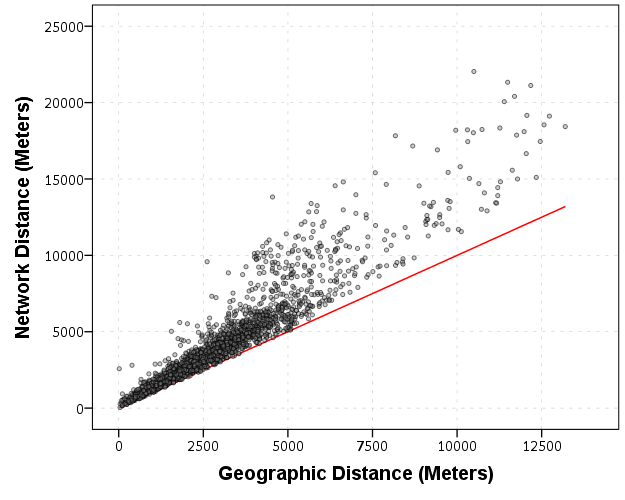
In this sample the correlation between the network distance and the geographic distance is 0.94, and below is the scatterplot. The red line is the line of equality, so we can see the network distance is always larger.
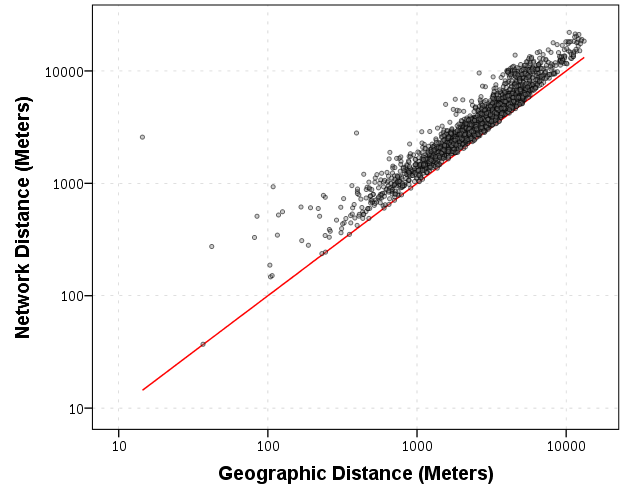
Making the graph on log scales basically takes away the heteroscedasticity, and shows some short distance outliers.
I then fit a regression of equation of log(Network Distance) ~ Intercept + b_0*log(Geo Distance), and then calculate the studentized residuals. Here is a small multiple flow map of those locations categorized by the truncated studentized residuals. I plotted flows under 200 meters as a red dot, as otherwise they basically have no area on the map to visualize. There are a few notable patterns, the -1 residuals (so closer network and geo distances) are locations along what looks like Central, Washington, Western and New Scotland (running east-west) and Broadway/Pearl (running north-south). So basically straight, major thoroughfares.
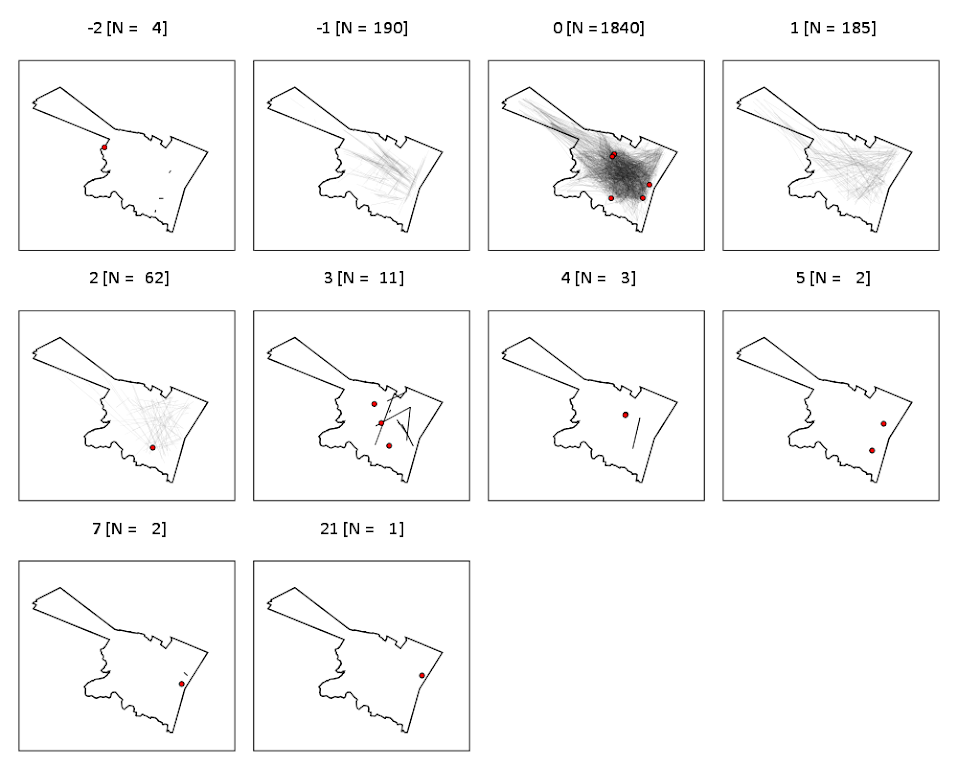
It is probable that if more locations in the isthmus and the south western part of the city were selected the distances would be not so nice, but the isthmus itself is largely the Pine Bush park, and the south western part is on the periphery of residential neighborhoods. Exporting the high residuals, what happens in the google distance API is that they are short trips on one way streets, and the to and from and going against the one way. I will have to investigate if you can set the google API to use walking distances to ignore this (as this wasn’t intended as a directed flow like that). Or just learn how to use the CrimeStat or network analysis in ArcMap distance calculation tools!
So although using network distances consistently increases the distances between points, they are still highly correlated, even for shorter in city patterns. If I fixed the flows going against one way streets it would likely be an even higher correlation.


1 Comment